April 11, 2011I was supposed to have another post about Hoopl today, but it got scuttled when an example program I had written triggered what I think is a bug in Hoopl (if it’s not a bug, then my mental model of how Hoopl works internally is seriously wrong, and I ought not write about it anyway.) So today’s post will be about the alleged bug Hoopl was a victim of: bugs from using the wrong variable.
The wrong variable, if I’m right, is that of the missing apostrophe:
; let (cha', fbase') = mapFoldWithKey
- (updateFact lat lbls)
+ (updateFact lat lbls')
(cha,fbase) out_facts
Actually, this bug tends to happen a lot in functional code. Here is one bug in the native code generation backend in GHC that I recently fixed with Simon Marlow:
- return (Fixed sz (getRegisterReg use_sse2 reg) nilOL)
+ return (Fixed size (getRegisterReg use_sse2 reg) nilOL)
And a while back, when I was working on abcBridge, I got an infinite loop because of something along the lines of:
cecManVerify :: Gia_Man_t -> Cec_ParCec_t_ -> IO Int
- cecManVerify a b = handleAbcError "Cec_ManVerify" $ cecManVerify a b
+ cecManVerify a b = handleAbcError "Cec_ManVerify" $ cecManVerify' a b
How does one defend against these bugs? There are various choices:
This is the classic solution for any imperative programmer: if some value is not going to be used again, overwrite it with the new value. You thus get code like this:
$string = trim($string);
$string = str_replace('/', '_', $string);
$string = ...
You can do something similar in spirit in functional programming languages by reusing the name for a new binding, which shadows the old binding. But this is something of a discouraged practice, as -Wall might suggest:
test.hs:1:24:
Warning: This binding for `a' shadows the existing binding
bound at test.hs:1:11
In the particular case that the variable is used in only one place, in this pipeline style, it’s fairly straightforward to eliminate it by writing a pipeline of functions, moving the code to point-free style (the “point” in “point-free” is the name for variable):
let z = clipJ a . clipI b . extendIJ $ getIJ (q ! (i-1) ! (j-1))
But this tends to work less well when an intermediate value needs to be used multiple times. There’s usually a way to arrange it, but “multiple uses” is a fairly good indicator of when pointfree style will become incomprehensible.
View patterns are a pretty neat language extension that allow you to avoid having to write code that looks like this:
f x y = let x' = unpack x
in ... -- using only x'
With {-# LANGUAGE ViewPatterns #-}, you can instead write:
f (unpack -> x) y = ... -- use x as if it were x'
Thus avoiding the need to create a temporary name that may be accidentally used, while allowing yourself to use names.
It only took a few seconds of staring to see what was wrong with this code:
getRegister (CmmReg reg)
= do use_sse2 <- sse2Enabled
let
sz = cmmTypeSize (cmmRegType reg)
size | not use_sse2 && isFloatSize sz = FF80
| otherwise = sz
--
return (Fixed sz (getRegisterReg use_sse2 reg) nilOL)
That’s right: size is never used in the function body. GHC will warn you about that:
test.hs:1:24: Warning: Defined but not used: `b'
Unfortunately, someone turned it off (glare):
{-# OPTIONS -w #-}
-- The above warning supression flag is a temporary kludge.
-- While working on this module you are encouraged to remove it and fix
-- any warnings in the module. See
-- http://hackage.haskell.org/trac/ghc/wiki/Commentary/CodingStyle#Warnings
-- for details
Haskell programmers tend to have a penchant for short, mathematical style names like f, g, h, x, y, z, when the scope a variable is used isn’t very large. Imperative programmers tend to find this a bit strange and unmaintainable. The reason why this is a maintainable style in Haskell is the static type system: if I’m writing the function compose f g, where f :: a -> b and g :: b -> c, I’m certain not to accidentally use g in the place of f: it will type error! If all of the semantic information about what is in the variable is wrapped up in the type, there doesn’t seem to be much point in reiterating it. Of course, it’s good not to go too far in this direction: the typechecker won’t help you much when there are two variables, both with the type Int. In that case, it’s probably better to use a teensy bit more description. Conversely, if you refine your types so that the two variables have different types again, the possibility of error goes away again.
April 8, 2011Once you’ve determined what dataflow facts you will be collecting, the next step is to write the transfer function that actually performs this analysis for you!
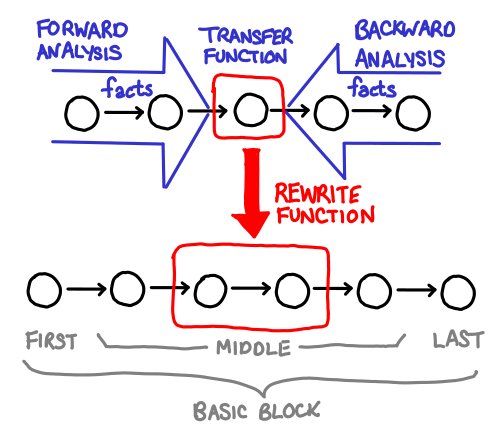
Remember what your dataflow facts mean, and this step should be relatively easy: writing a transfer function usually involves going through every possible statement in your language and thinking about how it changes your state. We’ll walk through the transfer functions for constant propagation and liveness analysis.
