October 1, 2010A hackathon is an event, spanning from a day to a week, where hackers (not the cracking kind) get together to work on some common goals in concert. One use of a hackathon is to get some open-source contributors together and work hard on a particular feature: the combination of being together and being expected to work on the task at hand means that people are more productive than they would be if they were just working alone.
However, at SIPB, we use hackathons in a different way: in fact, this type of a hackathon could be said to make maintainers less effective at whatever tasks they may have on hand. The idea of this hackathon is to get new people interested and working on existing projects. This is vital in a university environment, where people graduate after only four years and we constantly need to be looking for fresh people.
Here are some off-the-cuff tips that I’ve noticed help make these sorts of hackathons more successful when the day rolls around.
- Communicate to established project members that you will not get stuff done until the wee hours of the hackathons, when the prospectives have left. Expect to be answering questions, helping people get set up, and generally being attentive to the activity around the hackathon on your project.
- Establish a list of tasks to work on before the hackathon begins. Parallelization is hard, even in the real world, and so you should already have bite-sized independent pieces of work to give to prospectives who are ready to just start working.
- Have a lot of tasks. People have different interests, even though they will undoubtedly tell you, “Oh, anything is ok,” and you should make it clear that if they’re not having fun working towards some task, maybe they could try a different one.
- Have tasks of differing difficulty. Yes, it’s nice when that one person walks in, has the development environment setup in half an hour, and manages to finish his task way before the end of the hackathon. Most people are not like that; for some, setting up a development environment is a task that can consume an entire afternoon and evening. This is frustrating. Let them know that there are things that they can actually make productive progress on.
- Keep track of who’s working on what and the final achievements. It’s really nice to be able to say what was accomplished at the end of the hackathon; it makes people feel good and encourages them to come back.
- Check in with prospectives, but not too often. It’s good to check half an hour after getting someone started how they are doing and help them out if they’re struggling. But check on them too much and you can easily make them feel nervous or pressured, which is not fun and therefore not OK for a hackathon.
- Take advantage of questions that require “long answers.” If someone suggests X and in fact, we’ve thought about it but can’t do X for some complicated reason Y, don’t wave the question off: tell the person about Y. They might even have a reason around it, and either way, they learn more about the system they are working on in a really effective way: knowledge as you need it.
- Be an enabler. Do the boring, tedious tasks that you’ve procrastinated on if it would make a prospective more effective and have more fun on a task. You can trick them into doing those “housekeeping” tasks later, when they’re invested in the project. (wink)
I encourage past hackathon organizers to also share their wisdom!
September 29, 2010As one of those “busy maintainers,” I’ve noticed that I assume a certain cognitive mode when fielding support requests. This post is about how I deal with support requests, but I’ve also seen this behavior widely on other projects. While, as the person making the request, you may find such a mentality frustrating and obtuse, if you are a fellow developer you can use it in your favor.
What do I think when I see your support request?
- I want to help you. If I wasn’t interesting in answering your questions, I would have desupported this project. However…
- I want to fix the issue with as little cognitive effort as possible. I want to use my brain power thinking about new features and theory, not doing sleuthing for the user. Relatedly,
- I want to fix the issue with as little real effort as possible. If I have actually do things to figure out how to fix your problem, I’m more inclined to procrastinate on it. Add a doubling modifier if I’m not sure what I need to do. Paradoxically, if I have access to your setup, I might just go and fix it, because my usual debugging cycle is much faster than, “Ask you to try something or get some information and report it to me.”
Notice that feature requests operate on a different set of rules. For scratch an itch software I may have little interest in features that don’t help me. But if I am going to put a feature in that doesn’t immediately help you, I want to do it right—just because it works for you doesn’t mean it should be in my codebase. And, of course, the moment it’s someone else trying to get code in, my code standards shoot way up.
In accordance with these principals of benevolent laziness, answers to support requests you get might be:
- Short,
- A guess that it’s some common issue that you may have already noticed while Googling (you did try Googling it first, right?),
- Asking you for more (sometimes seemingly irrelevant) information,
- Asking you to try something that may or may not work, and
- Late. (I set aside some time every few weeks to go through their open tickets, and you won’t get an answer until then.)
So how do you use these facts to your favor?
