November 17, 2010Ever try to go to haskell.org and notice that it was down? Well, now you have someone to complain to: the haskell.org committee has formed and apparently I’m on it. 8-)
One of the first things we’ll be doing is moving haskell.org from a server being hosted at Yale (the hosting has been good, but what will happen is the server will go down during the weekend and there will be no one to kick it until Monday) to some dedicated hardware. I must admit, I do feel a bit sheepish for being on the committee but not having any bits (or direct experience) to help do the maintenance work—hopefully that will change soon.
November 15, 2010And then a signal to the ri-i-i-ight.
One notable wart with readline is that if you ^C during the prompt, nothing happens, and if you do a second ^C (and weren’t buggering around with the signal handlers) your entire program unceremoniously terminates. That’s not very nice! Fortunately, readline appears to be one of the rare C libraries that actually put some work into making sure that you could longjmp out of a signal handler and not completely break the library’s internal state (they do this with liberal masking and unmasking, and their own signal handler which cleans up and then rethrows the signal).
So I decided I was going to see if I could patch up readline to longjmp out of the signal handler (signal provided by yours truly) and give control back to Haskell. This monstrosity resulted.
static jmp_buf hs_readline_jmp_buf;
static struct sigaction old_sigpipe_action;
void hs_readline_sigaction (int signo, siginfo_t *info, void *data)
{
sigaction(SIGALRM, &old_sigpipe_action, NULL);
siglongjmp(hs_readline_jmp_buf, signo);
}
char *hs_readline (const char *s)
{
struct sigaction action;
int signo;
sigset_t mask;
memset(&action, 0, sizeof(struct sigaction));
sigemptyset(&mask);
sigaddset(&mask, SIGALRM);
action.sa_sigaction = hs_readline_sigaction;
action.sa_mask = mask;
action.sa_flags = SA_RESETHAND;
sigaction(SIGALRM, &action, &old_sigpipe_action);
if (signo = sigsetjmp(hs_readline_jmp_buf, 1)) {
return NULL;
}
char *r = readline(s);
sigaction(SIGALRM, &old_sigpipe_action, NULL);
return r;
}
It actually works pretty wonderfully, despite the somewhat circuitous route the signal takes: the SIGINT will first get handled by readline’s installed signal handler, which will clean up changes to the terminal and then rethrow it to GHC’s signal handler. GHC will tell the IO manager that a signal happened, and then go back to the innards of readline (who reinstates all changes in the terminal). Then, the IO manager reads out the signal, and sends a ThreadKilled exception, which then results in the RTS trying to interrupt the foreign call. The SIGALRM (actually, that’s a lie, the code that’s in GHC sends a SIGPIPE, but readline doesn’t think a SIGPIPE is a signal it should cleanup after, so I changed it—better suggestions welcome) hits readline’s signal handler again, we clean up the terminal, and then we hit our signal handler, which longjmps to a return NULL which will take us back to Haskell. And then the signal is caught and there is much rejoicing.
Unfortunately, almost all of that code is boilerplate and I can’t stick it in a nice Haskell combinator because the when Haskell is executing there’s no stack to speak of, and I bet a setjmp FFI call would make the RTS very confused. It’s also not reentrant although I doubt readline is reentrant either. And of course, nonlocal control transfer from a signal handler is something your Mom always told you not to do. So this approach probably doesn’t generalize. But it’s pretty amusing.
November 12, 2010About a month ago I decided that it would be cool if I could solve the bug GHC’s runtime never terminates unused worker threads. Well, I just got around to looking at it today, and after wandering aimlessly around the twisty maze that is the GHC RTS for an hour or so, I finally found a light at the end of a tunnel, in the form of a heart-warmingly simple patch. I’ve sent mail off to Simon Marlow to make sure the light isn’t actually a train, but it occurred to me that it would be interesting to look at my command history and blog about the process by which I came to the conclusion that line 464 of Capability.c was the correct place to add my change, since this sort of mental journey is not the one that is really ever recorded anywhere in any shape or form.
Warmups before running the maze. In a shifty shifty maze like GHC, you want to make sure the guided route (i.e. a clean build) is working before trying anything fancy. I use a separate build tree from source tree, so getting everything up to date involves:
cd ghc-clean
./darcs-all get
./darcs-all pull -a
cd ../ghc-build
lndir ../ghc-clean
perl boot && ./configure && make
inplace/bin/ghc-stage2 --interactive
When this has been resolved in a satisfactory manner (a non-trivial task for platforms with Windows), the code hunting can begin.
Grab your equipment. What? You mean to say you’ve wandered into this maze and you don’t even know how to tell you’ve gotten to your destination? That’s no good… you’ll need a dousing rod of some sort… something to tell you when you’ve got it right.