Here is the transfer function for liveness analysis (once again, in Live.hs):
liveness :: BwdTransfer Insn Live
liveness = mkBTransfer live
where
live :: Insn e x -> Fact x Live -> Live
live (Label _) f = f
live n@(Assign x _) f = addUses (S.delete x f) n
live n@(Store _ _) f = addUses f n
live n@(Branch l) f = addUses (fact f l) n
live n@(Cond _ tl fl) f = addUses (fact f tl `S.union` fact f fl) n
live n@(Call vs _ _ l) f = addUses (fact f l `S.difference` S.fromList vs) n
live n@(Return _) _ = addUses (fact_bot liveLattice) n
fact :: FactBase (S.Set Var) -> Label -> Live
fact f l = fromMaybe S.empty $ lookupFact l f
addUses :: S.Set Var -> Insn e x -> Live
addUses = fold_EN (fold_EE addVar)
addVar s (Var v) = S.insert v s
addVar s _ = s
live is the meat of our transfer function: it takes an instruction and the current fact, and then modifies the fact in light of that information. Because this is a backwards transfer (BwdTransfer), the Fact x Live passed to live are the dataflow facts after this instruction, and our job is to calculate what the dataflow facts are before the instruction (the facts flow backwards).
If you look closely at this function, there’s something rather curious going on: in the line live (Label _) f = f, we simply pass out f (which ostensibly has type Fact x Live) as the result. How does that work? Well, Fact is actually a type family:
type family Fact x f :: *
type instance Fact C f = FactBase f
type instance Fact O f = f
Look, it’s the O and C phantom types again! If we recall our definition of Insn (in IR.hs):
data Insn e x where
Label :: Label -> Insn C O
Assign :: Var -> Expr -> Insn O O
Store :: Expr -> Expr -> Insn O O
Branch :: Label -> Insn O C
Cond :: Expr -> Label -> Label -> Insn O C
Call :: [Var] -> String -> [Expr] -> Label -> Insn O C
Return :: [Expr] -> Insn O C
That means for any of the instructions that are open on exit (x = O for Label, Assign and Store), our function gets Live, whereas for an instruction that is closed on exit (x = C for Branch, Cond, Call and Return), we get FactBase Live, which is a map of labels to facts (LabelMap Live)—for reasons we will get to in a second.
Because the type of our arguments actually change depending on what instruction we receive, some people (GHC developers among them) prefer to use the long form mkBTransfer3, which takes three functions, one for each shape of node. The rewritten code thus looks like this:
liveness' :: BwdTransfer Insn Live
liveness' = mkBTransfer3 firstLive middleLive lastLive
where
firstLive :: Insn C O -> Live -> Live
firstLive (Label _) f = f
middleLive :: Insn O O -> Live -> Live
middleLive n@(Assign x _) f = addUses (S.delete x f) n
middleLive n@(Store _ _) f = addUses f n
lastLive :: Insn O C -> FactBase Live -> Live
lastLive n@(Branch l) f = addUses (fact f l) n
lastLive n@(Cond _ tl fl) f = addUses (fact f tl `S.union` fact f fl) n
lastLive n@(Call vs _ _ l) f = addUses (fact f l `S.difference` S.fromList vs) n
lastLive n@(Return _) _ = addUses (fact_bot liveLattice) n
(with the same definitions for fact, addUses and addVar).
With this in mind, it should be fairly easy to parse the code for firstLive and middleLive. Labels don’t change the set of live libraries, so our fact f is passed through unchanged. For assignments and stores, any uses of a register in that expression makes that register live (addUses is a utility function that calculates this), but if we assign to a register, we lose its previous value, so it is no longer live. Here is some pseudocode demonstrating:
// a is live
x = a;
// a is not live
foo();
// a is not live
a = 2;
// a is live
y = a;
If you’re curious out the implementation of addUses, the fold_EE and fold_EN functions can be found in OptSupport.hs:
fold_EE :: (a -> Expr -> a) -> a -> Expr -> a
fold_EN :: (a -> Expr -> a) -> a -> Insn e x -> a
fold_EE f z e@(Lit _) = f z e
fold_EE f z e@(Var _) = f z e
fold_EE f z e@(Load addr) = f (f z addr) e
fold_EE f z e@(Binop _ e1 e2) = f (f (f z e2) e1) e
fold_EN _ z (Label _) = z
fold_EN f z (Assign _ e) = f z e
fold_EN f z (Store addr e) = f (f z e) addr
fold_EN _ z (Branch _) = z
fold_EN f z (Cond e _ _) = f z e
fold_EN f z (Call _ _ es _) = foldl f z es
fold_EN f z (Return es) = foldl f z es
The naming convention is as follows: E represents an Expr, while N represents a Node (Insn). The left letter indicates what kind of values are passed to the combining function, while the right letter indicates what is being folded over. So fold_EN folds all Expr in a Node and calls the combining function on it, while fold_EE folds all of the Expr inside an Expr (notice that things like Load and Binop can contain expressions inside themselves!) The effect of fold_EN (fold_EE f), then, is that f will be called on every expression in a node, which is exactly what we want if we’re checking for uses of Var.