Don’t assume that your problem is the same as someone else’s. Support requests are not bugs! They may be generated by bugs, but every support request has its own individual flavor to it, and until its cause is pinned down to a specific technical issue, you’re muddying the waters if you decide that your problem is the same as some other complicated problem. Reference the existing bug or support request in your request and let the maintainer decide.
Give me lots of information, even if you think it’s unnecessary. Why did you make this support request? I can’t speak for everyone, but when I ask for help it’s usually because I believe that someone out there has a much more comprehensive big picture and because I believe that they will have some insight that I don’t have. So why do I have any reason to believe some debugging information that I think is useless won’t help someone who is much more attuned to the software divine the problem? Furthermore, if I am only looking at support requests once every two weeks, you better hope you’ve given me enough information to figure it out when I actually look at your request.
Relatedly, don’t be tempted to “curate” the information: some of the worst debugging sessions I’ve had were because I misinterpreted some evidence I got, and then acted on that wrong assumption.
Make it easy for the maintainer to debug the problem. Minimal test cases, minimal test cases, minimal test cases. It’s even better if it’s running code that doesn’t require any setting up, but frequently the specific setup will have the information the maintainer needs to figure out your problem.
Do your own debugging. You’ve handed the maintainer a problem that they don’t know an answer off the top of their head to. It might be a real bug. If they’re particularly accommodating, they’ll try to recreate your problem and then debug it from their local setup; if they’re not, they’ll try simulating their debugging process through you. You can tell that this is the case when the start asking you for specific pieces of information or tweaks. Don’t let them initiate this lengthy and time-consuming process: do your own debugging. Because you are seeing the problem, you are the best person to actually debug it.
“But,” you might say, “Why should I voluntarily debug other people’s code!” This case is a little different: this is not legacy code where the original author is nowhere to be found: you have a benevolent upstream willing to help you out. You have someone to sanity check your results, tell you what tools to use (something like PHP will be easy to debug: just edit some source files; something like a C application is tougher, but gdb with debug symbols can work wonders), point you in the right direction and short-circuit the rest of the process when you tell them some key piece of information. The key bit is: if you have a question about the software, and you know an experiment you can run to answer that question, don’t ask: run the experiment.
Make me fix my documentation. I’m worried about answering your question, not necessarily about fixing my software. If there is some doc somewhere that was unclear, or some runtime check that could have prevented you from needing to ask your question, make me fix it by pointing it out! Different people absorb information differently, so it’s good if as many ways as possible to communicate some piece of information are available.
September 27, 2010For tomorrow I get on a plane traversing three thousand miles from my home to a little place named Cambridge, United Kingdom. I’ll be studying abroad for the 2010-2011 academic year at Cambridge University (specifically, I’ll be at Fitzwilliam college). While I know Baltimore is a fashionable place to be these days, if you’re in the area, drop me a line: I’d love to meet up after I get over my jet lag. :-)
September 24, 2010Continuations are well known for being notoriously tricky to use: they are the “gotos” of the functional programming world. They can make a mess or do amazing things (after all, what are exceptions but a well structured nonlocal goto). This post is intended for readers with a passing familiarity with continuations but a disbelief that they could be useful for their day-to-day programming tasks: I’d like to show how continuations let us define high performance monads ala the Logic monad in a fairly methodical way. A (possibly) related post is The Mother of all Monads. :
> import Prelude hiding (Maybe(..), maybe)
We’ll start off with a warmup: the identity monad. :
> data Id a = Id a
> instance Monad Id where
> Id x >>= f = f x
> return = Id
The continuation-passing style (CPS) version of this monad is your stock Cont monad, but without callCC defined. :
> data IdCPS r a = IdCPS { runIdCPS :: (a -> r) -> r }
> instance Monad (IdCPS r) where
> IdCPS c >>= f =
> IdCPS (\k -> c (\a -> runIdCPS (f a) k))
> return x = IdCPS (\k -> k x)
While explaining CPS is out of the scope of this post, I’d like to point out a few idioms in this translation that we’ll be reusing for some of the more advanced monads.
- In order to “extract” the value of
c, we pass it a lambda (\a -> ...), where a is the result of the c computation. - There is only one success continuation
k :: a -> r, which is always eventually used. In the case of bind, it’s passed to runIdCPS, in the case of return, it’s directly invoked. In later monads, we’ll have more continuations floating around.