In this particular case, the original bug reporter had written up a small, incomplete test script, so the first thing I did was flesh it out into a script that required no human interaction. The benchmark for the new script was clear: /proc/PID/task should report a number substantially smaller than 200. To see that the current implementation is broken:
ezyang@javelin:~/Dev/ghc-build/testsuite/tests/ghc-regress/ffi/should_run$ ./cleanupThreads
203
Getting your bearings. Ok, so what do we want? We want threads to die instead of hanging around. There are two ways to do this: have the thread commit seppuku when it realizes it isn’t wanted, or have some manager kill the thread as necessary. The later is generally considered poor form, since you want to make sure the threads aren’t doing anything critical that will get corrupted if they die. So seppuku it is. Here, now, there are two questions:
- When does the thread decide to go into a waiting pool? This is presumably where we’d want it to terminate itself instead.
- How would the thread decide whether or not it should hang around or bug out?
Mapping out the land. GHC has this little runtime flag called -Ds. It’s pretty useful: it dumps out a whole gaggle of debug information concerning threads, which is precisely what we’d like to look for. Our plan of action is to look at what the thread activity looks like in our test script, and identify the points at which threads should be dying instead of hanging around.
The very beginning of the log looks like this:
b75006d0: allocated 1 capabilities
b75006d0: new task (taskCount: 1)
b75006d0: returning; I want capability 0
b75006d0: resuming capability 0
b75006d0: starting new worker on capability 0
b75006d0: new worker task (taskCount: 2)
b75006d0: task exiting
b75006d0: new task (taskCount: 2)
b75006d0: returning; I want capability 0
b71ffb70: cap 0: schedule()
b71ffb70: giving up capability 0
Note the number b75006d0; that’s our main thread and it’s going to be quite a busy beaver. Here is the very first thread we spin off to make a foreign call, but it finishes fairly quickly and isn’t the foreign call we are looking for:
b75006d0: cap 0: created thread 1
b75006d0: cap 0: thread 1 appended to run queue
b75006d0: new bound thread (1)
b75006d0: cap 0: schedule()
b75006d0: cap 0: running thread 1 (ThreadRunGHC)
b75006d0: cap 0: thread 1 stopped (suspended while making a foreign call)
b75006d0: freeing capability 0
b75006d0: returning; I want capability 0
b75006d0: resuming capability 0
b75006d0: cap 0: running thread 1 (ThreadRunGHC)
b75006d0: cap 0: thread 1 stopped (suspended while making a foreign call)
b75006d0: freeing capability 0
b75006d0: returning; I want capability 0
b75006d0: resuming capability 0
b75006d0: cap 0: running thread 1 (ThreadRunGHC)
b75006d0: cap 0: created thread 2
b75006d0: cap 0: thread 2 appended to run queue
b75006d0: cap 0: thread 1 stopped (finished)
Not before long, we see a veritable avalanche of new threads being created and added to the run queue—these are our threads:
b75006d0: woken up on capability 0
b75006d0: resuming capability 0
b75006d0: cap 0: running thread 3 (ThreadRunGHC)
b75006d0: cap 0: created thread 4
b75006d0: cap 0: thread 4 appended to run queue
b75006d0: cap 0: created thread 5
b75006d0: cap 0: thread 5 appended to run queue
b75006d0: cap 0: created thread 6
b75006d0: cap 0: thread 6 appended to run queue
b75006d0: cap 0: created thread 7
b75006d0: cap 0: thread 7 appended to run queue
b75006d0: cap 0: created thread 8
b75006d0: cap 0: thread 8 appended to run queue
b75006d0: cap 0: created thread 9
b75006d0: cap 0: thread 9 appended to run queue
b75006d0: cap 0: created thread 10
b75006d0: cap 0: thread 10 appended to run queue
b75006d0: cap 0: created thread 11
b75006d0: cap 0: thread 11 appended to run queue
b75006d0: cap 0: created thread 12
b75006d0: cap 0: thread 12 appended to run queue
b75006d0: cap 0: created thread 13
The process continues until we’ve spawned them all:
54139b70: starting new worker on capability 0
54139b70: new worker task (taskCount: 201)
53938b70: cap 0: schedule()
53938b70: cap 0: running thread 202 (ThreadRunGHC)
53938b70: cap 0: thread 202 stopped (suspended while making a foreign call)
53938b70: starting new worker on capability 0
53938b70: new worker task (taskCount: 202)
53137b70: cap 0: schedule()
53137b70: cap 0: running thread 203 (ThreadRunGHC)
53137b70: cap 0: thread 203 stopped (suspended while making a foreign call)
53137b70: starting new worker on capability 0
53137b70: new worker task (taskCount: 203)
52936b70: cap 0: schedule()
And then, since there’s nothing to do (all of our threads are in FFI land), we go and run a major GC:
52936b70: woken up on capability 0
52936b70: resuming capability 0
52936b70: deadlocked, forcing major GC...