We could have also written out the recursion explicitly:
addUses :: S.Set Var -> Insn e x -> Live
addUses s (Assign _ e) = expr s e
addUses s (Store e1 e2) = expr (expr s e1) e2
addUses s (Cond e _ _) = expr s e
addUses s (Call _ _ es _) = foldl expr s es
addUses s (Return es) = foldl expr s es
addUses s _ = s
expr :: S.Set Var -> Expr -> Live
expr s e@(Load e') = addVar (addVar s e) e'
expr s e@(Binop _ e1 e2) = addVar (addVar (addVar s e) e1) e2
expr s e = addVar s e
But as you can see, there’s a lot of junk involved with recursing down the structure, and you might accidentally forget an Expr somewhere, so using a pre-defined fold operator is preferred. Still, if you’re not comfortable with folds over complicated datatypes, writing out the entire thing in full at least once is a good exercise.
The last part to look at is lastLives:
lastLive :: Insn O C -> FactBase Live -> Live
lastLive n@(Branch l) f = addUses (fact f l) n
lastLive n@(Cond _ tl fl) f = addUses (fact f tl `S.union` fact f fl) n
lastLive n@(Call vs _ _ l) f = addUses (fact f l `S.difference` S.fromList vs) n
lastLive n@(Return _) _ = addUses (fact_bot liveLattice) n
There are several questions to ask.
Why does it receive a FactBase Live instead of a Live? This is because, as the end node in a backwards analysis, we may receive facts from multiple locations: each of the possible paths the control flow may go down.
In the case of a Return, there are no further paths, so we use fact_bot liveLattice (no live variables). In the case of Branch and Call, there is only one further path l (the label we’re branching or returning to), so we simply invoke fact f l. And finaly, for Cond there are two paths: tl and fl, so we have to grab the facts for both of them and combine them with what happens to be our join operation on the dataflow lattice.
Why do we still need to call addUses? Because instructions at the end of basic blocks can use variables (Cond may use them in its conditional statement, Return may use them when specifying what it returns, etc.)
What’s with the call to S.difference in Call? Recall that vs is the list of variables that the function call writes its return results to. So we need to remove those variables from the live variable set, since they will get overwritten by this instruction:
f (x, y) {
L100:
goto L101
L101:
if x > 0 then goto L102 else goto L104
L102:
// z is not live here
(z) = f(x-1, y-1) goto L103
L103:
// z is live here
y = y + z
x = x - 1
goto L101
L104:
ret (y)
}
You should already have figured out what fact does: it looks up the set of dataflow facts associated with a label, and returns an empty set (no live variables) if that label isn’t in our map yet.
Once you’ve seen one Hoopl analysis, you’ve seen them all! The transfer function for constant propagation looks very similar:
-- Only interesting semantic choice: values of variables are live across
-- a call site.
-- Note that we don't need a case for x := y, where y holds a constant.
-- We can write the simplest solution and rely on the interleaved optimization.
--------------------------------------------------
-- Analysis: variable equals a literal constant
varHasLit :: FwdTransfer Node ConstFact
varHasLit = mkFTransfer ft
where
ft :: Node e x -> ConstFact -> Fact x ConstFact
ft (Label _) f = f
ft (Assign x (Lit k)) f = Map.insert x (PElem k) f
ft (Assign x _) f = Map.insert x Top f
ft (Store _ _) f = f
ft (Branch l) f = mapSingleton l f
ft (Cond (Var x) tl fl) f
= mkFactBase constLattice
[(tl, Map.insert x (PElem (Bool True)) f),
(fl, Map.insert x (PElem (Bool False)) f)]
ft (Cond _ tl fl) f
= mkFactBase constLattice [(tl, f), (fl, f)]
ft (Call vs _ _ bid) f = mapSingleton bid (foldl toTop f vs)
where toTop f v = Map.insert v Top f
ft (Return _) _ = mapEmpty
The notable difference is that, unlike liveness analysis, constant propagation analysis is a forward analysis FwdTransfer. This also means the type of the function is Node e x -> f -> Fact x f, rather than Node e x -> Fact x f -> f: when the control flow splits, we can give different sets of facts for the possible outgoing labels. This is used to good effect in Cond (Var x), where we know that if we take the first branch the condition variable is true, and vice-versa. The rest is plumbing:
Branch: An unconditional branch doesn’t cause any of our variables to stop being constant. Hoopl will automatically notice if a different path to that label has contradictory facts and convert the mappings to Top as notice, using our lattice’s join function. mapSingleton creates a singleton map from the label l to the fact f.Cond: We need to create a map with two entries, which is can be done conveniently with mkFactBase, where the last argument is a list of labels to maps.Call: A function call is equivalent to assigning lots of unknown variables to all of its return variables, so we set all of them to unknown with toTop.Return: Goes nowhere, so an empty map will do.
