Databases are categories
June 4, 2010Update. The video of the talk can be found here: Galois Tech Talks on Vimeo: Categories are Databases.
On Thursday Dr. David Spivak presented Categories are Databases as a Galois tech talk. His slides are here, and are dramatically more accessible than the paper Simplicial databases. Here is a short attempt to introduce this idea to people who only have a passing knowledge of category theory.
An essential exercise when designing relational databases is the practice of object modeling using labeled graphs of objects and relationships. Visually, this involves drawing a bunch of boxes representing the objects being modeled, and then drawing arrows between the objects showing relationships they may have. We can then use this object model as the basis for a relational database schema.
An example model from a software engineering class is below:
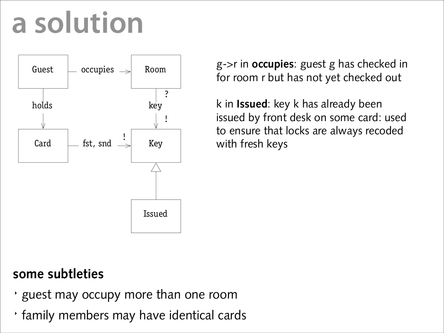
With the image of a object model in your head, consider Wikipedia’s definition of a category:
In mathematics, a category is an algebraic structure consisting of a collection of “objects”, linked together by a collection of “arrows” that have two basic properties: the ability to compose the arrows associatively and the existence of an identity arrow for each object.
The rest of the definition may seem terribly abstract, but hopefully the bolded section seems to clearly correspond to the picture of boxes (objects) and arrows we drew earlier. Perhaps…
Database schema = Category.
Unfortunately, a directed graph is not quite a category; the secret sauce that makes a category a category are those two properties on the arrows, associative composition and identity, and if we really want to strengthen our claim that a schema is a category, we’ll need to demonstrate these.
Recall that our arrows are “relations,” that is, “X occupies Y” or “X is the key for Y”. Our category must have an identity arrow, that is, some relation “X to X”. How about, “X is itself X”, an almost vacuous statement, but one most certainly true. Identity arrow, check.
We also need to show associative composition of arrows. Composition of two arrows is much like they showed you when they were teaching you vector algebra: you take the head of one arrow (X to Y) and smush it with the tail of another (Y to Z), and you get another arrow (X to Z). If a “book has an author” and “an author has a favorite color”, I can say “the book’s author has a favorite color”. This composed statement doesn’t care who the author was… just what his favorite color is. In fact,
Arrow composition = Joins
That is, one of the fundamental features of a category, a feature that any nice result from pure category theory uses as if it were intuitively obvious, is one of the very techniques that does not seem obvious to someone reading about JOINs in the second half of a database tutorial.
(Aside. A foreign key relationship is intrinsically many to one: a foreign key field can only point to one record in another table, but many rows can have that field pointing to the same record. When doing relational modeling, we will frequently use many-to-many or one-to-many relationships. Any database administrator knows, however, that we can simply rewrite these into many to one relationships (reversing the arrow in the case of one-to-many and introducing a new table for many-to-many).)
When we have a schema, we also want to have data to fill the schema. As it turns out, this also fits into a category-theoretic framework too, although a full explanation is out of scope for this post (I suggest consulting the slides.)
Functor (C -> S) = data
Why do you care? There are some good reasons mentioned by Spivak:

I’ll mention one of my own: SQL, while messy, is precise; it can be fed into a computer and turned into a databases that can do real work. On the other hand, relational models are high level but kind of mushy; developers may complain that drawing diagrams with arrows doesn’t seem terribly rigorous and that the formalism doesn’t really help them much.
Category theory is precise; it unambiguously assigns meaning and structure to the relations, the laws of composition define what relations are and aren’t permissible. Category theory is not only about arrows (if it was it’d be pretty boring); rather, it has a rich body of results from many fields expressed in a common language that can “translated” into database-speak. In many cases, important category theory notions are tricky techniques in database administrator folklore. When you talk about arrows, you’re talking a lot more than arrows. That’s powerful!
Two of my favorite things are SQL and Haskell. The thought of bringing them closer together makes me pretty excited and I hope to hear more about this as time goes on.
I did want to take exception to the Coherence notion there. A lesson I took away from database design class was that databases are necessarily an abstraction and that they must necessarily omit some information. They’re a model of reality. A concrete example would be, suppose I’m making a travelogue database. We may agree that the standard for storing hotel information is the one in the slide above, but am I really going to want to link my table for storing notes about places I’ve visited to the Issued table? It would certainly be more precise than, say, a string for the hotel’s name, and it embodies more information, but in practice it will almost certainly always get in the way.
