December 10, 2010Between packing and hacking on GHC, I didn’t have enough time to cough up the next post of the series or edit the pictures for the previous post, so all you get today is a small errata post.
- The full list diagram is missing some orderings: ★:⊥ ≤ ★:⊥:⊥ and so on.
- In usual denotational semantics, you can’t distinguish between ⊥ and
λ_.⊥. However, as Anders Kaseorg and the Haskell Report point out, with seq you can distinguish them. This is perhaps the true reason why seq is a kind of nasty function. I’ve been assuming the stronger guarantee (which is what zygoloid pointed out) when it’s not actually true for Haskell. - The “ought to exist” arrow in the halts diagram goes the wrong direction.
- In the same fashion of the full list diagram,
head is missing some orderings, so in fact they gray blob is entirely connected. There are situations when we can have disconnected blobs, but not for a domain with only one maximum. - Obvious typo for fst.
- The formal partial order on functions was not defined correctly: it originally stated that for f ≤ g, f(x) = g(x); actually, it’s weaker than that: f(x) ≤ g(x).
- A non-erratum: the right-side of the head diagram is omitted because… adding all the arrows makes it look pretty ugly. Here is the sketch I did before I decided it wasn’t a good picture.

Thanks Anders Kaseorg, zygoloid, polux, and whoever pointed out the mistake in the partial order on functions (can’t find that correspondence now) for corrections.
Non sequitur. Here is a really simple polyvariadic function. The same basic idea is how Text.Printf works. May it help you in your multivariadic travels. :
{-# LANGUAGE FlexibleInstances #-}
class PolyDisj t where
disj :: Bool -> t
instance PolyDisj Bool where
disj x = x
instance PolyDisj t => PolyDisj (Bool -> t) where
disj x y = disj (x || y)
December 8, 2010Gin, because you’ll need it by the time you’re done reading this.
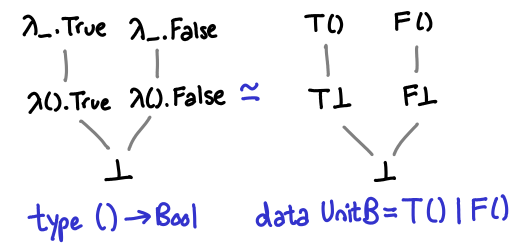
Last time we looked the partial orders of values for data types. There are two extra things I would like to add: an illustration of how star-subscript-bottom expands and an illustration of list without using the star-subscript-bottom notation.
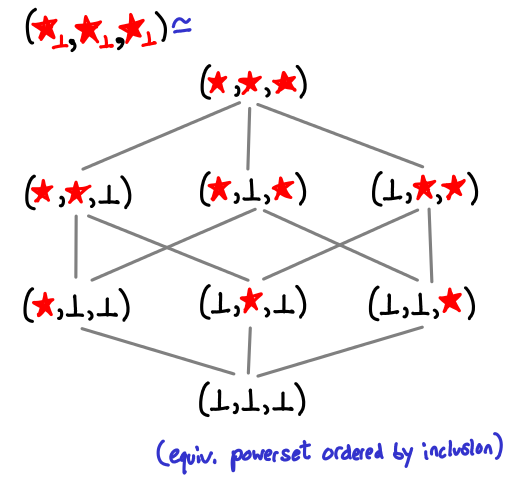
Here is a triple of star-subscript-bottoms expanded, resulting in the familiar Hasse diagram of the powerset of a set of three elements ordered by inclusion:
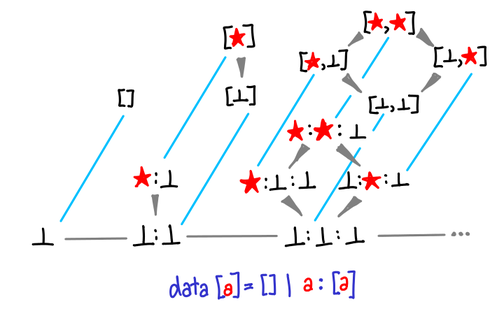
And here is the partial order of lists in its full exponential glory (to fit it all, the partial order of the grey spine increases as it goes to the right.)
Now, to today’s subject, functions! We’ve only discussed data types up until now. In this post we look a little more closely at the partial order that functions have. We’ll introduce the notion of monotonicity. And there will be lots of pictures.
Let’s start with a trivial example: the function of unit to unit, () -> (). Before you look at the diagram, how many different implementations of this function do you think we can write?
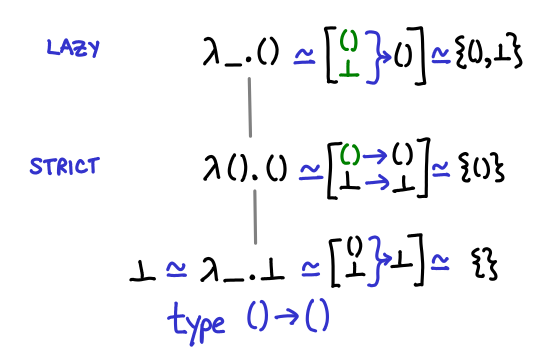
Three, as it turns out. One which returns bottom no matter what we pass it, one which is the identity function (returns unit if it is passed unit, and bottom if it is passed bottom), and one which is const (), that is, returns unit no matter what it is passed. Notice the direct correspondence between these different functions and strict and lazy evaluation of their argument. (You could call the bottom function partial, because it’s not defined for any arguments, although there’s no way to directly write this and if you just use undefined GHC won’t emit a partial function warning.)
In the diagram I’ve presented three equivalent ways of thinking about the partial order. The first is just terms in the lambda calculus: if you prefer Haskell’s notation you can translate λx.x into \x -> x. The second is a mapping of input values to output values, with bottom explicitly treated (this notation is good for seeing bottom explicitly, but not so good for figuring out what values are legal—that is, computable). The third is merely the domains of the functions: you can see that the domains are steadily getting larger and larger, from nothing to the entire input type.
At this point, a little formality is useful. We can define a partial order on a function as follows: f ≤ g if and only if dom(f) (the domain of f, e.g. all values that don’t result in f returning bottom) ⊆ dom(g) and for all x ∈ dom(f), f(x) ≤ g(x). You should verify that the diagram above agrees (the second condition is pretty easy because the only possible value of the function is ()).
A keen reader may have noticed that I’ve omitted some possible functions. In particular, the third diagram doesn’t contain all possible permutations of the domain: what about the set containing just bottom? As it turns out, such a function is uncomputable (how might we solve the halting problem if we had a function () -> () that returned () if its first argument was bottom and returned bottom if its first argument was ()). We will return to this later.
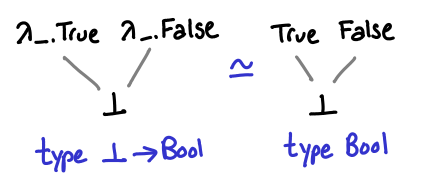
Since () -> () has three possible values, one question to ask is whether or not there is a simpler function type that has fewer values? If we admit the empty type, also written as ⊥, we can see that a -> ⊥ has only one possible value: ⊥.