Following in step with monad tutorials, the next step is to look at the venerable Maybe data type, and its associated monad instance. :
> data Maybe a = Nothing | Just a
> instance Monad Maybe where
> Just x >>= f = f x
> Nothing >>= f = Nothing
> return = Just
When implementing the CPS version of this monad, we’ll need two continuations: a success continuation (sk) and a failure continuation (fk). :
> newtype MaybeCPS r a = MaybeCPS { runMaybeCPS :: (a -> r) -> r -> r }
> instance Monad (MaybeCPS r) where
> MaybeCPS c >>= f =
> MaybeCPS (\sk fk -> c (\a -> runMaybeCPS (f a) sk fk) fk)
> return x = MaybeCPS (\sk fk -> sk x)
Compare this monad with IdCPS: you should notice that it’s quite similar. In fact, if we eliminated all mention of fk from the code, it would be identical! Our monad instance heartily endorses success. But if we add the following function, things change:
> nothingCPS = MaybeCPS (\_ fk -> fk)
This function ignores the success continuation and invokes the failure continuation: you should convince yourself that one it invokes the failure continuation, it immediately bugs out of the MaybeCPS computation. (Hint: look at any case we run a MaybeCPS continuation: what do we pass in for the failure continuation? What do we pass in for the success continuation?)
For good measure, we could also define:
> justCPS x = MaybeCPS (\sk _ -> sk x)
Which is actually just return in disguise.
You might also notice that the signature of our MaybeCPS newtype strongly resembles the signature of the maybe “destructor” function—thus called because it destroys the data structure:
> maybe :: Maybe a -> (a -> r) -> r -> r
> maybe m sk fk =
> case m of
> Just a -> sk a
> Nothing -> fk
(The types have been reordered for pedagogical purposes.) I’ve deliberately named the “default value” fk: they are the same thing! :
> monadicAddition mx my = do
> x <- mx
> y <- my
> return (x + y)
> maybeTest = maybe (monadicAddition (Just 2) Nothing) print (return ())
> maybeCPSTest = runMaybeCPS (monadicAddition (return 2) nothingCPS) print (return ())
Both of these pieces of code have the same end result. However, maybeTest constructs a Maybe data structure inside the monadic portion, before tearing it down again. runMaybeCPS skips this process entirely: this is where the CPS transformation derives its performance benefit: there’s no building up and breaking down of data structures.
Now, to be fair to the original Maybe monad, in many cases GHC will do this transformation for you. Because algebraic data types encourage the creation of lots of little data structures, GHC will try its best to figure out when a data structure is created and then immediately destructed, and optimize out that wasteful behavior. Onwards!
The list monad (also known as the “stream” monad) encodes nondeterminism. :
> data List a = Nil | Cons a (List a)
> instance Monad List where
> Nil >>= _ = Nil
> Cons x xs >>= f = append (f x) (xs >>= f)
> return x = Cons x Nil
> append Nil ys = ys
> append (Cons x xs) ys = Cons x (append xs ys)
Nil is essentially equivalent to Nothing, so our friend the failure continuation comes back to the fray. We have to treat our success continuation a little differently though: while we could just pass it the value of the first Cons of the list, this wouldn’t let us ever get past the first item of the list. So we’ll need to pass our success continuation a resume continuation (rk) in case it wants to continue down its path. :
> newtype LogicCPS r a = LogicCPS { runLogicCPS :: (a -> r -> r) -> r -> r }
> instance Monad (LogicCPS r) where
> LogicCPS c >>= f =
> LogicCPS (\sk fk -> c (\a rk -> runLogicCPS (f a) sk rk) fk)
> return x = LogicCPS (\sk fk -> sk x fk)
Remember that return generates singleton lists, so there’s nothing more to continue on to, and we give the success continuation fk as the resume continuation.
The old data constructors also can be CPS transformed: nilCPS looks just like nothingCPS. consCPS invokes the success continuation, and needs to generate a resume continuation, which conveniently enough is given by its second argument:
> nilCPS =
> LogicCPS (\_ fk -> fk)
> consCPS x (LogicCPS c) =
> LogicCPS (\sk fk -> sk x (c sk fk))
> appendCPS (LogicCPS cl) (LogicCPS cr) =
> LogicCPS (\sk fk -> cl sk (cr sk fk))
These types should be looking awfully familiar. Rearranging this type a little (and renaming b→r):
foldr :: (a -> b -> b) -> b -> [a] -> b
I get:
fold :: List a -> (a -> r -> r) -> r -> r
Hey, that’s my continuation. So all we’ve done is a fold, just without actually constructing the list!
