Semi-automatic testing
When programmers automate something, we often want to go whole-hog and automate everything. But it’s good to remember there’s still a place for manual testing with machine assistance: instead of expending exponential effort to automate everything, automate the easy bits and hard-code answers to the hard research problems. When I was compiling the following graph of sources of test data, I noticed a striking polarization at the ends of "automated" and "non-automated."
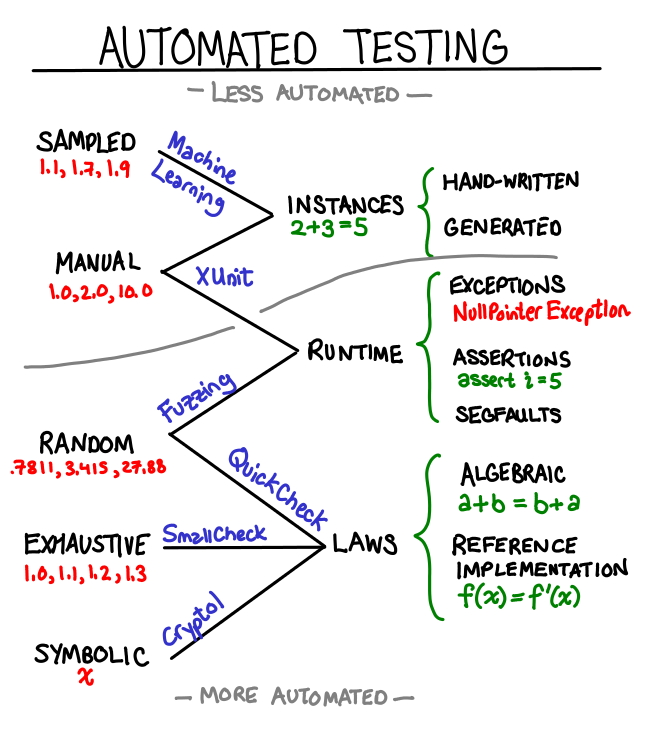
An ideal test framework would support combining all of these data sources and all of these testing mechanisms. Some novel approaches include:
- Randomly generated test-cases with manual verification. Obviously you won’t be able to hand verify thousands of test-cases, but a few concrete examples can do wonders for documentation purposes, and random generation prevents us from only picking “nice” inputs.
- Reference implementation as previous version of the code. To the limit, you automatically accept the output of an old implementation and save it to your test suite, and when a test starts failing you the framework asks you to check the output, and if it’s “better” than before you overwrite the old test data with the new. GHC’s test suite has something along these lines.
- You’ve written lots of algebraic laws, which you are using Quickcheck to verify. You should be able to swap out the random generator with a deterministic stream of data from a sampled data source. You’d probably want a mini-DSL for various source formats and transforming them into your target representation. This also works great when you’ve picked manual inputs, but exactly specifying the output result is a pain because it is large and complicated. This is data-driven testing.
- Non-fuzzing testing frameworks like Quickcheck and Smallcheck are reasonably good at dealing with runtime exceptions but not so much with more critical failures like segmentation faults. Drivers for these frameworks should take advantage of statelessness to notice when their runner has mysteriously died and let the user know the minimal invocation necessary to reproduce the crash—with this modification, these frameworks subsume fuzzers (which are currently built in an ad hoc fashion.)
It would be great if we didn’t have to commit to one testing methodology, and if we could reuse efforts on both sides of the fence for great victory.