Functions of type ⊥ -> a also have some interesting properties: they are isomorphic to plain values of type a.
In the absence of common subexpression elimination, this can be a useful way to prevent sharing of the results of lazy computation. However, writing f undefined is annoying, so one might see a () -> a instead, which has not quite the same but similar semantics.
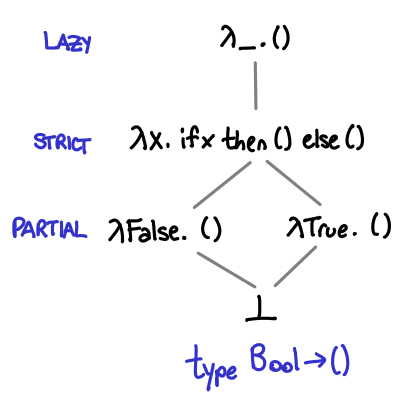
Up until this point, we’ve considered only functions that take ⊥ or () as an argument, which are not very interesting. So we can consider the next possible simplest function: Bool -> (). Despite the seeming simplicity of this type, there are actually five different possible functions that have this type.
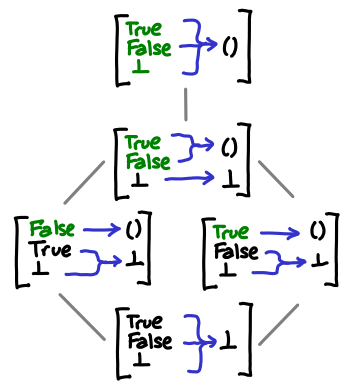
To see why this might be the case, we might look at how the function behaves for each of its three possible arguments:
or what the domain of each function is:
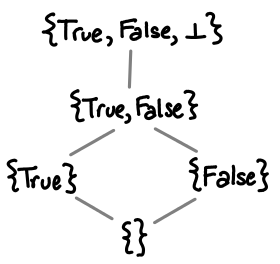
These partial orders are complete, despite the fact there seem to be other possible permutations of elements in the domain. Once again, this is because we’ve excluded noncomputable functions. We will look at this next.
Consider the following function, halts. It returns True if the computation passed to it eventually terminates, and False if it doesn’t. As we’ve seen by fix id, we can think of bottom as a nonterminating computation. We can diagram this by drawing the Hasse diagrams of the input and output types, and then drawing arrows mapping values from one diagram to the other. I’ve also shaded with a grey background values that don’t map to bottom.
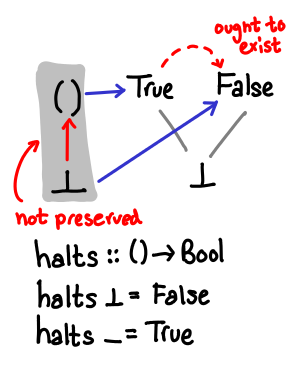
It is widely known that the halting problem is uncomputable. So what is off with this perfectly plausible looking diagram?
The answer is that our ordering has not been preserved by the function. In the first domain, ⊥ ≤ (). However, the resulting values do not have this inequality: False ≰ True. We can sum this condition as monotonicity, that is, f is monotonic when if x ≤ y then f(x) ≤ f(y).
Two degenerate cases are worth noting here:
- In the case where f(⊥) = ⊥, i.e. the function is strict, you never have to worry about ⊥ not being less than any other value, as by definition ⊥ is less than all values. In this sense making a function strict is the “safe thing to do.”
- In the case where f(x) = c (i.e. a constant function) for all x, you are similarly safe, since any ordering that was in the original domain is in the new domain, as c ≤ c. Thus, constant functions are an easy way of assigning a non-bottom value to f(⊥). This also makes clear that the monotonicity implication is only one direction.
What is even more interesting (and somewhat un-obvious) is that we can write functions that are computable, are not constant, and yet give a non-⊥ value when passed ⊥! But before we get to this fun, let’s first consider some computable functions, and verify monotonicity holds.
Simplest of all functions is the identity function:
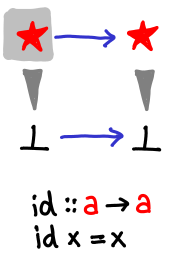
It does so little that it is hardly worth a mention, but you should verify that you’re following along with the notation.
A little less trivial is the fst function, which returns the first element of a pair.
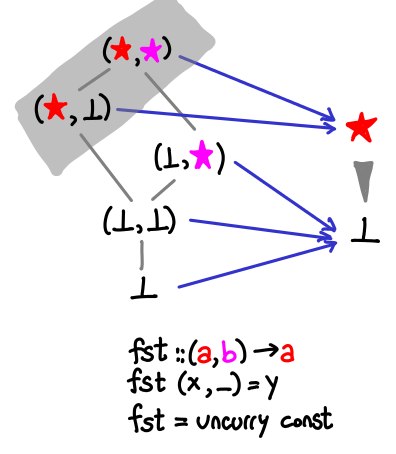
Look and verify that all of the partial ordering is preserved by the function: since there is only one non-bottom output value, all we need to do is verify the grey is “on top of” everything else. Note also that our function doesn’t care if the snd value of the pair is bottom.
The diagram notes that fst is merely an uncurried const, so let’s look at that next.
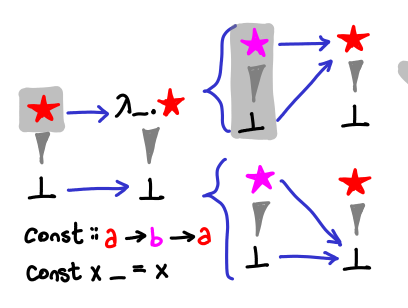
We would like to consider the sense of const as a -> (b -> a), a function that takes a value and returns a function. For the reader’s benefit we’ve also drawn the Hasse diagrams of the resulting functions. If we had fixed the type of a or b, there would be more functions in our partial order, but without this, by parametricity there is very little our functions can do.
It’s useful to consider const in contrast to seq, which is something of a little nasty function, though it can be drawn nicely with our notation.
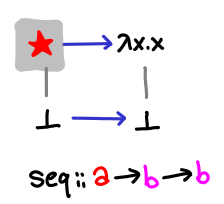
The reason why the function is so nasty is because it works for any type (it would be a perfectly permissible and automatically derivable typeclass): it’s able to see into any type a and see that it is either bottom or one of its constructors.
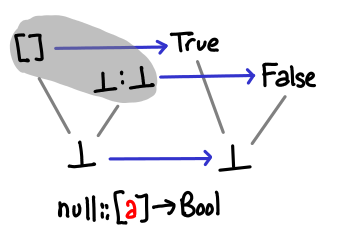
Let’s look at some functions on lists, which can interact in nontrivial ways with bottom. null has a very simple correspondence, since what it is really asking is “is this the cons constructor or the null constructor?”
head looks a little more interesting.
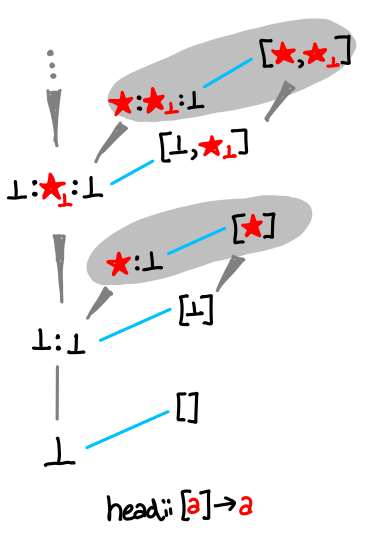
There are multiple regions of gray, but monotonicity is never violated: despite the spine which expands infinitely upwards, each leaf contains a maximum of the partial order.
There is a similar pattern about length, but the leaves are arranged a little differently:
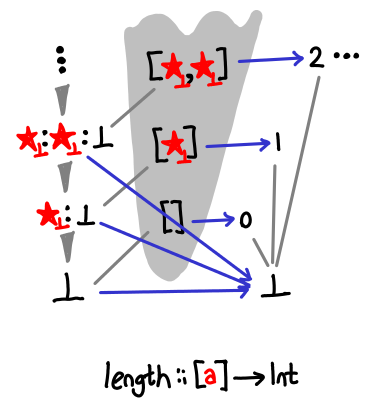
Whereas head only cares about the first value of the list not being bottom, length cares about the cdr of the cons cell being null.
We can also use this notation to look at data constructors and newtypes.
Consider the following function, caseSplit, on an unknown data type with only one field.