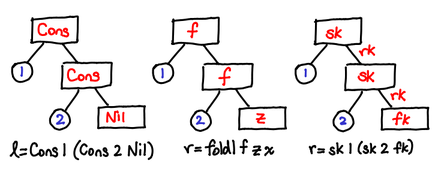
Keen readers will have also noticed that the CPS formulation of the list is merely the higher-order Church encoding of lists.
The CPS transformed version of the list monad wins big in several ways: we never need to construct and destruct the list and appending two lists takes O(1) time.
One last example: the leafy tree monad (cribbed from Edward Kmett’s finger tree slides):
> data Leafy a = Leaf a | Fork (Leafy a) (Leafy a)
> instance Monad Leafy where
> Leaf a >>= f = f a
> Fork l r >>= f = Fork (l >>= f) (r >>= f)
> return a = Leaf a
As it turns out, if we want to fold over this data type, we can reuse LogicCPS:
> leafCPS x = return x
> forkCPS l r = appendCPS l r
To go in the other direction, if we combine all of the CPS operations on logic we’ve defined thus far and turn them back into a data type, we get a catenable list:
> data Catenable a = Append (Catenable a) (Catenable a) | List (List a)
To wrap (fold) up, we’ve shown that when we build up a large data structure that is only going to be destructed when we’re done, we’re better off fusing the two processes together and turn our data structure back into code. Similarly, if we would like to do “data structure”-like things to our data structure, it is probably better to actually build it up: the Church encodings for things like tail are notoriously inefficient. I’ve not said anything about monads that encode state of some sort: in many ways they’re a different breed of monad from the control flow monad (perhaps a more accurate statement is “Cont is the mother of all control flow monads”).
To quote Star Wars, the next time you find yourself entangled in a mess of continuations, use the data structure!
Addendum. CPS transforming data structure traversal has nothing to do with monads. You can do it to anything. It just so happens that the killer feature of control flow monads, nondeterminism, happens to really benefit from this transformation.
References. There are loads and loads of existing treatments of this subject.
I’ve probably missed a bunch of other obvious ones too.
September 22, 2010Yesterday I had the pleasure of attending a colloquium given by Chung-Chieh Shan on Embedding Probabilistic Languages. A full account for the talk can be found in this paper, so I want to focus in on one specific big idea: the idea that data is code.
Lispers are well acquainted with the mantra, “code is data,” the notion that behind every source code listing there is a data structure of cons-cells and tags representing the code that can constructed, modified and evaluated. With this framework, a very small set of data is code: '(cons 1 (cons 2 ())) is code but '((.5 ((.5 #t) (.5 #f))) (.5 ((.5 #t)))) isn’t.
Under what circumstances could the latter be code? Consider the following question (a hopefully unambiguous phrasing of the Boy-Girl paradox):
You close your eyes. I hand you a red ball or a blue ball. Then, I will hand you a red ball or a blue ball. You then peek and discover that at least one of the balls is red. What are the odds that the first one was red?
Those of you familiar with probability might go write up the probability table and conclude the answer is 2/3, but for those who are less convinced, you might go write up some code to simulate the situation:
a <- dist [(.5, red), (.5, blue)]
b <- dist [(.5, red), (.5, blue)]
if a != red && b != red
then fail
else a == red
Where dist is some function that randomly picks a variable from a distribution, and fail reports a contradiction and ignores the generated universe. This code is data, but it is data in a much deeper way than just an abstract syntax tree. In particular, it encodes the tree of inference '((.5 ((.5 #t) (.5 #f))) (.5 ((.5 #t)))):
O O
/ \ / \
/ \ / \
R B .5 .5
/ \ / \ / \ / \
RR RB BR BB .25.25.25
#t #t #f
Aside. Interested Haskellers may now find it instructive to go off and write the naive and continuation passing implementations of the probability monad suggested by the above code, a monad which, when run, returns a list of the probabilities of all possible outcomes. It is an interesting technical detail, which will possibly be the subject of a future blog post, but it’s treated quite well in sections 2.2, 2.3 and 2.4 of the above linked paper and fairly standard practice in the continuation-using community.