Next time, we’ll talk about some of the finer subtleties about transfer functions and join functions, and discuss graph rewriting, and wrap it all up with some use of Hoopl’s debugging facilities to observe how Hoopl rewrites a graph.
April 5, 2011The imperative. When should you create a custom data type, as opposed to reusing pre-existing data types such as Either, Maybe or tuples? Here are some reasons you should reuse a generic type:
- It saves typing (both in declaration and in pattern matching), making it good for one-off affairs,
- It gives you a library of predefined functions that work with that type,
- Other developers have expectations about what the type does that make understanding quicker.
On the flip side of the coin:
- You may lose semantic distinction between types that are the same but have different meanings (the newtype argument),
- The existing type may allow more values than you intended to allow,
- Other developers have expectations about what the type does that can cause problems if you mean something different.
In this post, I’d like to talk about those last two problems with reusing custom types, using two case studies from the GHC codebase, and how the problems where alleviated by defining a data type that was only used by a small section of the codebase.
Great expectations. The Maybe type, by itself, has a very straight-forward interpretation: you either have the value, or you don’t. Even when Nothing means something like Wildcard or Null or UseTheDefault, the meaning is usually fairly clear.
What is more interesting, however, is when Maybe is placed in another data type that has its own conception of nothing-ness. A very simple example is Maybe (Maybe a), which admits the values Nothing, Just Nothing or Just (Just a). What is Just Nothing supposed to mean? In this case, what we really have masquerading here is a case of a data type with three constructors: data Maybe2 a = Nothing1 | Nothing2 | Just a. If we intend to distinguish between Nothing and Just Nothing, we need to assign some different semantic meaning to them, meaning that is not obvious from the cobbled together data type.
Another example, which comes from Hoopl and GHC, is the curious case of Map Var (Maybe Lit). A map already has its own conception of nothingness: that is, when the key-value pair is not in the map at all! So the first thing a developer who encounters this code may ask is, “Why isn’t it just Map Var Lit?” The answer to this question, for those of you have read the dataflow lattice post, is that Nothing in this circumstance, represents top (there is variable is definitely not constant), which is different from absence in the map, which represents bottom (the variable is constant or not constant). I managed to confuse both the Simons with this strange piece of code, and after taking some time to explain the situation, and they immediately recommended that I make a custom data type for the purpose. Even better, I found that Hoopl already provided this very type: HasTop, which also had a number of utility functions that reflected this set of semantics. Fortuitous indeed!
Uninvited guests. Our example of a data type that allows too many values comes from the linear register allocator in GHC (compiler/nativeGen/RegAlloc/Linear/Main.hs). Don’t worry, you don’t need to know how to implement a linear register allocator to follow along.
The linear register allocator is a rather large and unwieldy beast. Here is the function that actually allocates and spills the registers:
allocateRegsAndSpill reading keep spills alloc (r:rs)
= do assig <- getAssigR
case lookupUFM assig r of
-- case (1a): already in a register
Just (InReg my_reg) ->
allocateRegsAndSpill reading keep spills (my_reg:alloc) rs
-- case (1b): already in a register (and memory)
-- NB1. if we're writing this register, update its assignment to be
-- InReg, because the memory value is no longer valid.
-- NB2. This is why we must process written registers here, even if they
-- are also read by the same instruction.
Just (InBoth my_reg _)
-> do when (not reading) (setAssigR (addToUFM assig r (InReg my_reg)))
allocateRegsAndSpill reading keep spills (my_reg:alloc) rs
-- Not already in a register, so we need to find a free one...
loc -> allocRegsAndSpill_spill reading keep spills alloc r rs loc assig
There’s a bit of noise here, but the important things to notice is that it’s a mostly recursive function. The first two cases of lookupUFM directly call allocateRegsAndSpill, but the last case needs to do something complicated, and calls the helper function allocRegsAndSpill_spill. It turns out that this function will always eventually call allocateRegsAndSpill, so we have two mutually recursive functions. The original was probably just recursive, but the long bit handling “Not already in a register, so we need to find a free one” got factored out at some point.
This code is reusing a data type! Can you see it? It’s very subtle, because the original use of the type is legitimate, but it is then reused in an inappropriate manner. The answer is loc, in the last case statement. In particular, because we’ve already case-matched on loc, we know that it can’t possibly be Just (InReg{}) or Just (InBoth{}). If we look at the declaration of Loc, we see that there are only two cases left:
data Loc
-- | vreg is in a register
= InReg !RealReg
-- | vreg is held in a stack slot
| InMem {-# UNPACK #-} !StackSlot
-- | vreg is held in both a register and a stack slot
| InBoth !RealReg
{-# UNPACK #-} !StackSlot
deriving (Eq, Show, Ord)
That is, the only remaining cases are Just (InMem{}) and Nothing. This is fairly important, because we lean on this invariant later in allocRegsAndSpill_spill:
let new_loc
-- if the tmp was in a slot, then now its in a reg as well
| Just (InMem slot) <- loc
, reading
= InBoth my_reg slot
-- tmp has been loaded into a reg
| otherwise
= InReg my_reg
If you hadn’t seen the original case split in allocateRegsAndSpill, this particular code may have got you wondering if the last guard also applied when the result was Just (InReg{}), in which case the behavior would be very wrong. In fact, if we are reading, loc must be Nothing in that last branch. But there’s no way of saying that as the code stands: you’d have to add some panics and it gets quite messy:
let new_loc
-- if the tmp was in a slot, then now its in a reg as well
| Just (InMem slot) <- loc
= if reading then InBoth my_reg slot else InReg my_reg
-- tmp has been loaded into a reg
| Nothing <- loc
= InReg my_reg
| otherwise = panic "Impossible situation!"