We have the non-strict constructor:
The strict constructor:
And finally the newtype:
We are now ready for the tour de force example, a study of the partial order of functions from Bool -> Bool, and a consideration of the boolean function ||. To refresh your memory, || is usually implemented in this manner:
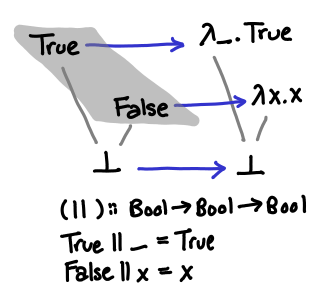
Something that’s not too obvious from this diagram (and which we would like to make obvious soon) is the fact that this operator is left-to-right: True || ⊥ = True, but ⊥ || True = ⊥ (in imperative parlance, it short-circuits). We’ll develop a partial order that will let us explain the difference between this left-or, as well as its cousin right-or and the more exotic parallel-or.
Recall that || is curried: its type is Bool -> (Bool -> Bool). We’ve drawn the partial order of Bool previously, so what is the complete partial order of Bool -> Bool? A quite interesting structure!
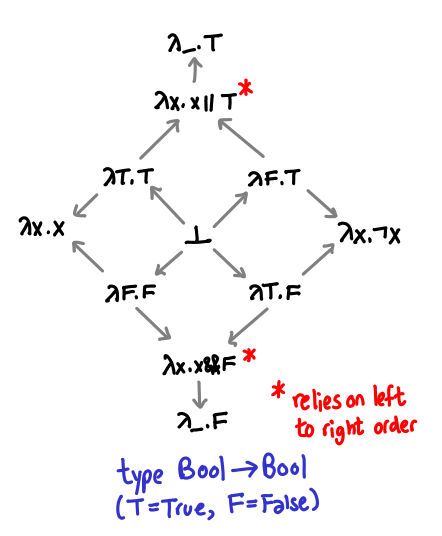
I’ve violated my previously stated convention that more defined types are above other types, in order to demonstrate the symmetry of this partial order. I’ve also abbreviated True as T and False as F. (As penance, I’ve explicitly drawn in all the arrows. I will elide them in future diagrams when they’re not interesting.)
These explicit lambda terms somewhat obscure what each function actually does, so here is a shorthand representation:
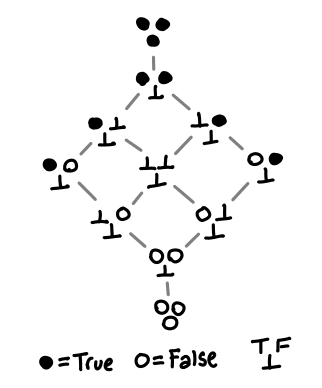
Each triple of balls or bottom indicates how the function reacts to True, False and bottom.
Notice the slight asymmetry between the top/bottom and the left/right: if our function is able to distinguish between True and False, there is no non-strict computable function. Exercise: draw the Hasse diagrams and convince yourself of this fact.
We will use this shorthand notation from now on; refer back to the original diagram if you find yourself confused.
The first order (cough) of business is to redraw the Hasse-to-Hasse diagram of left-or with the full partial order.
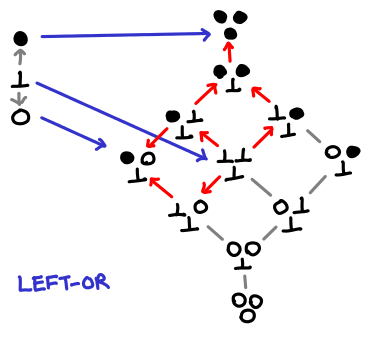
Verify that using transitivity we can recover the simplified, partial picture of the partial order. The red arrows indicate the preserved ordering from the original boolean ordering.
The million dollar question is this: can we write a different mapping that preserves the ordering (i.e. is monotonic). As you might have guessed, the answer is yes! As an exercise, draw the diagram for strict-or, which is strict in both its arguments.
Here is the diagram of right-or:
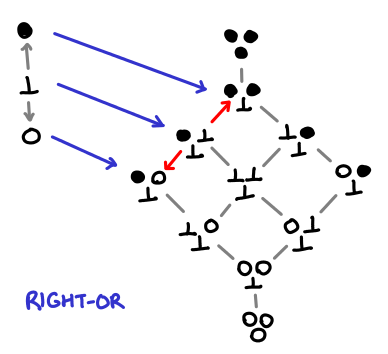
Notice something really interesting has happened: bottom no longer maps to bottom, but we’ve still managed to preserve the ordering. This is because the target domain has a rich enough structure to allow us to do this! If this seems a little magical to you, consider how we might write a right-or in Haskell:
rightOr x = \y -> if y then True else x
We just don’t look at x until we’ve looked at y; in our diagram, it looks as if x has been slotted into the result if y is False.
There is one more thing we can do (that has probably occurred to you by now), giving us maximum ability to give good answers in the face of bottom, parallel-or:
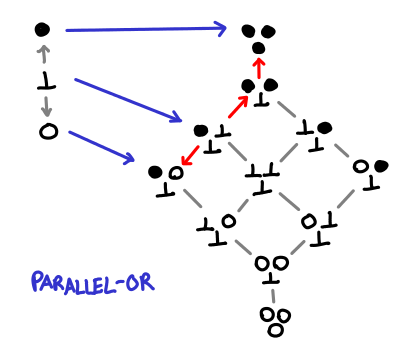
Truly this is the farthest we can go: we can’t push our functions any further down the definedness chain and we can’t move our bottom without changing the strict semantics of our function. It’s also not obvious how one would implement this in Haskell: it seems we really need to be able to pattern match against the first argument in order to decide whether or not to return const True. But the function definitely is computable, since monotonicity has not been violated.
The name is terribly suggestive of the correct strategy: evaluate both arguments in parallel, and return True if any one of them returns True. In this way, the Hasse diagram is quite misleading: we never actually return three distinct functions. However, I’m not really sure how to illustrate this parallel approach properly.
This entire exercise has a nice parallel to Karnaugh maps and metastability in circuits. In electrical engineering, you not only have to worry about whether or not a line is 1 or 0, but also whether or not it is transitioning from one to the other. Depending on how you construct a circuit, this transition may result in a hazard even if the begin and end states are the same (strict function), or it may stay stable no matter what the second line dones (lazy function). I encourage an electrical engineer to comment on what strict-or, left-or, right-or and parallel-or (which is what I presume is usually implemented) look like at the transistor level. Parallels like these make me feel that my time spent learning electrical engineering was not wasted. :-)
That’s it for today. Next time, we’ll extend our understanding of functions and look at continuity and fixpoints.
Postscript. There is some errata for this post.
December 6, 2010Values of Haskell types form a partial order. We can illustrate this partial order using what is called a Hasse diagram. These diagrams are quite good for forcing yourself to explicitly see the bottoms lurking in every type. Since my last post about denotational semantics failed to elicit much of a response at all, I decided that I would have better luck with some more pictures. After all, everyone loves pictures!
We’ll start off with something simple: () or unit.
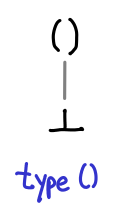
Immediately there are a few interesting things to notice. While we normally think of unit as only having one possible value, (), but in fact they have two: () and bottom (frequently written as undefined in Haskell, but fix id will do just as well.) We’ve omitted the arrows from the lines connecting our partial order, so take as a convention that higher up values are “greater than” their lower counterparts.
A few more of our types work similarly, for example, Int and Bool look quite similar:
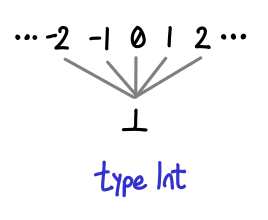
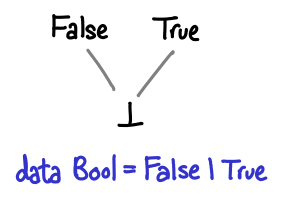
Note that Int without bottom has a total ordering independent of our formulation (the usual -3 is less than 5 affair, alluded to by the Ord instance for Int). However, this is not the ordering you’re looking for! In particular, it doesn’t work if bottom is the game: is two less than or greater than bottom? In this partial ordering, it is “greater”.
It is no coincidence that these diagrams look similar: their unlifted sets (that is, the types with bottom excluded) are discrete partial orders: no element is less than or greater than another.
What happens if we introduce data types that include other data types? Here is one for the natural numbers, Peano style (a natural number is either zero or the successor of a natural number.)
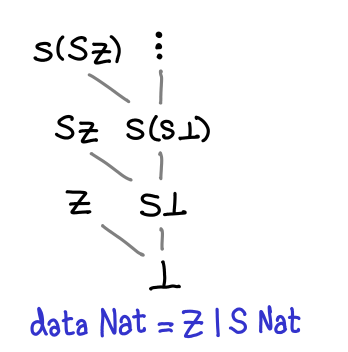
We no longer have a flat diagram! If we were in a strict language, this would have collapsed back into the boring partial orders we had before, but because Haskell is lazy, inside every successor constructor is a thunk for a natural number, which could be any number of exciting things (bottom, zero, or another successor constructor.)
We’ll see a structure that looks like this again when we look at lists.
I’d like to discuss polymorphic data types now. In Haskell Denotational semantics wikibook, in order to illustrate these data types, they have to explicitly instantiate all of the types. We’ll adopt the following shorthand: where I need to show a value of some polymorphic type, I’ll draw a star instead. Furthermore, I’ll draw wedges to these values, suggestive of the fact that there may be more than one constructor for that type (as was the case for Int, Bool and Nat). At the end of this section I’ll show you how to fill in the type variables.
Here is Maybe:
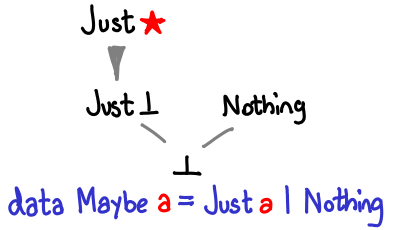
If Haskell allowed us to construct infinite types, we could recover Nat by defining Maybe (Maybe (Maybe …)).
Either looks quite similar, but instead of Nothing we have Right:
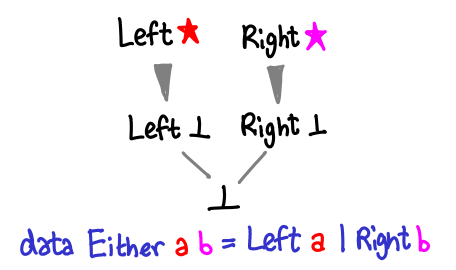
Is Left ⊥ greater than or less than Right () in this partial order? It’s a trick question: since they are different constructors they’re not comparable anymore.
Here’s a more interesting diagram for a 2-tuple:
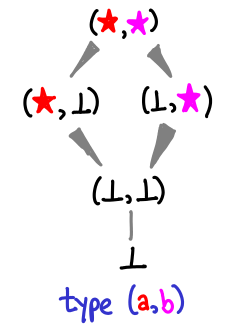