Now, I haven’t really shown you how data is code; rather, I’ve shown how code can map onto an “abstract syntax tree” representation or an “inference tree” representation. However, unlike an AST, we shouldn’t naively build out the entire inference tree: inference trees whose nodes have many children can branch out exponentially, and we’d run out of memory before we could do what is called exact inference: attempt to build out the entire inference tree and look at every result.
However, if we follow the mantra that “data is code” and we represent our tree as a lazy data structure, where each child of a node is actually a continuation that says “build out this subtree for me,” we recover an efficient representation. These continuation can, themselves, contain more continuations, which are to be placed at the leaves of the subtree, to be applied with the value of the leaf. Thus our data structure is, for the most part, represented by code. (This is in fact how all lazy data structures work, but it’s particularly poignant in this case.)
Even more powerfully, first-class support for delimited continuations means that you can take a regular function () -> e and reify it into a (partial) tree structure, with more continuations as children ready to themselves be reified. We can, of course, evaluate this tree structure to turn it back into a function. (Monads in Haskell cheat a little bit in that, since lambdas are everywhere, you get this representation for free from the abstraction’s interface.)
What I find really fascinating is that a whole class of algorithms for efficient probabilistic inference become obvious when recast on top of an inference tree. For example:
- Variable and bucket elimination corresponds to memoizing continuations,
- Rejection sampling corresponds to randomly traversing paths down our tree, discarding samples that result in contradictions (
fail), and - Importance sampling corresponds to randomly traversing a path but switching to another branch if one branch fails.
Being a shallow embedding, we unfortunately can’t do things like compare if two continuations are equal or do complex code analysis. But some preliminary experimental results show that this approach is competitive with existing, custom built inference engines.
There’s a bigger story to be told here, one about DSL compilers, where we give users the tools to easily implement their own languages, thereby increasing their expressiveness and productivity, but also allow them to implement their own optimizations, thereby not trading away speed that usually is associated with just writing an interpreter for your language. We’d like to leverage the existing compiler framework but add enhancements for our own problem domain as appropriate. We’d like to give behavioral specifications for our problem domains and teach the compiler how to figure out the details. It’s not feasible to write a compiler that fits everyone, but everyone can have the compiler spirit in them—and I think that will have an exciting and liberating effect on software engineering.
September 20, 2010This post is not meant as a rag on Darcs, just a observation of the difference between two philosophies of version control. Also, I’m a bit new to Darcs, so there might be some factual inaccuracies. Please let me know about them!
At some point, I would like to write a Darcs for Git users guide, distilling my experiences as an advanced Git user wrangling with Darcs. But perhaps the most important take away point is this: don’t try to superimpose Git’s underlying storage model on Darcs! Once I realized this point, I found Darcs fit rather nicely with my preferred Git development style—constant rebasing of local patches until they hit the official repository.
How does this rebasing workflow work? Despite the funny name, it’s a universal workflow that predates version control: the core operation is submit a patch. That is, after you’re done hacking and recompiling and you’ve cleaned up your changes, you pull up the original copy of the repository, generate a unified diff, and send it off to the official mailing list. If the unified diff doesn’t apply cleanly to whatever the official development version is, upstream will ask you to make the patch apply to the newer version of the software.
Git streamlines this workflow with rebases. As the name suggests, you are changing the base commit that your patches are applied to. The identity of the patch is more important than the actual “history” of the repository. Interactive rebases allow you to reorder patches, and slice and dice history into something pretty for upstream to read.
Because Git supports both tree-based and patch-based workflows, the tension between the two schools of thought is fairly evident. Old commit objects become unreachable when you rebase, and you have to rely on mechanisms like the reflog to retrieve your old trees. Good practice is to never rebase published repositories, because once you’ve published a consistent history is more important than a pretty one.
Darcs only supports the patch-based workflow. It’s hard to keep your patches nicely ordered like you must do when you rebase, but there’s no need to: darcs send --dry-run will let you know what local patches that haven’t been put into the upstream repository are floating around, and essentially every interesting command asks you to explicitly specify what patch you are referring to with -p. Darcs makes it easy to merge and split patches, and edit old patches even if they’re deep within your darcs changes log.