52936b70: cap 0: requesting parallel GC
52936b70: ready_to_gc, grabbing GC threads
all threads:
threads on capability 0:
other threads:
thread 203 @ 0xb72b5c00 is blocked on an external call (TSO_DIRTY)
thread 202 @ 0xb72b5800 is blocked on an external call (TSO_DIRTY)
thread 201 @ 0xb72b5400 is blocked on an external call (TSO_DIRTY)
thread 200 @ 0xb72b5000 is blocked on an external call (TSO_DIRTY)
thread 199 @ 0xb72b4c00 is blocked on an external call (TSO_DIRTY)
thread 198 @ 0xb72b4800 is blocked on an external call (TSO_DIRTY)
thread 197 @ 0xb72b4400 is blocked on an external call (TSO_DIRTY)
thread 196 @ 0xb72b4000 is blocked on an external call (TSO_DIRTY)
thread 195 @ 0xb72b3c00 is blocked on an external call (TSO_DIRTY)
thread 194 @ 0xb72b3800 is blocked on an external call (TSO_DIRTY)
thread 193 @ 0xb72b3400 is blocked on an external call (TSO_DIRTY)
[snip (you get the idea)]
(I’ve always kind of wondered whether or not FFI calls should be considered deadlocked.)
Now the threads start coming back from FFI-land and idling:
b69feb70: cap 0: running thread 4 (ThreadRunGHC)
b69feb70: cap 0: waking up thread 3 on cap 0
b69feb70: cap 0: thread 3 appended to run queue
b69feb70: cap 0: thread 4 stopped (finished)
b69feb70: giving up capability 0
b69feb70: there are 2 spare workers
b69feb70: passing capability 0 to bound task 0xb75006d0
b61fdb70: returning; I want capability 0
b61fdb70: resuming capability 0
b61fdb70: cap 0: running thread 5 (ThreadRunGHC)
b59fcb70: returning; I want capability 0
b61fdb70: cap 0: thread 5 stopped (finished)
b61fdb70: giving up capability 0
b61fdb70: there are 3 spare workers
b61fdb70: passing capability 0 to worker 0xb59fcb70
b75006d0: woken up on capability 0
b75006d0: capability 0 is owned by another task
b51fbb70: returning; I want capability 0
b59fcb70: resuming capability 0
b59fcb70: cap 0: running thread 6 (ThreadRunGHC)
b59fcb70: cap 0: thread 6 stopped (finished)
b59fcb70: giving up capability 0
b49fab70: returning; I want capability 0
b59fcb70: there are 4 spare workers
b59fcb70: passing capability 0 to worker 0xb51fbb70
b51fbb70: resuming capability 0
b51fbb70: cap 0: running thread 7 (ThreadRunGHC)
b51fbb70: cap 0: thread 7 stopped (finished)
b51fbb70: giving up capability 0
b41f9b70: returning; I want capability 0
b51fbb70: there are 5 spare workers
I’ve actually cheated a little: the there are X spare workers debug statements I added myself. But this section is golden; we’re specifically interested in these lines:
b61fdb70: cap 0: thread 5 stopped (finished)
b61fdb70: giving up capability 0
The thread stops, but it doesn’t die, it just gives up the capability. These are two extremely good candidates for where the thread might alternately decide to kill itself.
Placemarkers. It’s time to bust out the trusty old grep and figure out where these debug messages are being emitted from. Unfortunately, 5 and finished are probably dynamically generated messages, so stopped is the only real identifier. Fortunately, that’s specific enough for me to find the right line in the RTS:
ezyang@javelin:~/Dev/ghc-clean/rts$ grep -R stopped .
./Capability.c: // list of this Capability. A worker can mark itself as stopped,
./Capability.c: if (!isBoundTask(task) && !task->stopped) {
./RaiseAsync.c: - all the other threads in the system are stopped (eg. during GC).