The values merge back at the very top! This is because while ((), ⊥) is incomparable to (⊥, ()), both of them are less than ((), ()) (just imagine filling in () where the ⊥ is in both cases.)
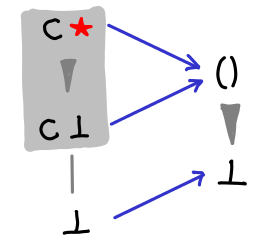
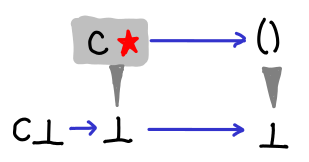
If we admit lazy data structures, we get a lot richer space of possible values than if we’re forced to use strict data structures. If these constructors were strict, our Hasse diagrams would still be looking like the first few. In fact, we can see this explicitly in the difference between a lazy constructor and a strict constructor:
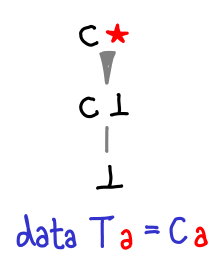
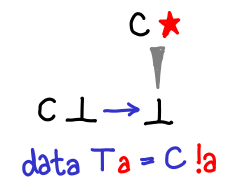
The strict constructor squashes ⊥ and C ⊥ to be the same thing.
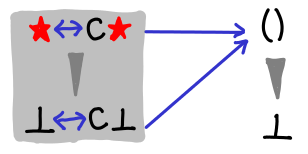
It may also be useful to look at newtype, which merely constructs an isomorphism between two types:
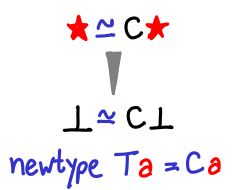
It looks a bit like the strict constructor, but it’s actually not at all the same. More on this in the next blog post.
How do we expand stars? Here’s a diagram showing how:
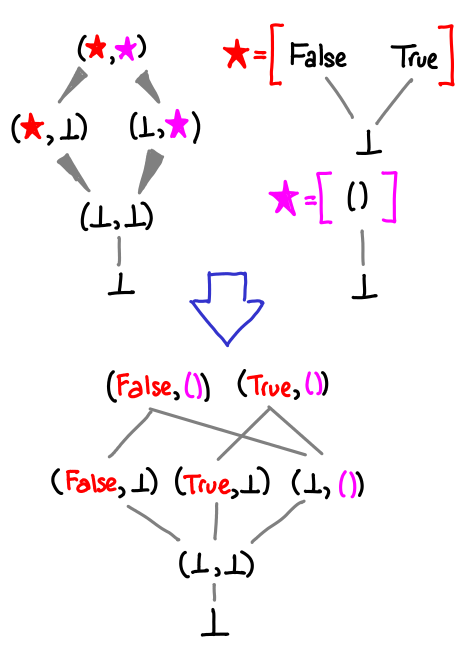
Graft in the diagram for the star type (excluding bottom, since we’ve already drawn that into the diagram), and duplicate any of the incoming and outgoing arrows as necessary (thus the wedge.) This can result in an exponential explosion in the number of possible values, which is why I’ll prefer the star notation.
And now, the tour de force, lazy lists:
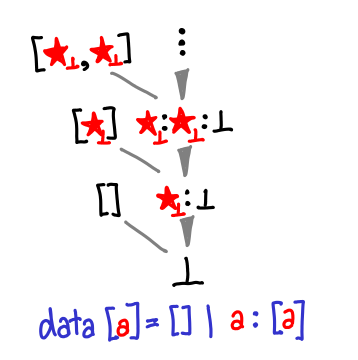
Update. There’s one bit of extra notation: the stars with subscript ⊥ mean that you’ll need to graft in bottom as well (thanks Anonymous for pointing this out.) Tomorrow we’ll see list expanded in its full, exponential glory.
We almost recover Nat if we set a to be (), but they’re not quite isomorphic: every () might actually be a bottom, so while [()] and [⊥] are equivalent to one, they are different. In fact, we actually want to set a to the empty type. Then we would write 5 as [⊥, ⊥, ⊥, ⊥, ⊥].
Next time, we’ll draw pictures of the partial ordering of functions and illustrate monotonicity.
December 3, 2010I’ve had the pleasure of attending a number of really interesting talks over the past few months, so many that I couldn’t find time to write thorough articles for each of them as I did over the summer. So you’ll have to forgive me for putting two of them in compressed form here. There is something of a common theme of recasting a problem on a different input domain in order to achieve results, as I hope will become evident by these summaries.
A Language for Mathematics by Mohan Ganesalingam. Big idea: Apply linguistics and natural language processing techniques to mathematical language—the type found in textbooks and proofs.
Ganesalingam has big goals: his long term project is to “enable computers to do mathematics in the same way that humans do.” “But wait,” you may say, “aren’t we already approaching this with proof assistants?” Unfortunately, the answer to this is no: proof assistants are quite good at capturing rigorous formal reasoning, but are terrible at actually capturing the soft ideas that mathematicians gesture at when writing proofs and textbooks. The first step in this program is understanding this mathematical language—thus, the title of his talk.
Why do we have any reason to believe that this program will be any more successful than current research in linguistics and NLP? After all, most papers and textbooks use English interspersed with mathematical notation, and grand ideas about semantic analysis have given way to more effective but theoretically less appealing statistical methods. Ganesalingam makes some key observations here: in essence, mathematical language has the right dose of formality to make traditionally hard problems tractable. Only a small lexicon is necessary, and then mathematical terms can be defined in terms of other mathematical terms, and in many cases, there is a clear semantics for a mathematical statement: we can in principle translate it into a statement in higher order logic.
Further reading: Slides for a similar presentation that was given at Stanford, an informal non-technical introduction, author’s homepage.
Evaluating Formulas on Graphs by Anuj Dawar. There are really two big ideas here. Big idea 1. Generalize graph problems into the question “does this first-order logical formula hold on this graph?”, treating your algorithm as a function on two inputs: the graph and the logical formula. Big idea 2. Use graph structure theory to characterize what input spaces of graphs we can efficiently solve these FO formulas for.
First big idea: the study of graph problems is frequently focused on an individual graph problem at a time: after all, being able to assume a concrete problem instance makes it easier to reason about things. What Dawar’s talk introduces is a way to talk about large classes of graph problems by bundling them up into logics (of various shapes and sizes.) Existential second-order logic gives you all NP problems (Fagin); first-order logic is more restrictive but admits better analysis. Separating out the formula from your problem also lets you apply parametrized complexity theory: the formula is an input to your algorithm, and you set it constant or vary it. Unfortunately, the problem (even for fixed graphs) is still PSPACE-complete, so we need another way to get a grip on the problem.
Second big idea: restrict the input graphs in order to make the algorithms tractable. This involves a bit of graph theory knowledge which I’m not going to attempt to summarize, but there are some really nice results in this area:
- Seese (1996): For the class of graphs with degree bounded by k, every FO definable property is decidable in linear time.
- Frick and Grohe (2001): For the class of graphs of local tree-width bounded by a function f, every FO definable property is decidable in quadratic time.
- Flum and Grohe (2001): For the class of graphs excluding K_k as a minor, every FO definable property is decidable in O(n^5).
One oddball fact is that Flum and Grohe’s O(n^5) bound on complexity has a constant factor which may not be computable.
By the end, we get to the edge of research: he introduces a new class of graphs, nowhere dense graphs, motivates why we have good reason to think this characterizes tractability, and says that they hope to establish FO is fixed parameter tractable.
A quick aside: one of the things I really enjoy about well-written theoretical research talks is that they often introduce me to subfields of computer science that I would not have otherwise encountered. This presentation was a whirlwind introduction to graph theory and parametrized complexity theory, both topics I probably would not have otherwise considered interesting, but afterwards I had tasted enough of to want to investigate further. I think it is quite commendable for a researcher doing highly abstract work to also be giving seminars working up the background knowledge necessary to understand their results.
Further reading: Full course on these topics
December 1, 2010An extended analogy on the denotational and game semantics of ⊥
This is an attempt at improving on the Haskell Wikibooks article on Denotational Semantics by means of a Dr. Strangelove inspired analogy.
The analogy. In order to prevent Brigadier General Jack D. Ripper from initiating a nuclear attack on Russia, the Pentagon decides that it will be best if every nuclear weapon requires two separate keys in order to be activated, both of which should not be known by the same person at the same time under normal circumstances. Alice is given one half of the key, Bob the other half. If Ripper asks Alice for her half of the key, she can tell him her key, A. However, asking Alice for Bob’s key won’t work, since she doesn’t know what Bob’s key is.
Suppose Ripper asked Alice anyway, and she told him “I don’t know Bob’s key.” In this case, Ripper now have a concrete piece of information: Alice does not have Bob’s key. He can now act accordingly and ask Bob for the second key. But suppose that, instead of telling him outright that she didn’t know the key, she told him, “I can tell you, but can you wait a little bit?” Ripper decides to wait—he’d probably have a time convincing Bob to hand over the key. But Alice never tells Ripper the key, and he keeps waiting. Even if Ripper decides to eventually give up waiting for Alice, it’s a lot harder for him to strategize when Alice claims she has the key but never coughs it up.