Furthermore, we notice a really interesting extra invariant: what happens if we’re reading from a location that has never been assigned to before (that is, reading is True and loc is Nothing)? That is obviously bogus, so in fact we should check if that’s the case. Notice that the original code did not enforce this invariant, which was masked out by the use of otherwise.
Rather than panic on an impossible situation, we should statically rule out this possibility. We can do this simply by introducing a new data type for loc, and pattern-matching appropriately:
-- Why are we performing a spill?
data SpillLoc = ReadMem StackSlot -- reading from register only in memory
| WriteNew -- writing to a new variable
| WriteMem -- writing to register only in memory
-- Note that ReadNew is not valid, since you don't want to be reading
-- from an uninitialized register. We also don't need the location of
-- the register in memory, since that will be invalidated by the write.
-- Technically, we could coalesce WriteNew and WriteMem into a single
-- entry as well. -- EZY
allocateRegsAndSpill reading keep spills alloc (r:rs)
= do assig <- getAssigR
let doSpill = allocRegsAndSpill_spill reading keep spills alloc r rs assig
case lookupUFM assig r of
-- case (1a): already in a register
Just (InReg my_reg) ->
allocateRegsAndSpill reading keep spills (my_reg:alloc) rs
-- case (1b): already in a register (and memory)
-- NB1. if we're writing this register, update its assignment to be
-- InReg, because the memory value is no longer valid.
-- NB2. This is why we must process written registers here, even if they
-- are also read by the same instruction.
Just (InBoth my_reg _)
-> do when (not reading) (setAssigR (addToUFM assig r (InReg my_reg)))
allocateRegsAndSpill reading keep spills (my_reg:alloc) rs
-- Not already in a register, so we need to find a free one...
Just (InMem slot) | reading -> doSpill (ReadMem slot)
| otherwise -> doSpill WriteMem
Nothing | reading -> pprPanic "allocateRegsAndSpill: Cannot read from uninitialized register" (ppr r)
| otherwise -> doSpill WriteNew
And now the pattern match inside allocateRegsAndSpill_spill is nice and tidy:
-- | Calculate a new location after a register has been loaded.
newLocation :: SpillLoc -> RealReg -> Loc
-- if the tmp was read from a slot, then now its in a reg as well
newLocation (ReadMem slot) my_reg = InBoth my_reg slot
-- writes will always result in only the register being available
newLocation _ my_reg = InReg my_reg
April 4, 2011The essence of dataflow optimization is analysis and transformation, and it should come as no surprise that once you’ve defined your intermediate representation, the majority of your work with Hoopl will involve defining analysis and transformations on your graph of basic blocks. Analysis itself can be further divided into the specification of the dataflow facts that we are computing, and how we derive these dataflow facts during analysis. In part 2 of this series on Hoopl, we look at the fundamental structure backing analysis: the dataflow lattice. We discuss the theoretical reasons behind using a lattice and give examples of lattices you may define for optimizations such as constant propagation and liveness analysis.
Despite its complicated sounding name, dataflow analysis remarkably resembles the way human programmers might reason about code without actually running it on a computer. We start off with some initial belief about the state of the system, and then as we step through instructions we update our belief with new information. For example, if I have the following code:
f(x) {
a = 3;
b = 4;
return (x * a + b);
}
At the very top of the function, I don’t know anything about x. When I see the expressions a = 3 and b = 4, I know that a is equal to 3 and b is equal to 4. In the least expression, I could use constant propagation to simplify the result to x * 3 + 4. Indeed, in the absence of control flow, we can think of analysis simply as stepping through the code line by line and updating our assumptions, also called dataflow facts. We can do this in both directions: the analysis we just did above was forwards analysis, but we can also do backwards analysis, which is the case for liveness analysis.
Alas, if only things were this simple! There are two spanners in the works here: Y-shaped control flows and looping control flows.
