July 26, 2010For when the Reader monad seems hopelessly clunky
The Reader monad (also known as the Environment monad) and implicit parameters are remarkably similar even though the former is the standard repertoire of a working Haskell programmer while the latter is a GHC language extension used sparingly by those who know about it. Both allow the programmer to code as if they had access to a global environment that can still change at runtime. However, implicit parameters are remarkably well suited for cases when you would have used a stack of reader transformers. Unfortunately, unlike many type system extensions, GHC cannot suggest that you enable ImplicitParams because the code you innocently wrote is not valid Haskell98 but would be valid if you enabled this extension. This post intends to demonstrate one way to discover implicit parameters, with a little nudging.
Reader monad in practice. The Reader monad is really quite simple: after all, it is isomorphic to (->) r, the only real difference being a newtype. Because of this, in engineering contexts, it is rarely used as-is; in particular:
- It is used as a transformer, endowing an “environment” to whatever application-specific monad you are building, and
- It is used with a record type, because an environment of only one primitive value is usually not very interesting.
These choices impose some constraints on how code written for a Reader monad can be used. In particular, baking in the environment type r of ReaderT r means that your monadic code will not play nicely with some other monadic code ReaderT r2 without some coaxing; additionally, I can’t build up a complicated record type Record { field1 :: Int; field2 :: String; field3 :: Bool} incrementally as I find out values of the environment. I could have my record type be a map of some sort, in which case I could place arbitrarily values in it, but in this case I have no static assurances of what values will or will not be in the map at a given point in time.
Stacked Reader transformers. To allow ourselves to incrementally build up our environment, one might consider stacking the Reader monad transformers. Consider the type ReaderT a (ReaderT b (ReaderT c IO)) (). If we desugar this into function application, we find a -> (b -> (c -> IO ())), which can be further simplified to a -> b -> c -> IO (). If a, b and c happen to be the same type, we don’t have any way of distinguishing the different values, except for the location in the list of arguments. However, instead of writing out the parameters explicitly in our function signature (which, indeed, we are trying to avoid with the reader monad), we find ourselves having to lift ask repeatedly (zero times for a, once for b and twice for c). Unlike the record with three fields, there is no name for each environment variable: we have to refer to them by using some number of lifts.
Aside. In fact, this is a De Bruijn index, which Oleg helpfully pointed in out in an email conversation we had after my post about nested loops and continuations. The number of lifts is the index (well, the Wikipedia article is 1-indexed, in which case add one) which tells us how many reader binding scopes we need to pop out of. So if I have:
runReaderT (runReaderT (runReaderT (lift ask) c) b) a
\------- outermost/furthest context (3) ------------/
\--- referenced context (2; one lift) -/
\--- inner context (1) -/
I get the value of b. This turns out to be wonderful for the lambda-calculus theoreticians (who are cackling gleefully at trouble-free α-conversion), but not so wonderful for software engineers, for whom De Bruijn indexes are equivalent to the famous antipattern, the magic number.
With typeclass tricks, we can get back names to some extent: for example, Dan Piponi renames the transformers with singleton data types or “tags”, bringing in the heavy guns of OverlappingInstances in the process. Oleg uses lexical variables that are typed to the layer they belong to to identify different layers, although such an approach is not really useful for a Reader monad stack, since the point of the Reader monad is not to have to pass any lexical variables around, whether or not they are the actual variables or specially typed variables.
Implicit parameters. In many ways, implicit parameters are a cheat: while Dan and Oleg’s approaches leverage existing type-level programming facilities, implicit parameters define a “global” namespace (well known to Lispers as the dynamic scope) that we can stick variables in, and furthermore it extends the type system so we can express what variables in this namespace any given function call expects to exist (without needing to use monads, the moxy!)
Instead of an anonymous environment, we assign the variable a name:
f :: ReaderT r IO a
f' :: (?implicit_r :: r) => IO a
f' is still monadic, but the monad doesn’t express what is in the environment anymore: it’s entirely upon the type signature to determine if an implicit variable is passed along:
f = print "foobar" >> g 42 -- Environment always passed on
f' = print "foobar" >> g 42 -- Not so clear!
Indeed, g could have just as well been a pure computation:
f' = print (g 42)
However, if the type of is:
g :: IO a
the implicit variable is lost, while if it is:
g :: (?implicit_r :: r) => IO a
the variable is available.
While runReader(T) was our method for specifying the environment, we now have a custom let syntax:
runReaderT f value_of_r
let ?implicit_r = value_of_r in f
Besides having ditched our monadic restraints, we can now easily express our incremental environment:
run = let ?implicit_a = a
?implicit_b = b
?implicit_c = c
in h
h :: (?implicit_a :: a, ?implicit_b :: b, ?implicit_c :: c) => b
h = ?implicit_b
You can also use where. Note that, while this looks deceptively like a normal let binding, it is quite different: you can’t mix implicit and normal variable bindings, and if you have similarly named implicit bindings on the right-hand side, they refer to their values outside of the let. No recursion for you! (Recall runReaderT: the values that we supply in the second argument are pure variables and not values in the Reader monad, though with >>= you could instrument things that way.)
Good practices. With monadic structure gone, there are fewer source-level hints on how the monomorphism restriction and polymorphic recursion apply. Non-polymorphic recursion will compile, and cause unexpected results, such as your implicit parameter not changing when you expect it to. You can play things relatively safely by making sure you always supply type signatures with all the implicit parameters you are expecting. I hope to do a follow-up post explaining more carefully what these semantics are, based off of formal description of types in the relevant paper.
July 23, 2010Foreign.ForeignPtr is a magic wand you can wave at C libraries to make them suddenly garbage collected. It’s not quite that simple, but it is pretty darn simple. Here are a few quick tips from the trenches for using foreign pointers effectively with the Haskell FFI:
- Use them as early as possible. As soon as a pointer which you are expected to free is passed to you from a foreign imported function, you should wrap it up in a ForeignPtr before doing anything else: this responsibility lies soundly in the low-level binding. Find the functions that you have to import as
FunPtr. If you’re using c2hs, declare your pointers foreign. - As an exception to the above point, you may need to tread carefully if the C library offers more than one way to free pointers that it passes you; an example would be a function that takes a pointer and destroys it (likely not freeing the memory, but reusing it), and returns a new pointer. If you wrapped it in a ForeignPtr, when it gets garbage collected you will have a double-free on your hands. If this is the primary mode of operation, consider a
ForeignPtr (Ptr a) and a customized free that pokes the outside foreign pointer and then frees the inner pointer. If there is no logical continuity with respect to the pointers it frees, you can use a StablePtr to keep your ForeignPtr from ever being garbage collected, but this is effectively a memory leak. Once a foreign pointer, always a foreign pointer, so if you can’t commit until garbage do us part, don’t use them. - You may pass foreign pointers to user code as opaque references, which can result in the preponderance of newtypes. It is quite useful to define