./RaiseAsync.c: // if we got here, then we stopped at stop_here
./Task.c: if (task->stopped) {
./Task.c: task->stopped = rtsFalse;
./Task.c: task->stopped = rtsFalse;
./Task.c: task->stopped = rtsTrue;
./Task.c: task->stopped = rtsTrue;
./Task.c: debugBelch("task %p is %s, ", taskId(task), task->stopped ? "stopped" : "alive");
./Task.c: if (!task->stopped) {
./sm/GC.c: // The other threads are now stopped. We might recurse back to
./Schedule.c: "--<< thread %ld (%s) stopped: requesting a large block (size %ld)\n",
./Schedule.c: "--<< thread %ld (%s) stopped to switch evaluators",
./Schedule.c: // stopped. We need to stop all Haskell threads, including
./Trace.c: debugBelch("cap %d: thread %lu stopped (%s)\n", ### THIS IS THE ONE
./Task.h: rtsBool stopped; // this task has stopped or exited Haskell
./Task.h:// Notify the task manager that a task has stopped. This is used
./Task.h:// Put the task back on the free list, mark it stopped. Used by
./Interpreter.c: // already stopped at just now
./Interpreter.c: // record that this thread is not stopped at a breakpoint anymore
./win32/Ticker.c: // it still hasn't stopped.
That line in Trace.c is actually in a generic debugging function traceSchedEvent_stderr, but fortunately there’s a big case statement on one of its arguments tag:
case EVENT_STOP_THREAD: // (cap, thread, status)
debugBelch("cap %d: thread %lu stopped (%s)\n",·
cap->no, (lnat)tso->id, thread_stop_reasons[other]);
break;
So EVENT_STOP_THREAD is a good next grep. And sure enough:
ezyang@javelin:~/Dev/ghc-clean/rts$ grep -R EVENT_STOP_THREAD .
./Trace.c: case EVENT_STOP_THREAD: // (cap, thread, status)
./eventlog/EventLog.c: [EVENT_STOP_THREAD] = "Stop thread",
./eventlog/EventLog.c: case EVENT_STOP_THREAD: // (cap, thread, status)
./eventlog/EventLog.c: case EVENT_STOP_THREAD: // (cap, thread, status)
./Trace.h: HASKELLEVENT_STOP_THREAD(cap, tid, status)
./Trace.h: traceSchedEvent(cap, EVENT_STOP_THREAD, tso, status);
It looks to be an inline function in Trace.h:
INLINE_HEADER void traceEventStopThread(Capability *cap STG_UNUSED,
StgTSO *tso STG_UNUSED,
StgThreadReturnCode status STG_UNUSED)
{
traceSchedEvent(cap, EVENT_STOP_THREAD, tso, status);
dtraceStopThread((EventCapNo)cap->no, (EventThreadID)tso->id,
(EventThreadStatus)status);
}
Classy. So traceEventStopThread is the magic word, and sure enough:
ezyang@javelin:~/Dev/ghc-clean/rts$ grep -R traceEventStopThread .
./Schedule.c: traceEventStopThread(cap, t, ret);
./Schedule.c: traceEventStopThread(cap, tso, THREAD_SUSPENDED_FOREIGN_CALL);
./Trace.h:INLINE_HEADER void traceEventStopThread(Capability *cap STG_UNUSED,
There are two plausible sites in Schedule.c.
Going digging. We first have to pick which site to inspect more closely. Fortunately, we notice that the second trace event corresponds to suspending the thread before going into a safe FFI call; that’s certainly not what we’re looking at here. Furthermore, the first is in the scheduler, which makes a lot of sense. But there’s nothing obvious in this vicinity that you might associate with saving a worker task away due to lack of work.
What about that giving up capability message? Some more grepping reveals it to be in the yieldCapability function (like one might expect). If we then trace backwards calls to yieldCapability, we see it is invoked by scheduleYield, which is in turn called by the scheduler loop:
scheduleYield(&cap,task);
if (emptyRunQueue(cap)) continue; // look for work again
// Get a thread to run
t = popRunQueue(cap);
This is very, very interesting. It suggests that the capability itself will tell us whether or not the work to do, and that yieldCapability is a promising function to look further into:
debugTrace(DEBUG_sched, "giving up capability %d", cap->no);
// We must now release the capability and wait to be woken up
// again.
task->wakeup = rtsFalse;
releaseCapabilityAndQueueWorker(cap);
That last call looks intriguing:
static void
releaseCapabilityAndQueueWorker (Capability* cap USED_IF_THREADS)
{
Task *task;
ACQUIRE_LOCK(&cap->lock);
task = cap->running_task;
// If the current task is a worker, save it on the spare_workers
// list of this Capability. A worker can mark itself as stopped,
// in which case it is not replaced on the spare_worker queue.
// This happens when the system is shutting down (see
// Schedule.c:workerStart()).
if (!isBoundTask(task) && !task->stopped) {
task->next = cap->spare_workers;
cap->spare_workers = task;
}
// Bound tasks just float around attached to their TSOs.
releaseCapability_(cap,rtsFalse);
RELEASE_LOCK(&cap->lock);
}
We’ve found it!