However, there are times when I really do miss the tree-based model: in particular, while it’s easy to get close, there’s no easy way to get precisely the makeup of the repository as it was two days ago (when, say, your build was still working). The fact that Git explicitly reifies any given state your repository is in as a tree object makes the patch abstraction less fluid, but means you will never ever lose committed data. Unfortunately, with Darcs, there is no shorthand for “this particular repository state”; you might notice the patches that darcs send have to explicitly list every patch that came before the particular patch you’re sending out. In this way, I think Darcs is doing too much work: while the most recent N changes should be thought of as patches and not tree snapshots, I probably don’t care about the ancient history of the project. Darcs already supports this with tags, but my experience with fast moving repositories like GHC indicates to me that you also want a timeline of tags tracking the latest “official” repository HEAD.
There is also the subject of conflict resolution, but as I have not run into any of the complicated cases, I have little to say here.
September 17, 2010While I was studying session type encodings, I noticed something interesting: the fact that session types, in their desire to capture protocol control flow, find themselves implementing something strongly reminiscent of dependent types.
Any reasonable session type encoding requires the ability to denote choice: in Simon Gay’s paper this is the T-Case rule, in Neubauer and Thiemann’s work it is the ALT operator, in Pucella and Tov’s implementation it is the :+: type operator, with the offer, sel1 and sel2 functions. There is usually some note that a binary alternation scheme is—in terms of user interface—inferior to some name-based alternation between an arbitrary number of cases, but that the latter is much harder to implement.
What the authors of these papers were really asking for was support for something that smells like dependent types. This becomes far more obvious when you attempt to write a session type encoding for an existing protocol. Consider the following tidbit from Google’s SPDY:
Once a stream is created, it can be used to send arbitrary amounts of data. Generally this means that a series of data frames will be sent on the stream until a frame containing the FLAG_FIN flag is set. The FLAG_FIN can be set on a SYN_STREAM, SYN_REPLY, or a DATA frame. Once the FLAG_FIN has been sent, the stream is considered to be half-closed.
The format for a data frame is:
+----------------------------------+
|C| Stream-ID (31bits) |
+----------------------------------+
| Flags (8) | Length (24 bits) |
+----------------------------------+
| Data |
+----------------------------------+
Whereas offer is implemented by transmitting a single bit across the network, here, the critical bit that governs whether or not the stream will be closed is embedded deep inside the data. Accordingly, if I even want to consider writing a session type encoding, I have to use a data definition with an extra phantom type in it, and not the obvious one:
data DataFrame fin = DataFrame StreamId FlagFin Data
I’ve had to promote FlagFin from a regular term into a type fitting into the fin hole, something that smells suspiciously of dependent types. Fortunately, the need for dependent types is averted by the fact that the session type will immediately do a case split on the type, accounting for both the case in which it is true and the case in which it is false. We don’t know at compile time what the value will actually be, but it turns out we don’t care! And if we are careful to only permit fin to be TrueTy when FlagFin is actually True, we don’t even need to have FlagFin as a field in the record.
This observation is what I believe people are alluding to when they say that you can go pretty far with type tricks without resorting to dependent types. Pushing compile-time known values into types is one obvious example (Peano integers, anyone?), but in this case we place compile-time unknown values into the types just by dealing with all possible cases!
Alas, actually doing this in Haskell is pretty awkward. Consider some real-world algebraic data type, a simplified version of the SPDY protocol that only allows one stream at a time:
data ControlFrame = InvalidControlFrame
| SynStream FlagFin FlagUnidirectional Priority NameValueBlock
| SynReply FlagFin NameValueBlock
| RstStream StatusCode
| Settings FlagSettingsClearPreviouslyPersistedSettings IdValuePairs
| NoOp
| Ping Word32
| Headers NameValueBlock
| WindowUpdate DeltaWindowSize
Each constructor needs to be turned into a type, as do the FlagFin, but it turns out the other data doesn’t matter for the session typing. So we end up writing a data declaration for each constructor, and no good way of stitching them back together:
data RstStream
data SynStream fin uni = SynStream Priority NameValueBlock
data SynReply fin = SynReply NameValueBlock
...
The thread we are looking for here is subtyping, specifically the more exotic sum-type subtyping (as opposed to product-type subtyping, under the more usual name record subtyping). Another way of thinking about this is that our type now represents a finite set of possible terms that may inhabit a variable: as our program evolves, more and more terms may inhabit this variable, and we need to do case-splits to cut down the possibilities to a more manageable size.