withOpaqueType so you don’t have to pattern-match and then use withForeignPtr every time your own code peeks inside the black box. - Be careful to use the library’s
free equivalent. While on systems unified by libc, you can probably get away with using free on the int* array you got (because most libraries use malloc under the hood), this code is not portable and will almost assuredly crash if you try compiling on Windows. And, of course, complicated structs may require more complicated deallocation strategies. (This was in fact the only bug that hit me when I tested my own library on Windows, and it was quite frustrating until I remembered Raymond’s blog post.) - If you have pointers to data that is being memory managed by another pointer which is inside a ForeignPtr, extreme care must be taken to prevent freeing the ForeignPtr while you have those pointers lying around. There are several approaches:
- Capture the sub-pointers in a Monad with rank-2 types (see the
ST monad for an example), and require that the monad be run within a withForeignPtr to guarantee that the master pointer stays alive while the sub-pointers are around, and guarantee that the sub-pointer can’t leak out of the context. - Do funny things with
Foreign.ForeignPtr.Concurrent, which allows you to use Haskell code as finalizers: reference counting and dependency tracking (only so long as your finalizer is content with being run after the master finalizer) are possible. I find this very unsatisfying, and the guarantees you can get are not always very good.
- If you don’t need to release a pointer into the wild, don’t! Simon Marlow acknowledges that finalizers can lead to all sorts of pain, and if you can get away with giving users only a bracketing function, you should consider it. Your memory usage and object lifetime will be far more predictable.
July 21, 2010Attention conservation notice. Function pipelines offer an intuitive way to think about continuations: continuation-passing style merely reifies the pipeline. If you know continuations, this post probably won’t give you much; otherwise, I hope this is an interesting new way to look at them. Why do you care about continuations? They are frequently an extremely fast way to implement algorithms, since they are essentially pure (pipeline) flow control.
In Real World Haskell, an interesting pattern that recurs in functional programs that use function composition (.) is named: pipelining. It comes in several guises: Lispers may know it as the “how many closing parentheses did I need?” syndrome:
(cons 2 (cdr (cdr (car (car x)))))
Haskellers may see it in many forms: the parenthesized:
sum (map (+2) (toList (transform inputMap)))
or the march of dollar signs:
sum $ map (+2) $ toList $ transform inputMap
or perhaps the higher-order composition operator (as is suggested good style by several denizens of #haskell):
sum . map (+2) . toList . transform $ inputMap
There is something lexically interesting about this final form: the $ has divided it into two tokens, a function and an input argument. I can copy paste the left side and insert it into another pipeline effortlessly (compare with the parentheses, where after the paste occurs I have to manually insert the missing closing parentheses). The function is also a first class value, and I can write it in point-free style and assign it to a variable.
Of course, if I want to move it around, I have to cut and paste it. If I want to split it up into little parts, I have to pull a part the dots with my keyboard. If I want to use one pipeline in one situation, and another pipeline in a different one, I’d have to decide which situation I was in at the time of writing the program. Wouldn’t it be nice if a program could do it for me at runtime? Wink.
Consider the following pipeline in a Lisp-like language:
(h (g (f expr)))
When we refer to the “continuation” of expr there is frequently some attempt of visualizing the entire pipeline with expr removed, a hole in its place. This is the continuation:
(h (g (f ____)))
As far as visuals go, it could be worse. Since a continuation is actually a function, to be truly accurate we should write something horribly uninstructive along these lines:
(lambda (x) (h (g (f x))))
But this is good: it precisely captures what the continuation is, and is amenable to a more concise form. Namely, this can be written in Haskell point-free as:
h . g . f
So the continuation is just the pipeline to the left of the expression!
A little more detail, a lot more plumbing. There are two confounding factors in most treatments of continuations:
- They’re not written in a pure language, and a sequential series of actions is not immediately amenable to pipelining (although, with the power of monads, we can make it so), and
- The examples I have given still involve copy-paste: by copy-pasting, I have glossed over some details. How does the program know that the current continuation is
h . g . f? In callCC, how does it know when the current continuation got called?
For reference, here is an implementation of the Cont monad:
newtype Cont r a = Cont { runCont :: (a -> r) -> r }
instance Monad (Cont r) where
return x = Cont (\k -> k x)
(Cont c) >>= f = Cont (\k -> c (\r -> runCont (f r) k))
Where’d my nice pipelines go? I see a lot of lambdas… perhaps the Functor instance will give more clues:
instance Functor (Cont r) where
fmap f = \c -> Cont (\k -> runCont c (k . f))
That little composition operator should stand out: it states the essence of this Functor definition. The rest is just plumbing. Namely, when we lift some regular function (or pipeline) into the continuation monad, we have added the ability to compose arbitrary functions to the left end of it. That is, k . g . f, where k is my added function (the continuation). In more detail, from:
g . f
to:
\k -> k . (g . f)
or, with points:
\x k -> (k . g . f $ x)
Now there is a puzzle: suppose I have a function h. If I were not in continuation land, I could combine that with g . f as h . g . f. But if both are in continuation land: \k1 -> k1 . (g . f) and k2 -> k2 . h, how do I compose them now?
k1 is in the spot where I normally would have placed h, so a first would be to apply the first lifted function with the second lifted function as it’s argument:
\k1 -> k1 . (g . f) $ \k2 -> k2 . h
(\k2 -> k2 . h) . (g . f)
That doesn’t quite do it; the lambda closes its parentheses too early. We wanted:
\k2 -> k2 . h . (g . f)
With a little more head-scratching (left as an exercise to the reader), we find the correct form is:
\k -> (\k1 -> k1 . (g . f)) (\r -> (\k2 -> k2 . h) k r)
\-- 1st lifted fn --/ \-- 2nd fn --/
This is the essential mind-twisting flavor of continuation passing style, and the reader will notice that we had to introduce two new lambdas to make the kit and kaboodle run (reminiscent of our Monad instance). This is the ugly/elegant innards of the Continuation monad. There is, afterwards, the essential matter of newtype wrapping and unwrapping, and the fact that this implements Kleisli arrow composition ((a -> m b) -> (b -> m c) -> a -> m c, not bind m a -> (a -> m b) -> m b. All left as an exercise to the reader! (Don’t you feel lucky.)
Our final topic is callCC, the traditional method of generating interesting instances of continuations. The essential character of plain old functions in the Cont monad are that they “don’t know where they are going.” Notice in all of our examples we’ve posited the ability to compose a function on the left side k, but not actually specified what that function is: it’s just an argument in our lambda. This gives rise to the notion of a default, implicit continuation: if you don’t know where you’re going, here’s a place to go. The monadic code you might write in the Cont monad is complicit in determining these implicit continuations, and when you run a continuation monad to get a result, you have to tell it where to go at the very end.
callCC makes available a spicy function (the current continuation), which knows where it’s going. We still pass it a value for k (the implicit continuation), in case it was a plain old function, but the current continuation ignores it. Functions in the continuation monad no longer have to follow the prim and proper \k -> k . f recipe. callCC’s definition is as follows:
callCC f = Cont (\k -> runCont (f (\x -> Cont (\_ -> k a))) k)