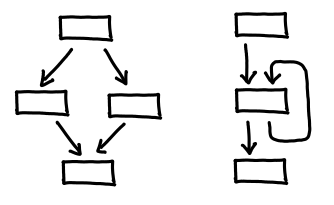
Y-shaped control flows (called joins, for both obvious reasons and reasons that will become clear soon) are so named because there are two, distinct paths of execution that then merge into one. We then have two beliefs about the state of the program, which we need to reconcile before carrying on:
f(x) {
if (x) {
a = 2; // branch A
} else {
a = 3; // branch B
}
return a;
}
Inside branch A, we know that a is 2, and inside branch B, we know a is 3, but outside this conditional, all we can say is that a is either 2 or 3. (Since two possible values isn’t very useful for constant propagation, we’ll instead say the value of a is top: there is no one value that represents the value held at a.) The upshot is that any set of dataflow facts you are doing analysis with must have a join operation defined:
data DataflowFactsTry1 a = DF1 { fact_join :: a -> a -> a }
There is an analogous situation for backwards analysis, which occurs when you have a conditional jump: two “futures” of the control flow join back together, and so a similar join needs to occur.
Looping control flows also have joins, but they have the further problem that we don’t know what one of the incoming code path’s state is: we can’t figure it out until we’ve analyzed the loop body, but to analyze the loop body, we need to know what the incoming state is. It’s a Catch-22! The trick to work around this is to define a bottom fact, which intuitively represents the most conservative dataflow fact possible: it is the identity when joined some other dataflow fact. So when we encounter one of these loop edges, instead of attempting to calculate the edge (which is a Catch-22 problem), we instead feed in the bottom element, and get an approximation of what the fact at that loop edge is. If this approximation is better than bottom, we feed the new result in instead, and the process repeats until there are no more changes: a fixpoint has been achieved.
With join and bottom in hand, the mathematically inclined may notice that what we’ve defined looks a lot like a lattice:
data DataflowLattice a = DataflowLattice
{ fact_name :: String -- Documentation
, fact_bot :: a -- Lattice bottom element
, fact_join :: JoinFun a -- Lattice join plus change flag
-- (changes iff result > old fact)
}
type JoinFun a = Label -> OldFact a -> NewFact a -> (ChangeFlag, a)
There is a little bit of extra noise in here: Label is included strictly for debugging purposes (it tells the join function what label the join is occurring on) and ChangeFlag is included for optimization purposes: it lets fact_join efficiently say when the fixpoint has been achieved: NoChange.
Aside: Lattices. Here, we review some basic terminology and intuition for lattices. A lattice is a partially ordered set, for which least upper bounds (lub) and greatest lower bounds (glb) exist for all pairs of elements. If one imagines a Hasse diagram, the existence of a least upper bound means that I can follow the diagram upwards from two elements until I reach a shared element; the greatest least bound is the same process downwards. The least upper bound is also called the join of two elements, and the greatest least bound the meet. (I prefer lub and glb because I always mix join and meet up!) Notationally, the least upper bound is represented with the logical or symbol or a square union operator, while the greatest least bound is represented with the logical and symbol or square intersection operator. The choice of symbols is suggestive: the overloading of logical symbols corresponds to the fact that logical propositions can have their semantics defined using a special kind of lattice called a boolean algebra, where lub is equivalent to or and glb is equivalent to and (bottom is falsity and top is tautology). The overloading of set operators corresponds to the lattice on the usual ordering of the powerset construction: lub is set union and glb is set intersection.
In Hoopl, we deal with bounded lattices, lattices for which a top and bottom element exist. These are special elements that are greater than and less than (respectively) than all other elements. Joining the bottom element with any other element is a no-op: the other element is the result (this is why we use bottom as our initialization value!) Joining the top element with any other element results in the top element (thus, if you get to the top, you’re “stuck”, so to speak).
For the pedantic, strictly speaking, Hoopl doesn’t need a lattice: instead, we need a bounded semilattice (since we only require joins, and not meets, to be defined.) There is another infelicity: the Lerner-Grove-Chambers and Hoopl uses bottom and join, but most of the existing literature on dataflow lattices uses top and meet (essentially, flip the lattice upside down.) In fact, which choice is “natural” depends on the analysis: as we will see, liveness analysis naturally suggests using bottom and join, while constant propagation suggests using top and meet. To be consistent with Hoopl, we’ll use bottom and join consistently; as long as we’re consistent, the lattice orientation doesn’t matter.
We will now look at concrete examples of using the dataflow lattices for liveness analysis and constant propagation. These two examples give a nice spread of lattices to look at: liveness analysis is a set of variable names, while constant propagation is a map of variable names to a flat lattice of possible values.
Liveness analysis (Live.hs) uses a very simple lattice, so it serves as a good introductory example for the extra ceremony that is involved in setting up a DataflowLattice:
type Live = S.Set Var
liveLattice :: DataflowLattice Live
liveLattice = DataflowLattice
{ fact_name = "Live variables"
, fact_bot = S.empty
, fact_join = add
}
where add _ (OldFact old) (NewFact new) = (ch, j)
where
j = new `S.union` old
ch = changeIf (S.size j > S.size old)
The type Live is the type of our data flow facts. This represents is the set of variables that are live (that is, will be used by later code):
f() {
// live: {x, y}
x = 3;
y = 4;
y = x + 2;
// live: {y}
return y;
// live: {}
}
Remember that liveness analysis is a backwards analysis: we start at the bottom of our procedure and work our way up: a usage of a variable means that it’s live for all points above it. We fill in DataflowLattice with documentation, the distinguished element (bottom) and the operation on these facts (join). Var is Expr.hs and simply is a string name of the variable. Our bottom element (which is used to initialize edges that we can’t calculate right off the bat) is the empty set, since at the bottom of any procedure, all variables are dead.
