Static Analysis for everyday (not-PhD) man
Bjarne Stroustrup once boasted, "C++ is a multi-paradigm programming language that supports Object-Oriented and other useful styles of programming. If what you are looking for is something that forces you to do things in exactly one way, C++ isn't it." But as Taras Glek wryly notes, most of the static analysis and coding standards for C++ are mostly to make sure developers don't use the other paradigms.
On Tuesday, Taras Glek presented Large-Scale Static Analysis at Mozilla. You can watch the video at Galois’s video stream. The guiding topic of the talk is pretty straightforward: how does Mozilla use static analysis to manage the millions of lines of code in C++ and JavaScript that it has? But there was another underlying topic: static analysis is not just for the formal-methods people and the PhDs; anyone can and should tap into the power afforded by static analysis.
Since Mozilla is a C++ shop, the talk was focused on tools built on top of the C++ language. However, there were four parts to static analysis that Taras discussed, which are broadly applicable to any language you might perform static analysis in:
- Parsing. How do you convert a text file into an abstract representation of the source code (AST)?
- Semantic grep. How do you ask the AST for information?
- Analysis. How do you restrict valid ASTs?
- Refactoring. How do you change the AST and write it back?
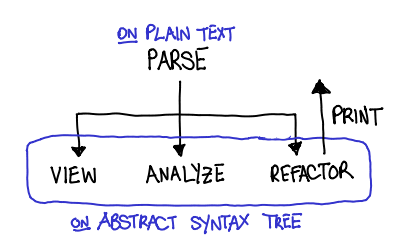
Parsing. Parsing C++ is hard. Historically this is the case because it inherited a lot of syntax from C; technically this is the case because it is an extremely ambiguous grammar that requires semantic knowledge to disambiguate. Taras used Elsa (which can parse all of Mozilla, after Taras fixed a bunch of bugs), and awaits eagerly awaits Clang to stabilize (as it doesn't parse all of Mozilla yet.) And of course, the addition of the plugin interface to GCC 4.5 means that you can take advantage of GCC's parsing capabilities, and many of the later stage tools are built upon that.
Semantic grep. grep is so 70's! If you're lucky, the maintainers of your codebase took care to follow the idiosyncratic rules that make code "more greppable", but otherwise you'll grep for an identifier and get pages of results and miss the needle. If you have an in-memory representation of your source, you can intelligently ask for information. Taken further, this means better code browsing like DXR.
Consider the following source code view. It's what you'd expect from a source code browser: source on the right, declarations on the left.
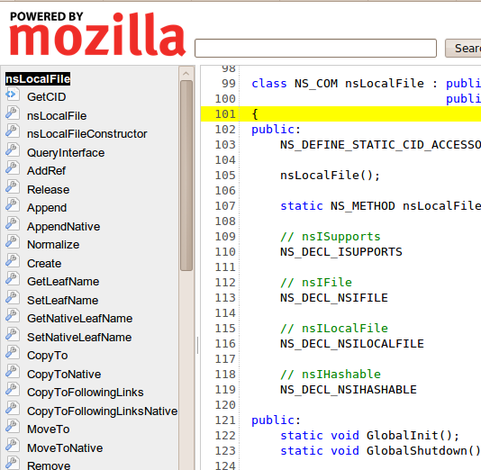
Let's pick an identifier from the left, let's say CopyTo. Let's first scroll through the source code and see if we can pick it out.
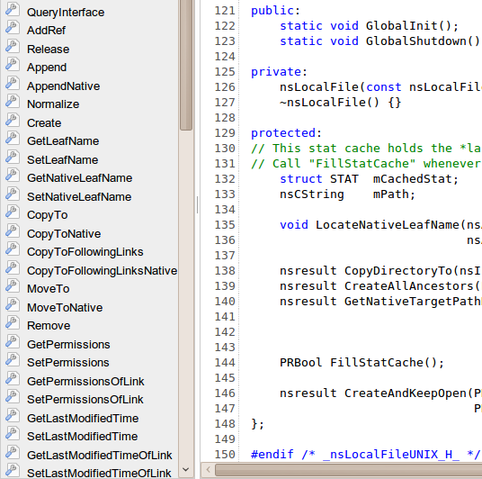
Huh! That was a really short class, and it was no where to be found. Well, let's try clicking it.