The spicy function is \x -> Cont (\_ -> k x) (without the wrapping, it’s \x _ -> k x), which, as we can see, ignores the local current continuation (which corresponds to wherever this function was called) and uses k from the outer context instead. k was the current continuation at the time of callCC.
A parallel (though imperfect) can be made with pipelines: consider a pipeline where I would like the last function in the pipeline to be one type of function on a success, and another on failure:
\succ fail -> either fail succ . h . g . f
This pipeline has two outcomes, success:
\succ _ -> succ . fromRight . h . g . f
or failure:
\_ fail -> fail . fromLeft . h . g . f
In each case, the other continuation is ignored. The key for callCC is that, while it’s obvious how to ignore explicit continuations, it requires a little bit of thought to figure out how to ignore an implicit continuation. But callCC generates continuations that do just that, and can be used anywhere in the continuation monad (you just have to figure out how to get them there: returning it from the callCC or using the ContT transformer on a monad with state are all ways of doing so).
Note. The Logic monad uses success (SK) and failure (FK) continuations without the Cont monad to implement backtracking search, demonstrating that continuation passing style can exist without the Cont monad, and can frequently be clearer that way if you derive no benefits from having a default implicit continuation. It is no coincidence that Cont and callCC are particularly well suited for escape operations.
July 19, 2010System.Posix.Redirect is a Haskell implementation of a well-known, clever and effective POSIX hack. It’s also completely fails software engineering standards. About a week ago, I excised this failed experiment from my work code and uploaded it to Hackage for strictly academic purposes.
What does it do? When you run a command in a shell script, you have the option of redirecting its output to another file or program:
$ echo "foo\n" > foo-file
$ cat foo-file
foo
$ cat foo-file | grep oo
foo
Many APIs for creating new processes which allow custom stdin/stdout/stderr handles exist; what System.Posix.Redirect lets you do is redirect stdout/stderr without having to create a new process:
redirectStdout $ print "foo"
How does it do it? On POSIX systems, it turns out, almost exactly the same thing that happens when you create a subprocess. We can get a hint by strace’ing a process that creates a subprocess with slightly different handles. Consider this simple Haskell program:
import System.Process
import System.IO
main = do
-- redirect stdout to stderr
h <- runProcess "/bin/echo" ["foobar"] Nothing Nothing Nothing (Just stderr) Nothing
waitForProcess h
When we run strace -f (the -f flag to enable tracking of subprocesses), we see:
vfork(Process 26861 attached
) = 26861
[pid 26860] rt_sigprocmask(SIG_SETMASK, [], NULL, 8) = 0
[pid 26860] ioctl(0, SNDCTL_TMR_TIMEBASE or TCGETS, {B38400 opost isig icanon echo ...}) = 0
[pid 26860] ioctl(1, SNDCTL_TMR_TIMEBASE or TCGETS, {B38400 opost isig icanon echo ...}) = 0
[pid 26860] waitpid(26861, Process 26860 suspended
<unfinished ...>
[pid 26861] rt_sigprocmask(SIG_SETMASK, [], NULL, 8) = 0
[pid 26861] dup2(0, 0) = 0
[pid 26861] dup2(2, 1) = 1
[pid 26861] dup2(2, 2) = 2
[pid 26861] execve("/bin/echo", ["/bin/echo", "foobar"], [/* 53 vars */]) = 0
The dup2 calls are the key, since there are no special arguments to be passed to vfork or execve (the “53 vars” are the inherited environment) to fiddle with the standard handles of the subprocess, we need to fix them ourself. dup2 copies the file descriptor 2, guaranteed to be stderr (0 is stdin, and 1 is stdout), onto stdout, which is what we asked for in the original code. File descriptor tables are global to a process, so when we change the file descriptor 1, everyone notices.
There is one complication when we are not planning on following up the dup2 call with an execve: your standard library may be buffering output, in which case there might have been some data still living in your program that hasn’t been written to the file descriptor. If you play this trick in a normal POSIX C application, you only need to flush the FILE handles from stdio.h. If you’re in a Haskell application, you also need to flush Haskell’s buffers. (Notice that this isn’t necessary if you execve, since this system call blows away the memory space for the new program.)
Why did I write it? I had a very specific use-case in mind when I wrote this module: I had an external library written in C that wrote error conditions to standard output. Imagine a hPutStr that printed an error message if it wasn’t able to write the string, rather than raising an IOException; this would mean terrible things for client code that wanted to catch and handle the error condition. Temporarily redirecting standard output before calling these functions means that I can marshal these error conditions to Haskell while avoiding having to patch the external library or having to relegate it to a subprocess (which would cause much slower interprocess communication).
Why should I not use it in production? “It doesn’t work on Windows!” This is not 100% true: you could get a variant of this to work in some cases.
The primary problem is the prolific selection of runtimes and standard libraries available on Windows. Through some stroke of luck, the vast majority of applications written for Unix use a single standard library: libc, and you can be reasonably certain that you and your cohorts are using a single FILE abstraction, and since file descriptors are kernel-side, they’re guaranteed to work no matter what library you’re using. No such luxury on Windows: that DLL you’re linking against probably was compiled by some other compiler toolchain with it’s own runtime. GHC, in particular, uses the MingW toolchain to link on Windows, whereas native code is much more likely to have been compiled with Microsoft tools (MSVC++, anyone?). If the library could be recompiled with MingW, it could have worked, but I decided that it would be easier to just patch the library to return error codes another way. And so this module was obliterated from the codebase.
July 16, 2010Last Monday, I presented a parallel algorithm for computing maximum weighted matching, and noted that on real hardware, a naive implementation would deadlock.
Several readers correctly identified that sorting the nodes on their most weighted vertex only once was insufficient: when a node becomes paired as is removed from the pool of unpaired nodes, it could drastically affect the sort. Keeping the nodes in a priority queue was suggested as an answer, which is certainly a good answer, though not the one that Feo ended up using.
Feo’s solution. Assign every node an “is being processed bit.” When a node attempts to read its neighbor’s full/empty bit and finds the bit empty, check if the node is being processed. If it is not, atomically check and set the “is being processed bit” to 1 and process the node recursively. Fizzle threads that are scheduled but whose nodes are already being processed. The overhead is one bit per node.
I think this is a particularly elegant solution, because it shows how recursion lets work easily allocate itself to threads that would otherwise be idle.
July 14, 2010Category theory crash course for the working Haskell programmer.
A frequent question that comes up when discussing the dual data structures—most frequently comonad—is “What does the co- mean?” The snippy category theory answer is: “Because you flip the arrows around.” This is confusing, because if you look at one variant of the monad and comonad typeclasses:
class Monad m where
(>>=) :: m a -> (a -> m b) -> m b
return :: a -> m a
class Comonad w where
(=>>) :: w a -> (w a -> b) -> w b
extract :: w a -> a
there are a lot of “arrows”, and only a few of them flipped (specifically, the arrow inside the second argument of the >>= and =>> functions, and the arrow in return/extract). This article will make precise what it means to “flip arrows” and use the “dual category”, even if you don’t know a lick of category theory.
Notation. There will be several diagrams in this article. You can read any node (aka object) as a Haskell type, and any solid arrow (aka morphism) as a Haskell function between those two types. (There will be arrows of different colors to distinguish concepts.) So if I have f :: Int -> Bool, I will draw that as:

Functors. The Functor typeclass is familiar to the working Haskell programmer:
class Functor t where
fmap :: (a -> b) -> (t a -> t b)
While the typeclass seems to imply that there is only one part to an instance of Functor, the implementation of fmap, there is another, almost trivial part: t is now a type function of kind * -> *: it takes a type (a) and outputs a new type (unimaginatively named t a). So we can represent it by this diagram:

The arrows are colored differently for a good reason: they are indicating completely different things (and just happen to be on the same diagram). While the red arrow represents a concrete function a -> b (the first argument of fmap), the dashed blue arrow does not claim that a function a -> t a exists: it’s simply indicating how the functor maps from one type to another. It could be a type with no legal values! We could also posit the existence of a function of that type; in that case, we would have a pointed functor:
class Functor f => Pointed f where
pure :: a -> f a -- aka return
But for our purposes, such a function (or is it?) won’t be interesting until we get to monads.
You may have heard of the Functor law, an equality that all Functors should satisfy. Here it is in textual form:
fmap (g . f) == fmap g . fmap f
and here it is in pictorial form:

One might imagine the diagram as a giant if..then statement: if f, g and g . f exist, then fmap f, fmap g and fmap (g . f) exist (just apply fmap to them!), and they happen to compose in the same way.
Now, it so happens that if we have f :: a -> b and g :: b -> c, g . f is also guaranteed to exist, so we didn’t really need to draw the arrow either. This is such an implicit notion of function composition, so we will take a moment and ask: why is that?
It turns out that when I draw a diagram of red arrows, I’m drawing what mathematicians call a category with objects and arrows. The last few diagrams have been drawn in what is called the category Hask, which has objects as Haskell types and arrows as Haskell functions. The definition of a category builds in arrow composition and identities:
class Category (~>) where
(.) :: (b ~> c) -> (a ~> b) -> (a ~> c)
id :: a ~> a
(you can mentally substitute ~> with -> for Hask) and there are also laws that make arrow composition associative. Most relevantly, the categorical arrows are precisely the arrows you flip when you talk about a dual category.
“Great!” you say, “Does that mean we’re done?” Unfortunately, not quite yet. It is true that the comonad is a monad for an opposite (or dual) category, it is not the category Hask. (This is not the category you are looking for!) Still, we’ve spent all this time getting comfortable drawing diagrams in Hask, and it would be a shame to not put this to good use. Thus, we are going to see an example of the dual category of Hask.
Contravariant functors. You may have heard fmap described as a function that “lifts” functions in to a functorial context: this “functorial context” is actually just another category. (To actually mathematically show this, we’d need to show that the functor laws are sufficient to preserve the category laws.) For normal functors, this category is just Hask (actually a subcategory of it, since only types t _ qualify as objects). For contravariant functors, this category is Hask^op.
Any function f :: a -> b in Hask becomes a function contramap f :: f b -> f a in a contravariant functor:
class ContraFunctor t where
contramap :: (a -> b) -> t b -> t a
Here is the corresponding diagram:

Notice that we’ve partitioned the diagram into two sections: one in Hask, and one in Hask^op, and notice how the function arrows (red) flip going from one category to the other, while the functor arrows (blue) have not flipped. t a is still a contravariant functor value.
You might be scratching your head and wondering: is there any instance of contramap that we could actually use? In fact, there is a very simple one that follows directly from our diagram:
newtype ContraF a b = ContraF (b -> a)
instance ContraFunctor (ContraF a) where
contramap g (ContraF f) = ContraF (f . g)
Understanding this instance is not too important for the rest of this article, but interested readers should compare it to the functor on normal functions. Beyond the newtype wrapping and unwrapping, there is only one change.
Natural transformations. I’m going to give away the punchline: in the case of comonads, the arrows you are looking for are natural transformations. What are natural transformations? What kind of category has natural transformations as arrows? In Haskell, natural transformations are roughly polymorphic functions: they’re mappings defined on functors. We’ll notate them in gray, and also introduce some new notation, since we will be handling multiple Functors: subscripts indicate types: fmap_t is fmap :: (a -> b) -> t a -> t b) and η_a is η :: t a -> s a.

Let’s review the three types of arrows flying around. The red arrows are functions, they are morphisms in the category Hask. The blue arrows are indicate a functor mapping between types; they also operate on functions to produce more functions (also in the category Hask: this makes them endofunctors). The gray arrows are also functions, so they can be viewed as morphisms in the category Hask, but sets of gray arrows across all types (objects) in Hask from one functor to another collectively form a natural transformation (two components of a natural transformation are depicted in the diagram). A single blue arrow is not a functor; a single gray arrow is not natural transformations. Rather, appropriately typed collections of them are functors and natural transformations.
Because f seems to be cluttering up the diagram, we could easily omit it:

Monad. Here is the typeclass, to refresh your memory:
class Monad m where
(>>=) :: m a -> (a -> m b) -> m b
return :: a -> m a
You may have heard of an alternate way to define the Monad typeclass:
class Functor m => Monad m where
join :: m (m a) -> m a
return :: a -> m a
where:
m >>= f = join (fmap f m)
join m = m >>= id
join is far more rooted in category theory (indeed, it defines the natural transformation that is the infamous binary operation that makes monads monoids), and you should convince yourself that either join or >>= will get the job done.
Suppose that we know nothing about what monad we’re dealing with, only that it is a monad. What sort of types might we see?

Curiously enough, I’ve colored the arrows here as natural transformations, not red, as we have been doing for undistinguished functions in Hask. But where are the functors? m a is trivial: any Monad is also a valid instance of functor. a seems like a plain value, but it can also be treated as Identity a, that is, a inside the identity functor:
newtype Identity a = Identity a
instance Functor Identity where
fmap f (Identity x) = Identity (f x)
and Monad m => m (m a) is just a functor two skins deep:
fmap2 f m = fmap (fmap f) m
or, in point-free style:
fmap2 = fmap . fmap
(Each fmap embeds the function one functor deeper.) We can precisely notate the fact that these functors are composed with something like (cribbed from sigfpe):
type (f :<*> g) x = f (g x)
in which case m :<*> m is a functor.
While those diagrams stem directly from the definition of a monad, there are also important monad laws, which we can also draw diagrams for. I’ll draw just the monad identity laws with f:

return_a indicates return :: a -> m a, and join_a indicates join :: m (m a) -> m a. Here are the rest with f removed:


You can interpret light blue text as “fresh”—it is the new “layer” created (or compressed) by the natural transformation. The first diagram indicates the identity law (traditionally return x >>= f == f x and f >>= return == f); the second indicates associativity law (traditionally (m >>= f) >>= g == m >>= (\x -> f x >>= g)). The diagrams are equivalent to this code:
join . return == id == join . fmap return
join . join == join . fmap join
Comonads. Monads inhabit the category of endofunctors Hask -> Hask. The category of endofunctors has endofunctors as objects and (no surprise) natural transformations as arrows. So when we make a comonad, we flip the natural transformations. There are two of them: join and return.