Checking the area. The spare_workers queue looks like the queue in which worker threads without anything to do go to chill out. We should verify that this is the case:
int i;
Task *t;
for (i = 0, t = cap->spare_workers; t != NULL; t = t->next, i++) {}
debugTrace(DEUBG_sched, "there are %d spare workers", i);
Indeed, as we saw in the debug statements above, this was indeed the case: the number of spare workers kept increasing:
54139b70: there are 199 spare workers
54139b70: passing capability 0 to worker 0x53938b70
53938b70: resuming capability 0
53938b70: cap 0: running thread 202 (ThreadRunGHC)
53938b70: cap 0: thread 202 stopped (blocked)
thread 202 @ 0xb727a400 is blocked on an MVar @ 0xb72388a8 (TSO_DIRTY)
53938b70: giving up capability 0
53938b70: there are 200 spare workers
53938b70: passing capability 0 to worker 0x53137b70
53137b70: resuming capability 0
53137b70: cap 0: running thread 203 (ThreadRunGHC)
53137b70: cap 0: thread 203 stopped (blocked)
thread 203 @ 0xb727a000 is blocked on an MVar @ 0xb72388a8 (TSO_DIRTY)
53137b70: giving up capability 0
53137b70: there are 201 spare workers
Writing up the solution. So, the patch from here is simple, since we’ve found the correct location. We check if the queue of spare workers is at some number, and if it is, instead of saving ourselves to the queue we just cleanup and then kill ourselves:
for (i = 1; t != NULL && i < 6; t = t->next, i++) {}
if (i >= 6) {
debugTrace(DEBUG_sched, "Lots of spare workers hanging around, terminating this thread");
releaseCapability_(cap,rtsFalse);
RELEASE_LOCK(&cap->lock);
pthread_exit(NULL);
}
And then we test see that this indeed has worked:
ezyang@javelin:~/Dev/ghc-build/testsuite/tests/ghc-regress/ffi/should_run$ ./cleanupThreads
7
Postscript. There are some obvious deficiencies with this proof-of-concept. It’s not portable. We need to convince ourselves that this truly does all of the cleanup that the RTS expects a worker to do. Maybe our data representation could be more efficient (we certainly don’t need a linked list if the number of values we’ll be storing is fixed.) But these are questions best answered by someone who knows the RTS better, so at this point I sent in the proof of concept for further review. Fingers crossed!
November 10, 2010This is a post to get some Google juice for a problem that basically prevented Scripts from being able to cut over from Fedora 11 to Fedora 13. The cluster of new machines kept falling over from load, and we kept scratching our heads, wondering, “Why?”
Turns out, the following commit broke mod_fcgid in a pretty terrifying way: essentially, mod_fcgid is unable to manage the pools of running FastCGI processes, so it keeps spawning new ones until the system runs out of memory. This is especially obvious in systems with large amounts of generated virtual hosts, i.e. people using mod_vhost_ldap. It got fixed in mod_fcgid 2.3.6, which was released last weekend.
Unrelatedly. I’ve been sort of turning around in my head a series of Philosophy of Computer Science posts, where I try to identify interesting philosophical questions in our field beyond the usual topics of discussion (cough AI cough.) The hope is to draw in a number of topics traditionally associated with philosophy of science, of mathematics, of biology, etc. and maybe pose a few questions of my own. One of the favorite pastimes of philosophers is to propose plausible sounding theories and then come up with perplexing examples which seem to break them down, and it sounds like this in itself could generate some Zen koans as well, which are always fun.
November 8, 2010This is a bit of a provocative post, and its impressions (I dare not promote them to the level of conclusions) should be taken with the amount of salt found in a McDonald’s Happy Meal. Essentially, I was doing some reading about medieval medicine and was struck by some of the similarities between it and computer engineering, which I attempt to describe below.
Division between computer scientists and software engineers. The division between those who studied medicine, the physics (a name derived from physica or natural science) and those who practiced medicine, the empirics, was extremely pronounced. There was a mutual distrust—Petrarch wrote, “I have never believed in doctors nor ever will” (Porter 169)—that stemmed in part from the social division between the physics and empirics. Physics would have obtained a doctorate from a university, having studied one of the highest three faculties possible (the others being theology and law), and tended to be among the upper strata of society. In fact, the actual art of medicine was not considered “worthy of study,” though the study of natural science was. (Cook 407).
The division between computer scientists and software engineers is not as bad as the corresponding division in the 1500s, but there is a definite social separation (computer scientists work in academia, software engineers work in industry) and a communication gap between these two communities. In many other fields, a PhD is required to be even considered for a job in your field; here, we see high school students starting up software companies (occasionally successfully) all the time, and if programming Reddit is any indication, there is a certain distaste for purely theoretical computer scientists.