Part of the reason databases are incompatible with each other is because real world entities are a complex fusion of immutable physical properties, properties defined by use, emergent properties derived from physical properties, law, location, time as well as even fuzzier notions like emotional attachments. Having standards for various types of information can help with interoperability but there is no cure. Returning to the travelogue concept, suppose I want to keep a log of what I read on my trips as well. The standard identifier for books is ISBN numbers. But what if I find and read a crusty old manuscript under the hotel bed? For my purposes, a title is probably sufficient identification–am I going to make up an ISBN number for books that don’t have one, or bother looking them up for books that do have them for that matter? Alternatively, am I going to live with having a bunch of nulls in my tables? It would be a different story if I were simply selling books online–then I would only care about books that have ISBN numbers and can be ordered. Standards for information exchange may make easy problems easier but they rarely reduce the database designer’s task when working on novel scenarios.
This article is totally wrong, from its start. It assumes the relational model is about relations between objects. This is a total misunderstanding of it. The relational model is about relations, that is, subsets of the cartesian product of n domains.
In other words, relational databases are about set theory and predicate logic, not about graphs.
xi, it depends on what you mean by “multi-column” unique key. If you mean multiple columns which form a primary key, you simply treat those columns as forming a tuple which is the primary key. If you mean another column with a uniqueness constraint, you can model this by having an arrow going from one table (with the “primary key”) and another table (with the unique key as its “primary key”). They’re isomorphic, and there’s no problem with duplication since all of the arrows compose appropriately.
Daniel, you raise a valid point. One of the biggest pains that dbadmins have to deal with are schema upgrades; they invariably are difficult to construct, messy to deploy, and generally something that you like to avoid. In fact, a database upgrade (schema and data), or in fact an arbitrary transition from one format to another, is merely a natural transformation! I’ll admit, I haven’t worked out all of the implications yet, but it suggests a very clean language for discussing what is traditionally a very grungy process.
Anonymous, one of the results that Spivak demonstrates in his slides is that I can construct a graph database out of any relational database! (He uses the Grothendieck construction, which is a pure category-theoretic result, but if you just think about the problem a little bit, you’ll probably see an almost trivial way to do it.)
Dave, SQL is indeed strikes me as a very un-category-theoretic notion. This may be because it is highly concerned with what is stored inside the database, while category theory tends to concern itself with the structure of the database.
Leandro, you are correct to say that the underlying mathematics of relational modeling are founded first-order predicate logic. Perhaps it would have been more accurate to talk about the practice as “domain modeling.” Still, I don’t think it’s fair for you to dismiss the entire post on a terminology dispute. I will note that set theory and deductive logic both have strong foundings in category theory; in particular, we often find it instructive for the intuition to a category back into the realm of sets and functions.
Nice ideas… oddly enough, I recently did something like this in one of my recent projects. I sketched an ontology for describing database queries against the data contained in a heavily normalized database. The queries are modeled using simple entities and properties, and mapped to SQL when executed. The map layer knows how to join the normalized tables to get the required fields out, but the query objects are blissfully ignorant of the actual normalized schema. Just hadn’t really thought about it in these terms before - I figured it was just all the work I’ve been doing lately with RDF and the Semantic Web influencing my frame of mind.
I am with Leandro, though - you should really read up on what “relational” means in the term “relational database”. You’re certainly not alone in your misuse of the terminology, though.
Unless I’m missing something (which is possible as I’m slightly rusty), the category you describe is the one usually called ‘Rel’ (technically a full sub-category of it). Rel is quite well-studied:
http://en.wikipedia.org/wiki/Category_of_relations
More interesting would be a category whose objects themselves are n-ary relations, and whose structure reflected the logical structure of the relational algebra
One way you could get such a category is by treating the relational algebra an alternative formulation of multi-kinded first-order logic, and taking the category of that logic with objects as propositions and morphisms as proofs.
This looks really interesting and motivates me to learn category theory better.
I dont think all the criticisms are fair, mostly Leandros. Author choose to describe databases through a certain lens. Yes, relations, relational algebra, sets, and logic are a more formal way of describing a relational database. But I don’t see any reason these wouldn’t be just as applicable to set theory. Spivak’s slides seem to suggest that. Author just wrote an informal summary/teaser and i think he did a good job at that.
PS - Ministry, I would love to read your blog but it is private. would you share info?
I believe Leandro to be unfair, and his argument is largely one of semantics. This is usually the type of thing you get from an undergrad who still thinks everyone speaks in the same language.
I’ve done my own research into applying categories to a balanced binary tree in Haskell, and I’ve come up with a very similar formulation as described in Spivak’s lecture. Handling unique vs foreign keys becomes a little trickier, but it’s something that can be solved with clever use of a State Monad and high order functions.
Most of the links in this post are dead!
I made a post amending this: http://kyle.marek-spartz.org/posts/2014-02-19-databases-are-categories.html