MOCHA: Federated Multi-Tasks Learning (Virginia Smith)
The below is a transcript of a talk by Virginia Smith on MOCHA, at the ML Systems Workshop at NIPS'17.
The motivation for this work comes from the way we think about solving ML problems in practice is changing. The typical ML workflow looks like this. You start iwth dataset and problem to solve. Say you want to build a classifier to identify high quality news articles. Next step is to select an ML model to solve the problem. Under the hood, to fit the model to your data, you have to select an optimization algorithm. The goal is to find an optimal model that minimizes some function over your data.
In practice, there's a very important part of the workflow that is missing. For new datasets, interesting and systems, the system and properties of system, play a large role in the optimization algorithm we select to fix. To give an example, in the past several years, data that is so large that must be distributed over multiple machines, in a datacenter environment. I've been thinking about how to perform fast distributed optimization in this setting, when data is so large.
But more and more frequently, data is not coming nicely packaged in datacenter. It's coming from mobile phones, devices, distributed across country and globe. Training ML in this setting is challenging. For one, whereas in datacenter you have hundreds to thousands, here you have millions and billions. Also, in datacenter, devices are similar capability; here, you have phones that are old, low battery, not connected to wifi. This can change ability to perform computation at any given iteration.
Additionally, there's heterogeneity in data itself. For privacy and computation reasons, data can become very unbalanced in network. And it can be non-IID, so much so that there can be interesting underlying structure to the data at hand. I'm excited because these challenges break down into both systems and statistical challenges. The one second summary of this work, thinking about both systems and statistical in this federated setting; the punchline is that systems setting plays a role not only in optimization algorithm but also the model we select to fit. IT plays a more important role in this overall workflow.
I'm going to go through how we holistically tackle systems and statistical challenges.
Starting with statistical. The goal is we have a bunch of devices generating data, could be unbalanced; some devices have more data than others. One approach used in past is fit a single model across all of this data. All of the data can be aggregated; you find one model that best achieves accuracy across all of the data simultaneously. The other extreme is you find a model for each of the data devices, and not share information. From systems point of view this is great, but statistically, you might have devices that are only ... that are poor in practice. What we're proposing is something between these two extremes. We want to find local models for each device, but share information in a structured way. This can be captured in a framework called multitask learning.
The goal is to fit a separate loss function for each device. These models can be aggregated in this matrix W, and the function of the regularizer, is to force some structure omega on it. This omega is a task relationship matrix, capturing interesting relationships, e.g., all the tasks are related and you want to learn weights, or most of the tasks are related and there are a few outliers, or there are clusters and groups, or there are more sophisticated relationships like asymmetric relationships. These can all be captured in multitask.
We developed a benchmarking set of real federated data. This includes trying to predict human activity from mobile phone, predict if eating or drinking, land mine, and vehicle sensor; distributed sensor to determine if a vehicle is passing by.
For these various datasets, we compared global, local and MTL. The goal is to fit a SVD model. For each data set, we looked at the average error across tasks, where each model is a task. What you can see is average error, for SVD, is significantly lower than global and local approaches. This makes sense because MTL is much more expressive; it lets you go between these extremes. What's interesting is that in these real data sets, it really helps. Reduction by half. This is a significant improvement in practice.
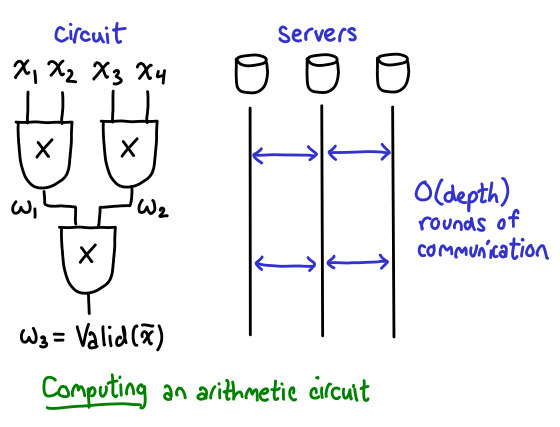
Given that we like to be using multitask learning to model data in federated environment, the next problem is figure out how to train this in distributed setting, thinking about massive distributed. In particular, the goal is to solve the following optimization objective. In looking how to solve this objective, we note that it's often common to solve for W and omega in an alternating fashion. When you solve for omega, it's centrally, you just need access to models. But W must be distributed because data is solved across devices. The key component how to solve this in practice is the W update. The challenge of doing this is communication is extremely expensive. And because of heterogeneity, you may have massive problems with stragglers and fault tolerance; e.g., someone who turns their phone off.
The high level idea for how we're doing this, take a communication efficient method that works well in data center, and modify it to work in federated setting. It will handle MTL as well as stragglers and fault tolerance.