Here is the type class:
class Functor w => Comonad w where
cojoin :: w a -> w (w a)
coreturn :: w a -> a
Which have been renamed duplicate and extract respectively.
We can also flip the natural transformation arrows to get our Comonad laws:
extract . duplicate == id == duplicate . extract
duplicate . duplicate == fmap duplicate . duplicate


Next time. While it is perfectly reasonable to derive <<= from cojoin and coreturn, some readers may feel cheated, for I have never actually discussed the functions from monad that Haskell programmers deal with on a regular basis: I just changed around the definitions until it was obvious what arrows to flip. So some time in the future, I hope to draw some diagrams for Kleisli arrows and show what that is about: in particular, why >=> and <=< are called Kleisli composition.
Apology. It being three in the morning, I’ve managed to omit all of the formal definitions and proofs! I am a very bad mathematician for doing so. Hopefully, after reading this, you will go to the Wikipedia articles on each of these topics and find their descriptions penetrable!
Postscript. You might be interested in this follow-up post about duality in simpler settings than monads/comonads.
July 12, 2010Subtitle: Massively multithreaded processors make your undergraduate CS education relevant again.
Quicksort. Divide and conquer. Search trees. These and other algorithms form the basis for a classic undergraduate algorithms class, where the big ideas of algorithm design are laid bare for all to see, and the performance model is one instruction, one time unit. “One instruction, one time unit? How quaint!” proclaim the cache-oblivious algorithm researchers and real world engineers. They know that the traditional curriculum, while not wrong, is quite misleading. It’s simply not enough to look at some theoretical computing machine: the next-generation of high performance algorithms need to be in tune with the hardware they run on. They couldn’t be more right.

Last Friday, Dr. John Feo gave a Galois Tech Talk entitled Requirements and Performance of Data Intensive, Irregular Applications (slides 1). However, Feo also brought in some slides from another deck which talked more generally about the Center for Adaptive Supercomputing Software (slides 2). The resulting presentation was a blend of the principles of massively multithreaded processor architectures—specifically the Cray XMT —and practical engineering problems encountered when writing software for such machines. Since I can’t resist putting spin on a good presentation, the title of these notes comes from a conversation I had with Feo after the tech talk; I don’t mean to demean those doing research on traditional processor, just to suggest that there is another approach that doesn’t receive as much attention as Feo thinks it should. For those of you who like puzzles, there will also be a “Why does this deadlock?” question at the end of this post.
Graphs not grids. John Feo started off by distinguishing between problems in science and problems in informatics. Scientific problems frequently take the form of grids, slowly evolving systems that exhibit the principle of locality and involve only nearest neighbor communication inside the grid. These types of problem are tackled extremely well by cluster parallelization: planar grids are obvious to partition, and nearest neighbor communication means that the majority of any computation will be local to the node containing the partition. Locality also means that, with a little care, these algorithms can play nicely with the CPU cache: for cache-oblivious algorithms, this just means partitioning the problem until it fits on-board.
Data informatics, however, sees quite different datasets. Consider the friends graph on Facebook, or the interlinking pages of the web, or the power grid of your country. These are not grids (not even the power grid): they are graphs. And unlike a quantum chromodynamic simulation, these graphs are dynamic, constantly being changed by many autonomous agents, and they can present some unique problems for traditional processors and parallelization.
Difficult graphs. There are several types of graphs that are particularly hard to run algorithms on. Unfortunately, they also tend to show up frequently in real world datasets.
Low diameter (aka “small world”) graphs are graphs in which the degree of separation between any two nodes is very low. The work necessary on these graphs explodes; any algorithm that looks at the neighbors of a node will quickly find itself having to operate on the entire graph at once. Say good bye to memory locality! The tight coupling also makes the graph difficult to partition, which is the classic way to parallelize a computation on a graph.
Scale-free graphs are graphs in which a small number of nodes have an exponentially large number of neighbors, and a large number of nodes have a small number of neighbors. These graphs are also difficult to partition and result in highly asymmetric workloads: the few nodes with large amounts neighbors tend to attract the bulk of the work.
There are also properties of graphs that can make computation more difficult. Non-planar graphs are generally harder to partition; dynamic graphs have concurrent actors inserting and deleting nodes and edges; weighted graphs can have pathological weight distributions; and finally graphs with typed edges prevent you from reducing a graph operation into a sparse matrix operation.
This slide from Feo sums up the immediate effects of these types of graphs nicely.