Alice, curious what would happen if she tried to detonate the nuclear bomb, sets off to talk to Larry who is responsible for keying in the codes. She tells the technician, “I have Alice’s key and I have Bob’s key.” (We, of course, know that she doesn’t actually have Bob’s key.) Larry is feeling lazy, and so before asking Alice for the keys, he phones up the Pentagon and asks if nuclear detonation is permitted. It is not, and he politely tells Alice so. Unruffled, Alice goes off and finds Steve, who can also key in the codes. She tells Steve that she has Alice’s key and Bob’s key. Steve, eager to please, asks Alice, “Cool, please tell me your key and Bob’s key.” Alice hands over her key, but stops on Bob’s key, and the conversation never finishes.
Nevertheless, despite our best efforts, Ripper manages to get both keys anyway and the world is destroyed in nuclear Armageddon anyway. ☢
Notation. Because this key is in two parts, it can be represented as a tuple. The full key that Ripper knows is (A, B), what Alice knows about the full key is (A, ⊥), and what Bob knows is (⊥, B). If I am (clueless) civilian Charlie, my knowledge might be (⊥, ⊥). We can intuitively view ⊥ as a placeholder for whenever something is not known. (For simplicity, the types of A and B are just unit.)
I know more than you. We can form a partial ordering of who knows more than who. Ripper, with the full key, knows more than Alice, Bob or Charlie. Alice knows more than Charlie, and Bob knows more than Charlie. We can’t really say that Alice knows more than Bob, or vice versa, since they know different pieces of data. ⊥ is at the bottom of this ordering because, well, it represents the least possible information you could have.
The difference between nothing and bottom. Things play out a bit differently when Alice says “I don’t know” versus when Alice endlessly delays providing an answer. This is because the former case is not bottom at all! We can see this because Alice actually says something in the first case. This something, though it is not the key, is information, specifically the Nothing constructor from Maybe. It would be much more truthful to represent Alice’s knowledge as (Just A, Nothing) in this case. In the second case, at any point Alice could give a real answer, but she doesn’t.
A strange game. The only winning move is not to play. There is a lot of emphasis on people asking other people for pieces of information, and those people either responding or endlessly delaying. In fact, this corresponds directly to the notion of bottom from game semantics. When Ripper asks Alice for information about her key, we can write out the conversation as the sequence: “tell me the first value of the tuple”, “the value is A”, “tell me the second value of the tuple”, “…” Alice is speechless at the last question, because in game semantics parlance, she doesn’t have a strategy (the knowledge) for answering the question “tell me the second value of the tuple.” Clueless Charlie is even worse off, having no strategy for either question: the only time he is happy is if no one asks him any questions at all. He has the empty strategy.
Don’t ask, don’t tell. Consider function application. We might conceptualize this as “Here is the value A, here is the value B, please tell me if I can detonate the nuclear device.” This is equivalent to Steve’s strict evaluation. But we don’t have to setup the conversation this way: the conversation with Larry started off with, “I have the first key and I have the second key. Please tell me if I can detonate the nuclear device.” Larry might then ask Alice, “Ok, what is the first key?”—in particular, this will occur if Larry decides to do a case statement on the first key—but if Larry decides he doesn’t need to ask Alice for any more information, he won’t. This will make Charlie very happy, since he is only happy if he is not asked any questions at all.
Ask several people at the same time. In real life, if someone doesn’t give us an answer after some period of time, we can decide to stop listening and go do something else. Can programs do this too? It depends on what language you’re in. In Haskell, we can do this with nondeterminism in the IO monad (or push it into pure code with some caveats, as unamb does.)
What’s not in the analogy. Functions are data too: and they can be partially defined, e.g. partial functions. The fixpoint operator can be thought to use less defined versions of a function to make more defined versions. This is very cool, but I couldn’t think of an oblique way of presenting it. Omitted are the formal definitions from denotational semantics and game semantics; in particular, domains and continuous functions are not explained (probably the most important pieces to know, which can be obscured by the mathematical machinery that usually needs to get set up before defining them).
Further reading. If you think I’ve helped you’ve understand bottom, go double check your understanding of the examples for newtype, perhaps one of the subtlest cases where thinking explicitly about bottom and about the conversations the functions, data constructors and undefineds (bottoms) are having. The strictness annotation means that the conversation with the data constructor goes something like “I have the first argument, tell me what the value is.” “Ok, what is the first argument?” These notes on game semantics (PDF) are quite good although they do assume familiarity with denotational semantics. Finding the formal definitions for these terms and seeing if they fit your intuition is a good exercise.
November 29, 2010One of the distinctive differences between academic institutions in the United States and in Great Britain is the supplementary learning outside of lectures. We have recitations in the US, which are something like extra lectures, while in the UK they have tutorials, or supervisions as they are called in Cambridge parlance. As always, they are something of a mixed bag: some supervisors are terrible, others are merely competent, and others inspire and encourage a sort of interest in the subject far beyond the outlines of the course.
Nik Sultana, our Logic and Proof supervisor, is one of these individuals. For our last supervision, on something of a whim (egged on by us, the supervisees), he suggested we attempt to prove the following logical statement in Isabelle, the proof assistant that he has been doing his research with.
$\forall x [\lnot P(x) \to Q(x)] \wedge \exists x \lnot Q(x) \to \exists x P(x)$
I first worked out the sequent calculus proof for the statement (left as an exercise for the reader), and then I grabbed Isabelle, downloaded the manual, fired up Proof General, and began my very first proof in Isabelle.
Syntax. The first problem I had was getting a minimal theory to compile. This was because Isabelle requires you to always have an imports line, so I provided Main as an import.
I then tried proving a trivial theory, A –> A and got tripped by stating “by (impI)” instead of “by (rule impI)” (at this point, it was still not clear what ‘rule’ actually did).
I tried proving another theory, conj_rule, straight from the documentation, but transcribed the Unicode to ASCII wrong and ended up with a theory that didn’t match the steps they did. (This was one annoying thing about reading the manual, though I understand why they did it.) Eventually I realized what was wrong, and decided to actually start the proof:
lemma "(ALL x. ~ P x --> Q x) & (EX x. ~ Q x) --> (EX x. P x)"
I first tried non-dot notation, but that failed to syntax check so I introduced dots for all bound variables.
Semantics. The proof was simple:
by blast
But that was cheating :-)
At this point, I felt pretty out-of-the-water: Isabelle uses a natural deduction system, whereas (through my studies) I had the most experience reasoning with equivalences, the sequent calculus, or the tableau calculus (not to mention I had a sequent calculus proof already in hand). As it would turn out, removing the quantifiers would look exactly like it would in normal sequent calculus, but I hadn’t realized it yet.