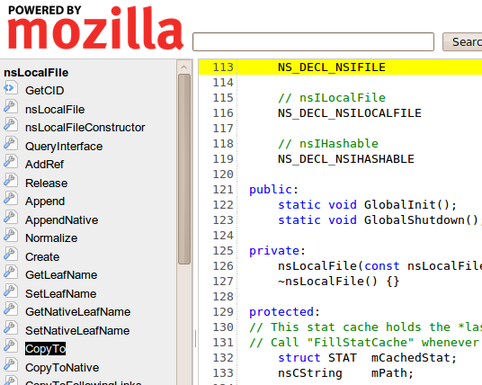
Aha! It was in the macro definition. The tool can be smarter than the untrained eye.
Analysis. For me, this was really the flesh of the talk. Mozilla has a very pimped out build process; hooking into GCC with Dehydra and Treehydra. The idea behind the Dehydra project is to take the internal structures that GCC provides to plugins, and convert them into a JSON-like structure (JSON-like because JSON is acyclic but these structures are cyclic) that Dehydra scripts, which are written in JavaScript can be run on the result. These scripts can emit errors and warnings, which look just like GCC build errors and warnings. Treehydra is an advanced version of Dehydra, that affords more flexibility to the analysis script writer.
So, what makes Dehydra/Treehydra interesting?
- JavaScript. GCC's plugin interface natively supports C code, which may be intimidating to developers with no static analysis experience. Porting these structures to JavaScript means that you get a high-level language to play in, and also lets you tell Junior developers without a lick of static analysis experience, "It's just like hacking on a web application." It means that you can just print out the JSON-like structure, and eyeball the resulting structure for the data you're looking for; it means when your code crashes you get nice backtraces. Just like Firefox's plugin interface, Dehydra brings GCC extensions to the masses.
- Language duct tape. I took a jab at Stroustrup at the beginning of his post, and this is why. We can bolt on extra language features like final for classes (with attributes, __attribute__((user("NS_final"))) wrapped up in a macro NS_FINAL_CLASS) and other restrictions that plain C++ doesn't give you.
- Power when you need it. Dehydra is a simplified interface suitable for people without static analysis or compiler background; Treehydra is full-strength, intended for people with such backgrounds and can let you do things like control-flow analysis.
All of this is transparently integrated into the build system, so developers don't have to fumble with an external tool to get these analyses.
Refactoring. Perhaps the most ambitious of them all, Taras discussed refactoring beyond the dinky Extract method that Java IDEs like Eclipse give you using Pork. The kind of refactoring like "rewrite all of Mozilla to use garbage collection instead of reference counting." When you have an active codebase like Mozilla's, you don't have the luxury to do a "stop all development and start refactoring...for six years" style refactoring. Branches pose similar problems; once the major refactoring lands on one branch, it's difficult to keep the branch up-to-date with the other, and inevitably one branch kills off the other.
The trick is an automated refactoring tool, because it lets you treat the refactoring as "just another patch", and continually rebuild the branch from trunk, applying your custom patches and running the refactoring tool to generate a multimegabyte patch to apply in the stack.
Refactoring C++ is hard, because developers don't just write C++; they write a combination of C++ and CPP (C pre-processor). Refactoring tools need to be able to reconstruct the CPP macros when writing back out, as opposed to languages like ML which can get away with just pretty-printing their AST. Techniques include pretty-printing as little as possible, and forcing the parser to give you a log of all of the pre-processor changes it made.
Open source. Taras left us with some words about open-source collaboration, that at least the SIPB crowd should be well aware of. Don't treat tools you depend on black boxes: they're open-source! If you find a bug in GCC, don't just work around it, check out the source, write a patch, and submit it upstream. It's the best way to fix bugs, and you score instant credibility for bugs you might submit later. There is a hierarchy of web applications to browsers, browsers to compilers, compilers to operating systems. The advantage of an open-source ecosystem is that you can read the source all the way down. Use the source, Luke.