The unsuitability of pure computer science for the real world. Though the study of pure medicine was highly regarded during this time, its theories and knowledge were tremendously off the mark. At the start of the 1500s the four humors of Hippocratic medicine were still widely believed: to be struck by disease was to have an imbalance of black bile, yellow bile, phlegm and blood, and thus the cure would be to apply the counteracting humor, and justified such techniques as bloodletting (the practice of purposely bleeding a person). Even the understanding of how the fundamentals of the human body worked were ill-understood: it was not until William Harvey and his De motu cordis et sanguinis (1628) that the earlier view that food was concocted in the organs and then flowed outwards via the veins, arteries and nerves to the rest of the body was challenged by the notion of the heart as a pump. (Cook 426) If the circulatory system was true, what did the other organs do? Harvey’s theory completely overturned the existing understanding of how the human body worked, and his theory was quite controversial.
I have enough faith in computer science that I don’t think most of our existing knowledge is fundamentally wrong. But I also think we know tremendously little about the actual nature of computation even at middling sizes, and this is a quite humbling fact. But I am also fundamentally optimistic about the future of computer science in dealing with large systems—more on this at the end.
Testing instead of formal methods. The lack of knowledge, however, did stop the physicians (as distinct from physics) from practicing their medicine. Even the academics recognized the importance of “medieval practica; handbooks listing disorders from head to toe with a description of symptoms and treatment.” (Porter 172) The observational (Hippocratic) philosophy, continued to hold great sway: Thomas Sydenham, when asked on the subject of dissection, stated “Anatomy—Botany—Nonsense! Sir, I know an old woman in Covent Garden who understand botany better, and as for anatomy, my butcher can dissect a joint full and well; now, young man, all that is stuff; you must go to the bedside, it is there alone you can learn disease.” (Porter 229)
In the absence of a convincing theoretical framework, empiricism rules. The way to gain knowledge is to craft experiments, conduct observations, and act accordingly. If a piece of code is buggy, how do you fix it? You add debug statements and observe the output, not construct a formal semantics and then prove the relevant properties. The day the latter is the preferred method of choice is a day when practitioners of formal methods across the world will rejoice.
No silver bullet. In the absence of reliable medical theories from the physics, quackery flourished in the eighteenth century, a century often dubbed the “Golden Age of Quackery.” (Porter 284) There was no need to explain why your wares worked: one simply needed to give a good show (“drawing first a crowd and then perhaps some teeth, both to the accompaniment of drums and trumpets” (Porter 285)), sell a few dozen bottles of your cure, and then move on to the next town. These “medicines” would claim to do anything from cure cancer to restore youth. While some of the quacks were merely charlatans, others earnestly believed in the efficacy of their treatments, and occasionally a quack remedy was actually effective.
I think the modern analogue to quackery are software methodology in all shapes in sizes. Like quack medicines, some of these may be effective, but in the absence of scientific explanations we can only watch the show, buy in, and see if it works. And we can’t hope for any better until our underlying theories are better developed.
The future. Modern medical science was eventually saved, though not before years of inadequate theories and quackery had brought it to a state of tremendous disrepute. The complexity of the craft had to be legitimized, but this would not happen until a powerful scientific revolution built the foundations of modern medical practice.
Works referenced:
- Porter, Roy. The Greatest Benefit To Mankind. Fontana Press: 1999.
- Park, Katherine; Daston, Lorraine. The Cambridge History of Science: Volume 3, Early Modern Science.
November 5, 2010Someone told me it’s all happening at the zoo…
I’ve always thought dynamic programming was a pretty crummy name for the practice of storing sub-calculations to be used later. Why not call it table-filling algorithms, because indeed, thinking of a dynamic programming algorithm as one that fills in a table is a quite good way of thinking about it.
In fact, you can almost completely characterize a dynamic programming algorithm by the shape of its table and how the data flows from one cell to another. And if you know what this looks like, you can often just read off the complexity without knowing anything about the problem.
So what I did was collected up a bunch of dynamic programming problems from Introduction to Algorithms and drew up the tables and data flows. Here’s an easy one to start off with, which solves the Assembly-Line problem:
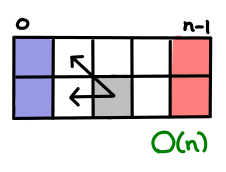
The blue indicates the cells we can fill in ‘for free’, since they have no dependencies on other cells. The red indicates cells that we want to figure out, in order to pick the optimal solution from them. And the grey indicates a representative cell along the way, and its data dependency. In this case, the optimal path for a machine to a given cell only depends on the optimal paths to the two cells before it. (Because, if there was a more optimal route, than it would have shown in my previous two cells!) We also see there are a constant number of arrows out of any cell and O(n) cells in this table, so the algorithm clearly takes O(n) time total.