I stumbled around, blindly applying allE, allI, exE and exI to see what they would. I hadn’t realized the difference between rule, drule and erule yet, so occasionally I’d apply a rule and get a massive expansion in subgoals, and think to myself, “huh, that doesn’t seem right.”
Finally, reading backwards from the universals section, I realized that ==> was a little different from -->, representing a meta-implication that was treated specially by some rules, so I converted to it:
-- "Massage formula"
apply (rule impI)
Once again, I tried applying the universal rules and generally didn’t manage to make the formula look pretty. Then I looked more closely at the Isabelle examples and noticed they used [| P; Q |], not P & Q on the left hand side of ==>, so I found the appropriate rule to massage the formula into this form (the semicolon is the sequent calculi’s colon). I then realized that there was this thing erule, although I still thought you simply applied it when the rule had an E at the end:
apply (erule conjE)
Proof. Everyone loves coding by permuting, so I permuted through the rules again. This time, exE seemed to keep the formula simple, and after a few seconds of head-scratching, would have also been the right thing to do in a sequent calculus proof. I also realized I was doing backwards proof (that is, we take our goals and break them down into subgoals), and suddenly the implication statements in the manual made a lot more sense (look at the right side, not the left!):
apply (erule exE)
This next step took a while. I was fairly easily able to apply (erule allE), which eliminated the universal on the right side of the equation, but it introduced a fresh skolem function and that didn’t seem like what I wanted. I also knew that I should theoretically be able to eliminate the right-hand-side existential, but couldn’t figure out what rule I should use. Trying the usual rules resulted in nonsense, though I think at this point I had figured out when to use the various variants of rule. Eventually, I reread the substituting a variable explicitly section of the manual, cargo-culted the drule_tac syntax, and it worked! :
apply (drule_tac x = "x" in spec)
Experienced Isabellers will have realized that I could eliminate the right exists, but since I had concluded that this was not possible, I went on a detour. I decided to try combining some of the my assumptions to get some useful conclusions. Right now the proof state was:
!!x. [| ~ Q x; ~ P x -> Q x |] ==> (EX x. P x)
I felt I ought to be able to get P x on the left-hand side, and then apply some existential rule because of the true statement P x ==> (EX x. P x). But none of the implication rules or modus ponens applied properly. I also tried swapping over the assumption and goal using contrapositive:
!!x. [| ~ (EX x. P x); ~ P x -> Q x |] ==> Q x
Actually, I had wanted the implication on the right side. Nevertheless, the existential was on the left, so I should have been able to eliminate it… except there was a negation so the rule failed.
More reading revealed that I could use some special syntax to make the implication go on the right side:
!!x. [| ~ Q x; ~ (EX. P x) |] ==> ~ (~ P x -> Q x)
But once again, the conditional prevented me from doing my evil plan of destructing the implication and deriving a contradiction in the assumptions.
So I went back, played some more, and eventually figured out that to eliminate an existential from the goal side, you introduce it (backwards!) And I also found out that _tac could work for basically any rule:
apply (rule_tac x = "x" in exI)
At this point it was a simple propositional proof to prove, and my previous adventures with contraposative gave me an idea how to do it:
apply (erule contrapos_np)
by (drule mp)
Sweet. After I finished the proof, I went back and removed the tacs and checked if Isabelle was able to unify the variables itself; it was, but the intermediate proof goals looked uglier so I added them back in. And that concluded my very first proof in Isabelle. It’s not much, but it involved enough wandering that I felt quite pleased when I finished. Here’s the whole thing:
theory LogicAndProof
imports Main
begin
lemma "(ALL x. ~ P x --> Q x) & (EX x. ~ Q x) --> (EX x. P x)"
-- "Massage the formula into a nicer form to apply deduction rules"
apply (rule impI)
apply (erule conjE)
-- "Start introducing the safe quantifiers"
apply (erule exE)
apply (drule_tac x = "x" in spec)
apply (rule_tac x =" x" in exI)
apply (erule contrapos_np)
by (drule mp)
November 26, 2010In which Mendeley, Software Foundations and Coq are discussed.
I was grousing on #haskell-blah one day about how annoying it was to organize all of the papers that I have downloaded (and, of course, not read yet.) When you download a paper off the Internet, it will be named all sorts of tremendously unhelpful things like 2010.pdf or icfp10.pdf or paper.pdf. So to have any hope of finding that paper which you skimmed a month ago and vaguely recall the title of, you’ll need some sort of organization system. Pre-Mendeley, I had adopted the convention of AuthorName-PaperTitle.pdf, but I’d always feel a bit bad picking an author out of a list of five people to stick at the beginning, and I still couldn’t ever find the paper I was looking for.
It was at this point that someone (I don’t have logs, so I don’t remember precisely who) pointed me to Mendeley. Mendeley is free (as in beer) software that helps you organize your papers and upload them to the cloud; in return, they get all sorts of interesting data about what papers people are reading and hounds of metadata obsessed freaks like me curating their databases.
It doesn’t have to do much to improve over my existing ad hoc naming scheme. But it does it exceedingly well. After having shifted my paper database over to it, it’s reasonably easy (read, spend an afternoon curating a database of 200 papers) to ensure all of your papers have reasonable metadata attached to them. This reasonable metadata means you can slice your database by author (apparently Simon Peyton Jones and Chris Okasaki are two of my favorite authors) and conference (in case I, like, actually write a paper and need to figure out where to send it). You can also classify papers according to your own topics, which is very good if you’re like me and have bodies of completely unrelated research literature. Simple, but effective.
Oh, I do have some complaints about Mendeley. It’s PDF viewer leaves something to be desired: if I page down it skips entirely to the next page instead of doing a continuous scroll; the metadata extraction could be better (essentially, it should be just good enough to be able to look it up on an online database and then fill in the database); there should be a better workflow for papers (rather than just a read or unread toggle, which is utterly not useful); etc. But it works well enough to bring value, and I’m willing to overlook these nits.
After having organized all of my papers, I suddenly realized that I hadn’t added any new papers to my collection recently. Papers either find my way to me because a friend forwards it on, or I’m looking for some specific topic and a relevant paper pops up, but I don’t actually have any streams of new papers to take a look at. To fix this, I decided to pick some names and go look at their recent publications.
On the way, I noticed an interesting slide deck on Benjamin Pierce’s publications. The deck was for a keynote address named Proof Assistant as Teaching Assistant: A View from the Trenches. I thought this was a quite fascinating approach to the problem of teaching proof, and even better, the course notes were online!
It’s difficult for me to precisely vocalize how unimaginably awesome Software Foundations. I’ve found it a bit difficult to get started with proof assistants because it’s always unclear what exactly you should prove with them: pick something too easy and it feels pointless, pick something too hard and you find yourself without a clue on how to attack the problem. Proof assistants are also rather sophisticated (it reminds me of a time when I was listening to Eric and Trevor discuss proof tactics back at Galois… that was a very hard to follow conversation), so if you dive into the manual you find yourself with all this rope but not very much idea how to use it all.