Join is set union, which can be clearly seen in this example:
f (x) {
// live: {a,b,x,r} (union of the two branches,
// as well as x, due to its usage in the conditional)
a = 2;
b = 3;
if (x) {
// live: {a,r}
r = a;
} else {
// live: {b,r}
r = b;
}
// live: {r}
return r;
// live: {}
}
We also see some code for calculating the change ch, which is a simple size comparison of sets, because union will only ever increase the size of a set, not decrease it. changeIf is a utility function that takes Bool to ChangeFlag.
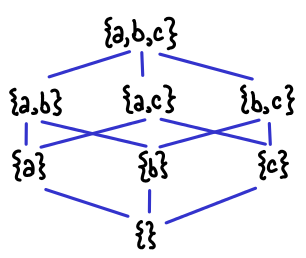
Here is an illustration of the lattice structure if we have three variables: it’s simply the usual ordering on the powerset construction.
Here is the lattice for constant propagation (ConstProp.hs). It is slightly more complicated than the live set, though some of the complexity is hidden by the fact that Hoopl provides some utility data types and functions:
-- ConstFact:
-- Not present in map => bottom
-- PElem v => variable has value v
-- Top => variable's value is not constant
type ConstFact = Map.Map Var (WithTop Lit)
constLattice :: DataflowLattice ConstFact
constLattice = DataflowLattice
{ fact_name = "Const var value"
, fact_bot = Map.empty
, fact_join = joinMaps (extendJoinDomain constFactAdd) }
where
constFactAdd _ (OldFact old) (NewFact new)
= if new == old then (NoChange, PElem new)
else (SomeChange, Top)
There are essentially two lattices in this construction. The “outer” lattice is the map, for which the bottom element is the empty map and the join is joining two maps together, merging elements using the inner lattice. The “inner” (semi)lattice is WithTop Lit, which is provided by Hoopl. (One may say that the inner lattice is pointwise lifted into the map.) We illustrate the inner lattice here for variables containing booleans:
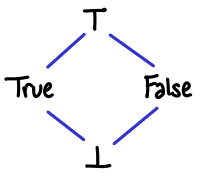
One thing to stress about the inner lattice is the difference between bottom and top. Both represent a sort of “not knowing about the contents of a variable”, but in the case of bottom, the variable may be constant or it may not be constant, whereas in top, the variable is definitely not constant. It is easy to get tripped up saying things like, “bottom means that we don’t know what the value of the variable is” and “top means that the value of the variable could be anything.” If we think of this lattice as a set, with {True} indicating that the value of this variable is true, then {True,False} (bottom) indicates the variable could be a constant true or constant false, not that the variable could be true or false. This also means we can interpret {} (top) appropriately: there is no value for which this variable is a constant. (Notice that this is the powerset lattice flipped upside down!)
There are a few interesting utility functions in this example: extendJoinDomain and joinMaps. extendJoinDomain saves us the drudgery from having to write out all of the interactions with top in full, e.g.:
constFactAddExtended _ (OldFact old) (NewFact new)
= case (old, new) of
(Top, _) -> (NoChange, Top)
(_, Top) -> (SomeChange, Top)
(PElem old, PElem new) | new == old -> (NoChange, PElem new)
| otherwise -> (SomeChange, Top)
joinMaps lifts our inner lattice into map form, and also takes care of the ChangeFlag plumbing (output SomeChange if any entry in the new map wasn’t present in the old map, or if any of the joined entries changed).
That concludes our discussion of Hoopl and dataflow lattices. We haven’t covered all of the functions Hoopl provides to manipulate dataflow lattices; here are some further modules to look at:
Compiler.Hoopl.Combinators defines pairLattice, which takes the product construction of two lattices. It can be used to easily perform multiple analyses at the same time.Compiler.Hoopl.Pointed defines a number of auxiliary data structures and functions for adding Top and Bottom to existing data types. This is where extendJoinDomain comes from.Compiler.Hoopl.Collections and Compiler.Hoopl.Unique define maps and sets on unique keys (most prominently, labels). You will most probably be using these for your dataflow lattices.
Next time, we will talk about transfer functions, the mechanism by which we calculate dataflow facts.
Further reading. Dataflow lattices are covered in chapter 10.11 of Compilers: Principles, Techniques and Tools (the Red Dragon Book). The original paper was Kildall’s 1973 paper A unified approach to global program optimization. Interestingly enough, the Dragon Book remarks that “it has not seen widespread use, probably because the amount of labor saved by the system is not as great as that saved by tools like parser generators.” My feeling is that this is the case for traditional compiler optimization passes, but not for Lerner-Grove-Chambers style passes (where analysis and rewriting are interleaved.)