Alas, I hear that subtyping gunks up inference quite a bit. And, alas, this is about as far as I have thought it through. Doubtless there is a paper that exists out there somewhere that I ought to read that would clear this up. What do you think?
September 15, 2010Edward continues his spree of systems posts. Must be something in the Boston air.
Yesterday, I gave a SIPB cluedump on the use and implementation of scripts.mit.edu, the shared host service that SIPB provides to the MIT community. I derive essentially all of my sysadmin experience points from helping maintain this service.
Scripts is SIPB’s shared hosting service for the MIT community. However, it does quite a bit more than your usual $10 host: what shared hosting services integrate directly with your Athena account, replicate your website on a cluster of servers managed by Linux-HA, let you request hostnames on *.mit.edu, or offer automatic installs of common web software, let you customize it, and still upgrade it for you? Scripts is a flourishing development platform, with over 2600 users and many interesting technical problems.
I ended up splitting up the talk into two segments: a short Scripts for Power Users presentation, and a longer technical piece named Evolution of a Shared Web Host. There was also a cheatsheet handout passed out in the talk.
Among the technologies discussed in this talk include Apache, MySQL, OpenAFS, Kerberos, LDAP and LVS.
September 13, 2010Keyword arguments are generally considered a good thing by language designers: positional arguments are prone to errors of transposition, and it’s absolutely no fun trying to guess what the 37 that is the third argument of a function actually means. Python is one language that makes extensive use of keyword arguments; they have the following properties:
- Functions are permitted to be a mix of positional and keyword arguments (a nod to the compactness of positional arguments),
- Keywords are local to any given function; you can reuse a named function argument for another function,
- In Python 3.0, you can force certain arguments to only be specifiable with a keyword.
Does Haskell have keyword arguments? In many ways, they’re much less necessary due to the static type system: if you accidentally interpose an Int and Bool your compiler will let you know about it. The type signature guides you!
Still, if we were to insist (perhaps our function took many arguments of the same type), one possibility is to pass a record data type in as the sole argument, but this is a little different than Python keyword arguments in the following ways:
- There is a strict delineation between positional and keywords: either you can specify your record entirely with keywords or entirely with positional arguments, but you can’t do both,
- Record fields go into the global namespace, so you have to prefix/suffix them with some unique identifier, and
- Even with named records, a user can still choose to construct the record without specifying keyword arguments. For large argument lists, this is not as much of an issue, but for short argument lists, the temptation is great.
I find issue two to be the reason why I don’t really employ this trick; I would find it quite annoying to have to make a data structure for every function that I wanted to use named arguments with.
I’d like to suggest another trick to simulate named arguments: use newtypes! Consider this undertyped function:
renderBox :: Int -> Int -> Int -> Int -> IO ()
renderBox x y width height = undefined
main = renderBox 2 4 50 60
We can convert it to use newtypes like this:
newtype XPos = XPos Int
newtype YPos = YPos Int
newtype Width = Width Int
newtype Height = Height Int
renderBox :: XPos -> YPos -> Width -> Height -> IO ()
renderBox (XPos x) (YPos y) (Width width) (Height height) = undefined
main = renderBox (XPos 2) (YPos 4) (Width 50) (Height 60)
Unlike the usual use of newtypes, our newtypes are extremely short-lived: they last just long enough to get into the body of renderBox and then they are pattern matched to oblivion: the function body can rely on good local variable names to do the rest. But it still manages to achieve the goals of keyword arguments: any call to renderBox makes it crystal clear what each integer means. We also maintain the following good properties:
- If the type already says all you need to say about an argument, there’s no need to newtype it again. Thus, you can have a mix of regular and newtype arguments.
- Newtypes can be reused. Even further, they are only to be reused when the semantic content of their insides is the same, which encourages good naming practices.
- The user is forced to do the newtype wrapping: there’s no way around it. If you publish smart constructors instead of the usual constructors, you can factor out validation too.
Newtypes are so versatile!
September 10, 2010Last post, I talked about some of the notable difficulties in emulating pthread_cancel on Windows. Today, I want to talk about what a platform agnostic compiler like GHC actually ought to do. Recall our three design goals:
- GHC would like to be able to put blocking IO calls on a worker thread but cancel them later; it can currently do this on Linux but not on Windows,
- Users would like to write interrupt friendly C libraries and have them integrate seamlessly with Haskell’s exception mechanism, and
- We’d like to have the golden touch of the IO world, instantly turning blocking IO code into nice, well-behaved, non-blocking, interruptible code.