Software Foundations is great because it’s not teaching you how to use a proof assistant: it’s teaching you about logic, functional programming and the foundations of programming languages, built on top of a proof assistant Coq. So you have a bag of interesting, fundamental theorems about these topics that you want to prove, and then this course shows you how to use the proof assistant to prove them.
It’s also a rather ideal situation for self-study, because unlike many textbook exercises, your Coq interpreter will tell you when you’ve got the right answer. Proof assistants are fun precisely because they’re a bit like puzzles that you can create without knowing the solution before hand, and then solve. So if you’ve got some extra time on your hands and have wanted to learn how to use a proof assistance but never got around to it, I highly recommend checking it out.
November 24, 2010The On-Line Encyclopedia of Integer Sequences is quite a nifty website. Suppose that you’re solving a problem, and you come up with the following sequence of integers: 0, 1, 0, 2, 0, 1, 0, 3, 0, 1, 0, 2... and you wonder to yourself: “huh, what’s that sequence?” Well, just type it in and the answer comes back: A007814, along with all sorts of tasty tidbits like constructions, closed forms, mathematical properties, and more. Even simple sequences like powers of two have a bazillion alternate interpretations and generators.
This got me wondering: what are integer sequences that every computer scientist should know? That is, the ones they should be able to see the first few terms of and think, “Oh, I know that sequence!” and then rack their brains for a little bit trying to remember the construction, closed form or some crucial property. For example, almost anyone with basic math background will recognize the sequences 1, 2, 3, 4, 5; 0, 1, 4, 9, 16; or 1, 1, 2, 3, 5. The very first sequence I cited in this article holds a special place in my heart because I accidentally derived it while working on my article Adventures in Three Monads for The Monad.Reader. Maybe a little less familiar might be 1, 1, 2, 5, 14, 42 or 3, 7, 31, 127, 8191, 131071, 524287, 2147483647, but they are still quite important for computer scientists.
So, what integer sequences every computer scientist should know? (Alternatively, what’s your favorite integer sequence?)
November 22, 2010I’ve been wanting to implement a count-min sketch for some time now; it’s a little less widely known than the bloom filter, a closely related sketch data structure (that is, a probabilistic data structure that approximates answers to certain queries), but it seems like a pretty practical structure and has been used in some interesting ways.
Alas, when you want to implement a data structure that was proposed less than a decade ago and hasn’t found its way into textbooks yet, there are a lot of theoretical vagaries that get in the way. In this particular case, the theoretical vagary was selection of a universal hash family. Having not taken a graduate-level algorithms course yet, I did not know what a universal hash family was, so it was off to the books for me.
From my survey of course notes, papers and textbooks, I noticed two things.
First, there are a lot of different independence guarantees a universal hash family may have, each of which may go under many different names. Assume that our hash family H is a family of functions from h : M → N where M = {0, 1, ..., m-1} and N = {0, 1, ..., n-1} with m >= n. M corresponds to our “universe”, the possibly values being hashed, while N is the range of the hash function.
A weak universal hash family, also called a weak 2-universal hash family and sometimes stated with the weak elided, is a hash family that for a hash function h chosen uniformly at random from H:
∀ x,y ∈ M, x != y. Pr[h(x) = h(y)] ≤ 1/n
A strongly 2-universal hash family, also called a (strongly) 2-independent universal hash family and sometimes stated with 2-universal elided, is one that fulfills this condition:
∀ x,y ∈ M, a,b ∈ N.
Pr[h(x) = a ∧ h(y) = b] ≤ 1/n²
A (strongly) k-independent universal hash family generalizes the above notion, to the following condition:
∀ x₁,x₂...x_k ∈ M, a₁,a₂...a_k ∈ N.
Pr[h(x₁) = a₁ ∧ h(x₂) = a₂ ∧ ...] ≤ 1/n^k
Second, the reason why weak is commonly elided from weak hash function is that 2-universal hash families tend to also be 2-independent. Randomized Algorithms states “Most known constructions of 2-universal hash families actually yield a strongly 2-universal hash family. For this reason, the two definitions are generally not distinguished from one another” and asks the student to prove that if n = m = p is a prime number, the Carter and Wegman’s hash family is strongly 2-universal. (I’ll state what this is shortly.) So Wikipedia happily adopts the weak criteria and only briefly mentions 2-independence in the last section. (I have not edited the article because I’m not sure what, if any change, would be made.)
So, what’s Carter and Wegman’s universal hash family? Quite simple:
$h_{a,b}(x) = (ax + b \mod p) \mod n$
given that p ≥ m is prime and $a,b \in {0, 1, \cdots, p-1}$. Except, uh, no one actually uses a modulus in practice. Here’s one example from Cormode’s implementation:
#define MOD 2147483647
#define HL 31
long hash31(long long a, long long b, long long x)
{
long long result;
long lresult;
// return a hash of x using a and b mod (2^31 - 1)
// may need to do another mod afterwards, or drop high bits
// depending on d, number of bad guys
// 2^31 - 1 = 2147483647
result=(a * x) + b;
result = ((result >> HL) + result) & MOD;
lresult=(long) result;
return(lresult);
}
This implementation is clearly correct:
- The multiplication and addition can’t overflow the
long long result, and - The second line takes advantage of our ability to do fast modulus with Mersenne primes with a few alternate bitwise operations. Of course, in order to do this, we need to be very careful what prime we pick. Mmm magic numbers.
OK, so that’s very nice. There is a minor bit of sloppiness in that we haven’t explicitly ensured that n = m = p, so I’m not 100% convinced we preserve strong universality. But I haven’t worked out the Randomized Algorithms exercise so I don’t know how important this property is in practice.
As an aside, this function also claims to be this very universal hash but I have a hard time believing it:
Tools::UniversalHash::value_type Tools::UniversalHash::hash(
UniversalHash::value_type x
) const
{
uint64_t r = m_a[0];
uint64_t xd = 1;
for (uint16_t i = 1; i < m_k; i++)
{
xd = (xd * x) % m_P;
r += (m_a[i] * xd) % m_P;
// FIXME: multiplications here might overflow.
}
r = (r % m_P) & 0xFFFFFFFF;
// this is the same as x % 2^32. The modulo operation with powers
// of 2 (2^n) is a simple bitwise AND with 2^n - 1.
return static_cast<value_type>(r);
}
We now turn our attention to multiply-carry, which Wikipedia claims is the fastest universal hash family currently known for integers. It’s designed to be easy to implement on computers: (unsigned) (a*x) >> (w-M) (with a odd) is all you need. Well, to be precise, it’s the fastest 2-universal has family currently known: the relevant paper only gives the weak universality proof about Pr[h(x) = h(y)].
So, my question is thus: is multiply-carry strongly universal? Motwani and Raghavan suggest it probably is, but I couldn’t dig up a proof.
Postscript. Fortunately, for count-min-sketch, we don’t actually need strong universality. I checked with Graham Cormode and they only use 2-universality in their paper. But the original question still stands… for strictly theoretical grounds, anyway.
Non sequitur. Here’s an interesting combinator for combining functions used in folds:
f1 <&> f2 = \(r1, r2) a -> (f1 r1 a, f2 r2 a)
It lets you bundle up two combining functions so that you can apply both of them to a list in one go:
(foldl xs f1 z1, foldl xs f2 z2) == foldl xs (f1 <&> f2) (z1, z2)
Flipping the combinator would make it work for right folds. This gives us the following cute implementation of the average function:
average = uncurry (/) . foldl' ((+) <&> (flip (const (+1)))) (0,0)
Maybe we could write a rewrite rule to do this for us.
November 19, 2010In which Edward tells some stories about Cambridge and posts lots of pictures.
Apparently, Alyssa B. Hacker (sic) went on the Cambridge-MIT exchange.