Multithreaded processors: gatling guns of the computing world. The gatling gun was one of the first well-known rapid-fire guns. Other guns simply increased their rate of fire, but quickly found that their gun barrels overheated if they attempted to fire too quickly. The gatling gun used multiple barrels, each of which individually fired at a slower rate, but when rotated in succession allowed a continuous stream of bullets to be fired while allowing the barrels not in use to cool off.
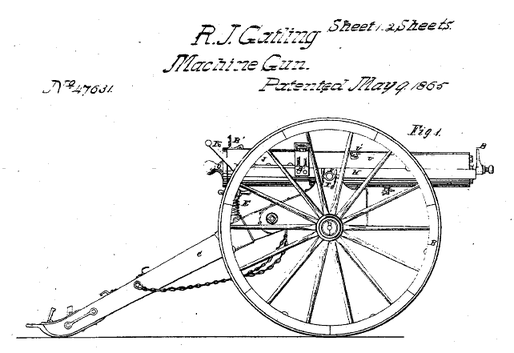
The time it takes for a discharged barrel to cool off is similar to the latency of a memory access. Since memory accesses are expensive, traditional processors try to “use less bullets” and forgo memory accesses with on-processor caches. However, a massively multithreaded processor takes a different approach: instead of trying to eliminate the memory latency, it simply hides it by context switching away from a thread that requests memory, so that by the time it switches back, the access has been completed and the data available. No need to twiddle your thumbs while waiting for data; go do something else! On specialized hardware, the researches at PNNL have been able to get processor utilization upwards of 90%; on less specialized hardware, performance targets are a bit more modest—40% or so.
Implications. Because the massively multithreaded processor is hiding memory access latency, not trying to get rid of it, traditional constraints such as memory locality become unimportant. You don’t need data to be near your computation, you don’t need to balance work across processors (since it all goes into threads that cohabit), you don’t need to handle synchronization like a time bomb. What you learned in undergraduate computer science is relevant again! In Feo’s words:
- Adaptive and dynamic methods are okay,
- Graph algorithms and sparse methods are okay, and
- Recursion, dynamic programming, branch-and-bound, dataflow are okay!
Your hardware, then, will be tailored for graph-like computations. This includes a huge global address space to shove your graph into, extremely lightweight synchronization in the form of full/empty bits (Haskell users might recognize them as extremely similar to MVars; indeed, they come from the same lineage of dataflow languages) and hardware support for thread migration, to balance out workloads. It’s something of a holy hardware grail for functional languages!
The Cray XMT is one particular architecture that John Feo and his fellow researchers have been evaluating. It easily beats traditional processors when handling algorithms that exhibit poor locality of reference; however, it is slower when you give the traditional processor and algorithm with good locality of reference.
Maximum weight matching. There are many graph problems—shortest path, betweenness centrality, min/max flow, spanning trees, connected components, graph isomorphism, coloring, partitioning and equivalence, to name a few. The one Feo picked out to go into more detail about was maximum weight matching. A matching is a subset of edges such that no two edges are incident on the same vertex; so a maximum weight matching is a matching where the weights of the selected edges has been maximized (other cost functions can be considered, for example, on an unweighted graph you might want to maximize the number of edges).
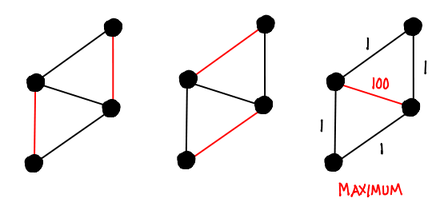
While there is a polynomial-time algorithm for finding maximum weight matchings, we can get an approximate answer more quickly with a greedy parallel algorithm called Hoepman’s algorithm. It is reminiscent of the stable marriage (Gale-Shapely) algorithm; the algorithm runs as follows: each node requests to be paired with the node across most expensive vertex local to it. If two nodes request each other, they are paired, and they reject all other pairing requests. If a node gets rejected, it tries the next highest vertex, and so on. Since a node will only accept one pairing request, edges in the pairing will never be incident on the same vertex.
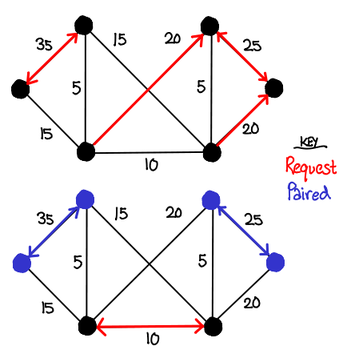
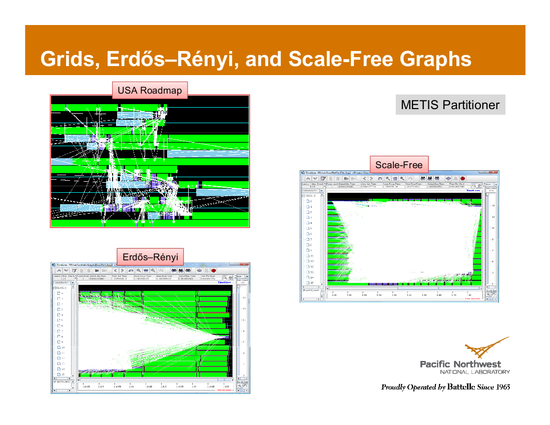
Hoepman’s algorithm relies on a theoretical machine that is able to allocate a processor per node. This doesn’t bode well for traditional cluster machines, so Halappanavar, Dobrian and Pothen proposed a parallel version that separates the graph into partitions which are given to processors, and uses queues to coordinate communicate across the partitions. Unfortunately, this approach performs extremely poorly in some cases. Feo has some visualizations of this phenomenon: the pictures below are visual depictions of processor cores, where green indicates the core is busy, and white lines indicate inter-processor communication. While the regular, planar graph of US roadways handles the problem nicely, both graphs generated by the Erdős–Rényi model and scale-free free graphs (one of the “tough” graph types we mentioned earlier) have inter-processor communication explode in sheets of white.
Machines like the Cray XMT, however, make it plausible to try to implement Hoepman’s original algorithm more closely. Give each node a thread, and implement the algorithm as described.
In order to implement signaling, we can use the full/empty bit primitive. Every edge has two full/empty bits, each endpoint owning one each. When a node attempts to pair with a vertex, it fills its own bit with 1, and then tries to read the other bit. While the bit is empty, the node’s thread blocks. If the other bit reads 1, the node is paired: fill all other bits the node owns with 0 and then terminate. If the other bit reads 0, try your next neighbor with the highest edge.
This approach doesn’t quite work, due to real-world constraints on the Cray XMT. In particular, for large graphs, it’s not possible for every thread to be run simultaneously; only a subset of nodes can be run at a time. If it just happens that every node is waiting on another node which is not being currently run, all the nodes block, and we have deadlock. In particular, the Cray XMT will not pre-empt a thread that is blocked by default, because the cost of context switching is so high. (You could turn pre-emption on, in which case this deadlock would go away, but at great cost to runtime. While the Cray does thread-level context switching every cycle, actually evicting the thread off its processor is quite expensive.)
The simple fix Feo applied was the following observation: as long as we schedule nodes closed to expensive edges, there will always be work to be done: in particular, the two nodes incident to the most expensive unpaired edge will always be able to pair. So sort the nodes in order of their most expensive vertex, and then run the algorithm. This resolved most of the deadlocks.
Ending notes. While massively multithreaded architectures are promising, there is a lot of work that still needs to be done both on the hardware side (making this technology available on commodity hardware, and not just the Cray XMT) as well as the software ecosystem (building new programming APIs to take advantage of the architecture.) Even further, the problems in this domain are so diverse that no one machine can truly attack all of them.
Nevertheless, Feo remains optimistic: if the problems are important enough, the machines will get built.
Puzzle. Even with the sorting modification, the implementation of maximum matching on the Cray XMT with preempting disabled still deadlocks on some large graphs. What graphs cause it to deadlock, and what is an easy way to fix the problem? (According to Feo, it took him three days to debug this deadlock! And no, turning on preemption is not the answer.) Solution will be posted on Friday.
(There might be answers in the comment section, so avert your eyes if you don’t want to be spoiled.)
Update. I’ve removed the link to the CACM article; while I thought it was timely for Reddit readers, it implied that Varnish’s designer was a “young algorithms designer corrupted by cache locality”, which is completely false. The expression was meant to express Feo’s general dissatisfaction with the general preoccupation of the algorithms community towards the complicated cache-aware/oblivious algorithms, and not directed at anyone in particular.
(THIS SPACE LEFT INTENTIONALLY BLANK)
July 9, 2010Update. While this blog post presents two true facts, it gets the causal relationship between the two facts wrong. Here is the correction.
Attention conservation notice. Don’t use unsafe in your FFI imports! We really mean it!
Consider the following example in from an old version of Haskellwiki’s FFI introduction:
{-# INCLUDE <math.h> #-}
{-# LANGUAGE ForeignFunctionInterface #-}
module FfiExample where
import Foreign.C -- get the C types
-- pure function
-- "unsafe" means it's slightly faster but can't callback to haskell
foreign import ccall unsafe "sin" c_sin :: CDouble -> CDouble
sin :: Double -> Double
sin d = realToFrac (c_sin (realToFrac d))
The comment blithely notes that the function can’t “callback to Haskell.” Someone first learning about the FFI might think, “Oh, that means I can put most unsafe on most of my FFI declarations, since I’m not going to do anything advanced like call back to Haskell.”
Oh my friend, if only it were that simple!
Recall that when you create a thread in Haskell with forkIO, you’re not creating a real operating system thread; you’re creating a green thread that Haskell’s runtime system manages across its pool of operating system threads. This is usually very good: real threads are heavyweight, but Haskell threads are light and you can use a lot of them without paying too much. But here’s the rub:
The runtime system cannot preempt unsafe FFI calls!
In particular, when you invoke an unsafe FFI import, you effectively suspend everything else going on in the system: Haskell is not able to preempt it (in particular unsafe indicated that there was no need to save the state of the RTS), and the foreign code will keep running by itself until it finishes.
Don’t believe me? Try it out yourself (I conducted my tests on 6.12.1). You’ll need a few files:
/* cbit.c */
#include <stdio.h>
int bottom(int a) {
while (1) {printf("%d\n", a);sleep(1);}
return a;
}
/* cbit.h */
int bottom(int a);
And UnsafeFFITest.hs:
{-# LANGUAGE ForeignFunctionInterface #-}
import Foreign.C
import Control.Concurrent
main = do
forkIO $ do
safeBottom 1
return ()
yield
print "Pass (expected)"
forkIO $ do
unsafeBottom 2
return ()
yield
print "Pass (not expected)"
foreign import ccall "cbit.h bottom" safeBottom :: CInt -> IO CInt
foreign import ccall unsafe "cbit.h bottom" unsafeBottom :: CInt -> IO CInt
Compile and run the relevant files with:
gcc -c -o cbit.o cbit.c
ghc -threaded --make UnsafeFFITest.hs cbit.o
./UnsafeFFITest +RTS -N4
The output you see should be similar to this:
ezyang@javelin:~/Dev/haskell/unsafe-ffi$ ./UnsafeFFITest +RTS -N2
1
"Pass (expected)"
2
1
2
1
2
The first call played nice and let Haskell move along, but the second call didn’t. Some things to try for yourself include swapping the order of the forks, using forkOS (which many people, including myself, incorrectly assumed creates another operating system call) and changing the RTS option -N.
What does this mean? Essentially, only if you’re really sure Haskell will never have to preempt your C call (which I would not be comfortable saying except for the smallest, purest C functions), don’t use unsafe. It’s not worth it. Safety first!
Postscript. Thanks #haskell for helping me hash out this line of thought (I’d run into this behavior earlier, but it hadn’t occurred to me that it was bloggable.)
Postscript 2. Thanks to Simon Marlow for clarifying some mistakes that I made in my original treatment of the topic. If you’re interested in more details about the interaction of concurrency and the FFI, check out the paper he pointed to: Extending the Haskell Foreign Function Interface with Concurrency.
July 7, 2010Tapping away at a complex datastructure, I find myself facing a veritable wall of Babel.