I am going to discuss these three situations, described concisely as blocking system calls, cooperative libraries and blocking libraries. I propose that, due to the lack of a cross-platform interruption mechanism, the correct interruptibility interface is to permit user defined handlers for asynchronous exceptions.
Interruptible blocking system calls. In the past, GHC has had some bugs in which a foreign call to a blocking IO system call caused Windows to stop being interruptible. This is a long standing difference in asynchronous IO philosophy between POSIX and Windows: POSIX believes in functions that look blocking but can be interrupted by signals, while Windows believes in callbacks. Thus, calls that seem harmless enough actually break interruptibility and have to be rewritten manually into a form amenable to both the POSIX and Windows models of asynchrony.
While it is theoretically and practically possible to manually convert every blocking call (which, by the way, works perfectly fine on Linux, because you can just send it a signal) into the asynchronous version, but this is very annoying and subverts the idea that we can simply ship blocking calls onto another thread to pretend that they’re nonblocking.
Since Windows Vista, we can interrupt blocking IO calls using a handy new function CancelSynchronousIo. Notice that cancelling IO is not the same as cancelling a thread: in particular, the synchronous operation merely returns with a failure with the last error set to ERROR_OPERATION_ABORTED, so the system call needs to have been performed directly by GHC (which can then notice the aborted operation and propagate the interrupt further) or occur in C code that can handle this error condition. Unfortunately, this function does not exist on earlier versions of Windows.
Aside. Is there anything we can do for pre-Vista Windows? Not obviously: the under-the-hood changes that were made to Windows Vista were partially to make a function like CancelSynchronousIo possible. If we were to enforce extremely strong invariants on when we call TerminateThread; that is, we’d have to manually vet every function we consider for termination, and at that point, you might as well rewrite it asynchronous style.
Interruptible cooperative libraries. This is the situation where we have a C library that we have a high level of control over: it may be our own library or we may be writing a intermediate C layer between GHC and an expressive, asynchronous underlying library. What we would like to do is have GHC seamlessly convert its asynchronous exceptions into some for that our C can notice and act gracefully upon.
As you may have realized by now, there are a lot of ways to achieve this:
- Signals. POSIX only, signals can be temporarily blocked with
sigprocmask or pthread_sigmask and a signal handler can be installed with sigaction to cleanup and possible exit the thread or long jump. - Pthread cancellation. POSIX only, cancellation can be temporarily blocked with
pthread_setcanceltype and a cancellation handler can be installed with pthread_cleanup_push. - Select/poll loop. Cancellation requests are sent over a socket which is being polled, handler can choose to ignore them.
- Event objects. Windows only, threads can receive cancellation requests from the handle from
OpenEvent but choose to ignore them. - IO cancellation. Windows Vista only, as described above.
- Completion queue. Windows only, similar to select/poll loop.
It doesn’t make much sense to try to implement all of these mechanisms natively. Therefore, my proposal: have GHC call a user-defined function in a different thread upon receipt of an asynchronous function and let the user figure out what to do. In many ways, this is not much of a decision at all: in particular, we’ve asked the programmer to figure it out for themselves. Libraries that only worked with POSIX will still only work with POSIX. However, this is still an advance from the current state, which is that asynchronous exceptions necessarily behave differently for Haskell and FFI code.
Interruptible blocking libraries. Because blocking IO is much easier to program than non-blocking IO, blocking interfaces tend to be more prevalent and better tested. (A friend of mine who spent the summer working on Chromium had no end of complaints about the bugginess of the non-blocking interface to NSS.) It might be practical to rewrite a few system calls into asynchronous style, but when you have a blob of existing C code that you want to interface with, the maintenance cost of such a rewrite quickly becomes untenable. What is one to do?
Alas, there is no magic bullet: if the library never had any consideration for interruptibility, forcibly terminating it is more than likely to leave your program in a corrupted state. For those who would like to play it fast and loose, however, the user-defined function approach would still let you call TerminateThread if you really wanted to.
In conclusion, I propose that the interruptibility patch be extended beyond just a simple interruptible keyword to allow a user-defined asynchronous exception handler, compiled against the RTS, as well as providing a few built-in handlers which provide sensible default behaviors (both platform specific and non-platform specific, though I expect the latter to give much weaker guarantees).