What is the method we're using? The method we're using is COCOA, which is a state of the art method for empirical risk minimization problems. The thing that's nice about COCOa is it spans prior work of mini-batch and one-shot communication, by making communication a first class parameter of the method. Make it flexible as possible. It does it by not solving the primal formulation, but the dual. The dual is nice because we can easily approximate it by forming a quadratic approximation to the objective; and this more easily decomposes across machines.
To distribute this to federate setting, a key challenge is figuring out how to generalize it to the MTL framework. A second challenge; in COCOA, the subproblems are assumed to be solved to some accuracy theta. This is nice because theta varies from 0 to 1, where 0 is exact solve, and 1 is inexact. This can be thought of as how much time you do local communication versus communication. However, in fact, this is not as flexible as it should be in the federated setting. There is only one theta that is set for all iterations, a ll nodes. And because theta cannot be set exactly to one, it cannot handle fault tolerance, where there's no work performed at any iteration. Making this communication parameter much more flexible in practice.
JHow are we doing this? we developed MOCHA. The goal is to solve multitask learning framework; W and Omega in an alternating fashion. In particular, we're able to form the following dual formulation, similar to COCOA, so it decomposes. In comparison, we make this much more flexible assumption on subproblem parameter. This is important because of stragglers: statistical reasons, unbalance, different distributions, it can be very different in how difficult it is to solve subproblems. Additionally, there can be stragglers due to systems issues. And issues of fault tolerance. So this looks like a simple fix: we make this accuracy parameter more flexible: allow it to vary by node and iteration t, and let it be exactly 1. The hard thing is showing it converges to optimal solution.
Following this new assumption, and you can't have a device go down every single round, we show the following convergence guarantee. For L-Lipschitz loss, we get a convergence at 1/epsilon; for smooth models (logistic regression) we get a linear rate.
How does this perform in practice? The method is quite simple. The assumption is we have data stored at m different devices. We alternate between solving Omega, and W stored on each. While we're solving w update, it works by defining these local subproblems for machines, and calling solver that does approximate solution. This is flexible because it can vary by node and iteration.
In terms of comparing this to other methods, what we've seen is the following. Comparing MOCHA to CoCoA, compared to Mb-SDCA and Mb-SGD. We had simulation, with real data to see what would happen if we do it on wifi. We have simulated time and how close are to optimal. What you can see is that MoCHA is converging much more quickly to optimal solution, because MoCHA doesn't have the problem of statistical heterogeneity, and it's not bogged down by stragglers. This is true for all of the different types of networks; LET and 3G. The blue line and MOCHA and CoCOA, they work well in high communication settings, because they are more flexible. But compared to CoCOA, MOCHA is much more robust to statistical heterogeneity.
What's interesting is that if we impose some systems heterogeneity, some devices are slower than others, we looked at imposing low and high systems heterogeneity, MOCHA with this additional heterogeneity, it's a two orders of magnitude speedup to reach optimal solution.
And for MOCHA in particular, we looked at issue of fault tolerance. What we're showing here, we're increasing the probability a device will drop out at any distribution. Going up until there's half devices, we're still fairly robust to MOCHA converging, in almost the same amount of time. But what we see with green dotted line, of the same device drops out every iteration, it doesn't converge. This shows the assumption we made makes sense in practice.
The punchline is that in terms of thinking this new setting, training ML on these massive networks of devices, this is both a statistical and systems issue. We've addressed it in a holistic matter. Code at http://cs.berkeley.edu/~vsmith I also want to reiterate about SysML conference in February.
Q: When you compare global and local? Why is it always better than global?
A: The motivation why you want to use local model over global model, is that if you have a local data a lot, you might perform better. It boosts the overall sample size. I have some additional experiments where we took the original data, and skewed it even further than it already was. We took the local data, and there was less data locally, and they have global approaches. That's just a function of the data in the devices.
Q: I really like how your method has guarantees, but I'm wondering about an approach where you create a metalearning algorithm locally and have it work locally?
A: That's worth looking into empirically, since you can do fine tuning locally. What we were trying to do first was converge to exact optimal solution, but you might want to just work empirically well, would be good to compare to this setting.
![[x]_i](http://s0.wp.com/latex.php?latex=%5Bx%5D_i&bg=ffffff&fg=000000&s=0 "[x]_i") and
and ![[y]_i](http://s0.wp.com/latex.php?latex=%5By%5D_i&bg=ffffff&fg=000000&s=0 "[y]_i") : then
: then ![[x]_i + [y]_i](http://s0.wp.com/latex.php?latex=%5Bx%5D_i+%2B+%5By%5D_i&bg=ffffff&fg=000000&s=0 "[x]_i + [y]_i") form secret shares of x + y, since addition in a field is commutative (so I can reassociate each of the pairwise sums into the sum for x, and the sum for y.)
form secret shares of x + y, since addition in a field is commutative (so I can reassociate each of the pairwise sums into the sum for x, and the sum for y.)