“Zounds!” I exclaim, “The GHC gods have cursed me once again with a derived Show instance with no whitespace!” I mutter discontently to myself, and begin pairing up parentheses and brackets, scanning the sheet of text for some discernible feature that may tell me of the data I am looking for.
But then, a thought comes to me: “Show is specified to be a valid Haskell expression without whitespace. What if I parsed it and then pretty-printed the resulting AST?”
Four lines of code later (with the help of Language.Haskell)…

Ah, much better!
How to use it. In your shell:
cabal install groom
and in your program:
import Text.Groom
main = putStrLn . groom $ yourDataStructureHere
Update. Gleb writes in to mention ipprint which does essentially the same thing but also has a function for putStrLn . show and has some tweaked defaults including knowledge of your terminal size.
Update 2. Don mentions to me the pretty-show package by Iavor S. Diatchki which also does similar functionality, and comes with an executable that lets you prettify output offline!
July 5, 2010A short thought from standing in line at the World Expo: Little’s law is a remarkable result that relates the number of people in a queue, the arrival rate of people to the queue, and the time spent waiting in the queue. It seems that it could be easily applied to a most universal feature of theme parks: waiting queues. Instead of such unreliable methods as giving visitors tokens to test how long it takes to traverse some portion of the line and then eyeballing the wait time from there, it would be a simple matter to install two gates: one to count incoming visitors and one to count outgoing visitors, and with this data derive an instantaneous “wait time in queue” figure based on a smoothed running average of queue size and arrival rate. Added benefit for being electronic, which means you can easily beam it to information boards across the park!
It occurs to me that I don’t have any evidence that theme parks aren’t already using this technique, except maybe for the fact that their posted wait times are wildly inaccurate.