Here’s the next introduction example, optimal parenthesization of matrix multiplication.
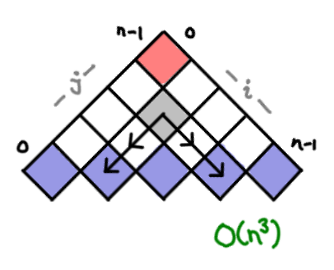
Each cell contains the optimal parenthesization of the subset i to j of matrixes. To figure this out the value for a cell, we have to consider all of the possible combos of existing parentheticals that could have lead to this (thus the multiple arrows). There are O(n²) boxes, and O(n) arrows, for O(n³) overall.
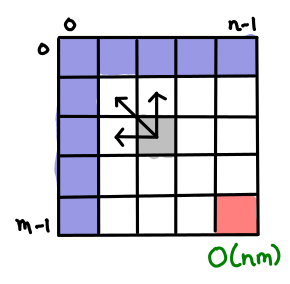
Here’s a nice boxy one for finding the longest shared subsequence of two strings. Each cell represents the longest shared subsequence of the first string up to x and the second string up to y. I’ll let the reader count the cells and arrows and verify the complexity is correct.
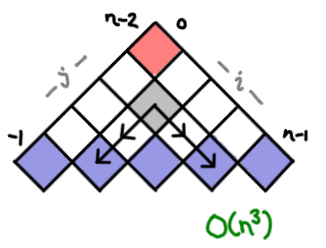
There aren’t that many ways to setup dynamic programming tables! Constructing optimal binary search trees acts a lot like optimal matrix parenthesization. But the indexes are a bit fiddly. (Oh, by the way, Introduction to Algorithms is 1-indexed; I’ve switched to 0-indexing here for my examples.)
Here we get into exercise land! The bitonic Euclidean traveling salesman problem is pretty well-known on the web, and its tricky recurrence relation has to do with the bottom edge. Each cell represents the optimal open bitonic route between i and j.
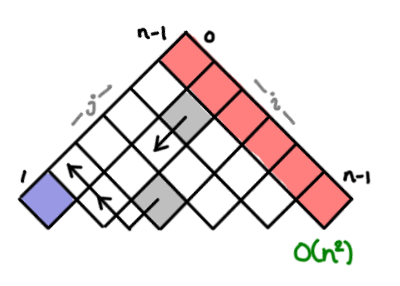
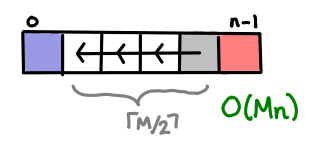
The lovely word wrapping problem, a variant of which lies at the heart of the Knuth TeX word wrapping algorithm, takes advantage of some extra information to bound the number of cells one has to look back. (The TeX algorithm does a global optimization, so the complexity would be O(n²) instead.) Each cell represents the optimal word wrapping of all the words up to that point.
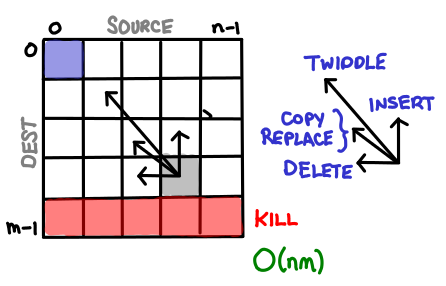
Finally, the edit problem, which seems like the authors decided to pile on as much complexity as they could muster, falls out nicely when you realize each string operation they order you to design corresponds to a single arrow to some earlier cell. Useful! Each cell is the optimal edit chain from that prefix of the source to that prefix of the destination.
And the zookeeper is very fond of rum.
Squares, triangles, rectangles, those were the tables I usually found. I’m curious to know if there are more exotic tables that DP algorithms have filled out. Send them in and I’ll draw them!
November 3, 2010Should software engineers be required to implement the abstractions use before using them? (Much like how before you’re allowed to use a theorem in a math textbook, you have to prove it first.) A bit like reinventing the wheel for pedagogical purposes.
(I’ve been sick since Saturday, so it’s a Dead Edward Day. Hopefully I’ll clean up the DP Zoo post and present it with more annotations for this Friday.)
November 1, 2010
October 29, 2010My parents like foisting various self-help books on me, and while I sometimes groan to myself about it, I do read (or at least skim) them and extract useful bits of information out of them. This particular title quote is from Robert Kiyosaki’s “rich dad” in Rich Dad, Poor Dad.