This is perhaps a phenomenon of having been around MIT for too long, a campus which has a reputation for not being too picturesque (I can probably count the actually pretty spots on campus with one hand), but it’s real easy to stop appreciating how nice the buildings and architecture are around here. Look!



Granted, I don’t live in any of these places; I just pass by them on my way to lecture in central Cambridge. My college, Fitzwilliam, is not so pretty from the outside (pictures omitted), but absolutely gorgeous inside:

Erm, never mind the bags of shredded paper awaiting collection.

A gorgeously illustrated map of Fitzwilliam college (sorry about the glare):

If you squint, you can make out a location on the map called The Grove. There is actually a quite story behind this part of the college: it was actually owned by the Darwin family (as in, the Charles Darwin), and the college was built around the grove, which was not part of the college until Emma Darwin died and the house became incorporated as part of the college.

It is so tremendously easy to wander into a room and see someone famous. Like Tony Hoare, inventor of Quicksort and Hoare logic. I told people I came to Cambridge University in part to get a taste of its theoretical flavour, and I have not been disappointed. I tremendously enjoyed Marcelo Fiore’s lectures on denotational semantics (maybe I’ll get a blog post or two out of what I learned in the class). Other lectures have been a somewhat mixed bag (but then again, when are they not?), but they’ve managed to fill out areas of my education that I didn’t know I didn’t know about. The section about skolemization from my Logic and Proof course reminds me of this blog post from a while back, bemoaning the fact that no one actually tells you that Skolem constants is how you actually implement a typechecker. Well, apparently, skolemization is a classic technique in the logic world, and acts precisely the way you might expect it to with a type system (after all, Curry-Howard isomorphism).
Also, our logic and proof supervisor gives us tea. :-) His room at Trinity college (where we hold our supervisions) is the same room that the brilliant mathematician Ramanujan stayed in while he was a fellow at Trinity. Speaking of which, it’s the hundredth anniversary of Russell and Whitehead’s Principia.
I’ve utterly failed (thus far) at actually doing any research, but I’m enjoying the theoretical talks and soaking in all of this foundational knowledge.

Speaking of which, the computer lab is not in classical style. I guess you’d have a hard time convincing architects these days of constructing old-style buildings. You’ll find oddities like libraries on stilts inside hardcore traditional colleges:

Ah, the march of modernity. If I wasn’t taking History and Philosophy of Science, I might have been stuck in the modern buildings of West Cambridge, but fortunately there is a wonderful little bike path between the lab and Fitzwiliam college (which Nidhi mentioned to me, and which I managed to miss and end up biking down the grass at the back of Churchill college and then along side the road in the wrong direction because of a fence blocking my way):


The food might be bad in Britain, but you really can’t beat its sweets:

Alas, I have banned myself from purchasing any sweets, lest they mysteriously disappear before I return to my college. Nutella for breakfast has also proved a stunningly bad idea and I have canned the practice in favor for a pastry and two pieces of fruit. Cambridge has a market square which is open every day (good!) but does not have very much local produce (understandable but boo!)

Actually, I discovered the library on stilts because I was attempting to determine the location of an ICUSU event and, unlike at MIT, I don’t carry around my laptop everywhere with me while in Cambridge (gasp!) I eventually found the location:

If you say you are punting, it means a quite different thing in Cambridge then at MIT. Though I consulted Wikipedia, which agrees with the Cambridge sense of the term. Oh, did I mention, dogs punt too!

Punting is a bit different from sailing; in particular, you push the punt pole in the direction you want to go (whereas the tiller goes in the opposite direction you want to go.)

This post is getting a bit long, so maybe I’ll save more for later.
Postscript. I noticed a (not particularly insightful) relationship between currying and church encoding today: namely, if you curry the destructor function (either, maybe, foldr, etc) with the data, you get the function with the same type as the Church encoding of that data type.