“Intelligence is the ability to make finer distinctions” really spoke to me. I’ve since found it to be an extremely effective litmus test to determine if I’ve really understood something. A recent example comes from my concurrent systems class, where there are many extremely similar methods of mutual exclusion: mutexes, semaphores, critical regions, monitors, synchronized region, active objects, etc. True knowledge entails an understanding of the conceptual details differentiating these gadgets. What are the semantics of a signal on a condition variable with no waiting threads? Monitors and synchronized regions will silently ignore the signal, thus requiring an atomic release-and-wait, whereas a semaphore will pass it on to the next wait. Subtle.
We can frequently get away with a little sloppiness of thinking, indeed, this is the mark of an expert: they know precisely how much sloppiness they can get away with. However, from a learning perspective, we’d like to be able to make as fine a distinction as possible, and hopefully derive some benefit (either in the form of deeper understanding or a new tool) from it.
Since this is, after all, an advocacy piece, how does learning Haskell help you make finer distinctions in software? You don’t have to look hard:
Haskell is a standardized, general-purpose purely functional programming language, with non-strict semantics and strong static typing.
These two bolded terms are concepts that Haskell asks you to make a finer distinction on.
Purity. Haskell requires you to make the distinction between pure code and input-output code. The very first time you get the error message “Couldn’t match expected type [a] against inferred type IO String” you are well on your way to learning this distinction. Fundamentally, it is the difference between computation and interaction with the outside world, and no matter how imperative your task is, both of these elements will be present in a program, frequently lumped together with no indication which is which.
Pure code confers tremendous benefits. It is automatically thread safe and asynchronous exception safe. It has no hidden dependencies with the outside world. It is testable and deterministic. The system can speculatively evaluate pure code with no commitment to the outside world, and can cache the results without fear. Haskellers have an obsession with getting as much code outside of IO as possible: you don’t have to go to such lengths, but even in small doses Haskell will make you appreciate how what is considered good engineering practice can be made rigorous.
Non-strict semantics. There are some things you take for granted, the little constants in life that you couldn’t possibly imagine be different. Perhaps if you stopped and thought about it, there was another way, but the possibility never occurred to you. Which side of the road you drive is one of these things; strict evaluation is another. Haskell asks you to distinguish between strict evaluation and lazy evaluation.
Haskell isn’t as in your face about this distinction as it is about purity and static typing, so it’s possible to happily hack along without understanding this distinction until you get your first stack overflow. At which point, if you don’t understand this distinction, the error will seem impenetrable (“but it worked in the other languages I know”), but if you are aware, a stack overflow is easily fixed—perhaps making the odd argument or data constructor explicitly strict.
Implicit laziness has a number of notable benefits. It permits user-level control structures. It encodes streams and other infinite data structures. It is more general* than strict evaluation. It is critical in the construction of amortized persistent data structures. (Okasaki) It also is not always appropriate to use: Haskell fosters an appreciation of the strengths and weaknesses of strictness and laziness.
* Well, almost. It only fully generalizes strict evaluation if you have infinite memory, in which case any expression that strictly evaluates also lazy evaluates, while the converse is not true. But in practice, we have such pesky things as finite stack size.
The downside. Your ability to make finer distinctions indicates your intelligence. But on the same token, if these distinctions don’t become second nature, they impose a cognitive overhead whenever you need invoke them. Furthermore, it makes it difficult for others who don’t understand the difference to effectively hack on your code. (Keep it simple!)
Managing purity is second-nature to experienced Haskellers: they’ve been drilled by the typechecker long enough to know what’s admissible and what’s not, and given the mystique of monads, it’s usually something people actively try to learn when starting off with Haskell. Managing strictness also comes easily to experienced Haskellers, but has what I perceive to be a higher learning curve: there is no strictness analyzer yelling at you when you make a suboptimal choice, and you can get away with not thinking about it most of the time. Some might say that lazy-by-default is not the right way to go, and are exploring the strict design space. I remain optimistic that we Haskellers can build up a body of knowledge and teaching techniques to induct novices into the mysteries and wonders of non-strict evaluation.
So there they are: purity and non-strictness, two distinctions that Haskell expects you to make. Even if you never plan on using Haskell for a serious project, getting a visceral feel for these two concepts will tremendously inform your other programming practice. Purity will inform you when you write thread-safe code, manage side-effects, handle interrupts, etc. Laziness will inform you when use generators, process streams, control structures, memoization, fancy tricks with function pointers, etc. These are seriously powerful engineering tools, and you owe it to yourself to check them out.
October 27, 2010…because I don’t live in a room numbered 245s anymore. Yep. :-)

This is a cow. They munch grass next to the River Cam.
Pop quiz. What do matrix-chain multiplication, longest common subsequence, construction of optimal binary search trees, bitonic euclidean traveling-salesman, edit distance and the Viterbi algorithm have in common?