April 1, 2011Hoopl is a higher-order optimization library. We think it’s pretty cool! This series of blog post is meant to give a tutorial-like introduction to this library, supplementing the papers and the source code. I hope this series will also have something for people who aren’t interested in writing optimization passes with Hoopl, but are interested in the design of higher-order APIs in Haskell. By the end of this tutorial, you will be able to understand references in code to names such as analyzeAndRewriteFwd and DataflowLattice, and make decode such type signatures as:
analyzeAndRewriteFwd
:: forall m n f e x entries. (CheckpointMonad m, NonLocal n, LabelsPtr entries)
=> FwdPass m n f
-> MaybeC e entries
-> Graph n e x -> Fact e f
-> m (Graph n e x, FactBase f, MaybeO x f)
We assume basic familiarity with functional programming and compiler technology, but I will give asides to introduce appropriate basic concepts.
Aside: Introduction. People already familiar with the subject being discussed can feel free to skip sections that are formatted like this.
We will be giving a guided tour of the testing subdirectory of Hoopl, which contains a sample client. (You can grab a copy by cloning the Git repository git clone git://ghc.cs.tufts.edu/hoopl/hoopl.git). You can get your bearings by checking out the README file. The first set of files we’ll be checking out is the “Base System” which defines the data types for the abstract syntax tree and the Hoopl-fied intermediate representation.
The abstract syntax is about as standard as it gets (Ast.hs):
data Proc = Proc { name :: String, args :: [Var], body :: [Block] }
data Block = Block { first :: Lbl, mids :: [Insn], last :: Control }
data Insn = Assign Var Expr
| Store Expr Expr
data Control = Branch Lbl
| Cond Expr Lbl Lbl
| Call [Var] String [Expr] Lbl
| Return [Expr]
type Lbl = String
We have a language of named procedures, which consist of basic blocks. We support unconditional branches Branch, conditional branches Cond, function calls Call (the [Var] is the variables to store the return values, the String is the name of the function, the [Expr] are the arguments, and the Lbl is where to jump to when the function call is done), and function returns Return (multiple return is supported, thus [Expr] rather than Expr).
We don’t have any higher-level flow control constructs (the language’s idea of control flow is a lot of gotos—don’t worry, this will work in our favor), so we might expect it to be very easy to map this “high-level assembly language” to machine code fairly easily, and this is indeed the case (very notably, however, this language doesn’t require you to think about register allocation, but how we use variables will very noticeably impact register allocation). A real-world example of high-level assembly languages includes C–.
Here is a simple example of some code that might be written in this language:
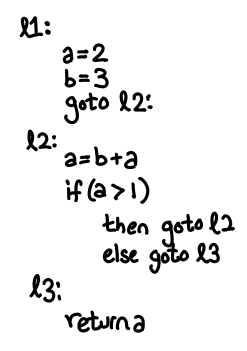
Aside: Basic blocks. Completely explaining what an abstract syntax tree (AST) is a bit beyond the scope of this post, but you if you know how to write a Scheme interpreter in Haskell you already know most of the idea for the expressions component of the language: things like binary operators and variables (e.g. a + b). We then extend this calculator with low-level imperative features in the obvious way. If you’ve done any imperative programming, most of these features are also familiar (branches, function calls, variable assignments): the single new concept is that of the basic block. A basic block is an atomic unit of flow control: if I’ve entered a basic block, I know that I will emerge out the other end, no ifs, ands or buts. This means that there will be no nonlocal transfer of control from inside the block (e.g. no exceptions), and there will be no code that can jump to a point inside this block (e.g. no goto). Any control flow occurs at the end of the basic block, where we may unconditionally jump to another block, or make a function call, etc. Real programs won’t be written this way, but we easily convert them into this form, and we will want this style of representation because it will make it easier to do dataflow analysis. As such, our example abstract syntax tree doesn’t really resemble an imperative language you would program in, but it is easily something you might target during code generation, so the example abstract-syntax tree is setup in this manner.
Hoopl is abstract over the underlying representation, but unfortunately, we can’t use this AST as it stands; Hoopl has its own graph representation. We wouldn’t want to use our representation anyway: we’ve represented the control flow graph as a list of blocks [Block]. If I wanted to pull out the block for some particular label; I’d have to iterate over the entire list. Rather than invent our own more efficient representation for blocks (something like a map of labels to blocks), Hoopl gives us a representation Graph n e x (it is, after all, going to have to operate on this representation). The n stands for “node”, you supply the data structure that makes up the nodes of the graph, while Hoopl manages the graph itself. The e and the x parameters will be used to store information about what the shape of the node is, and don’t represent any particular data.
Here is our intermediate representation (IR.hs):
data Proc = Proc { name :: String, args :: [Var], entry :: Label, body :: Graph Insn C C }
data Insn e x where
Label :: Label -> Insn C O
Assign :: Var -> Expr -> Insn O O
Store :: Expr -> Expr -> Insn O O
Branch :: Label -> Insn O C
Cond :: Expr -> Label -> Label -> Insn O C
Call :: [Var] -> String -> [Expr] -> Label -> Insn O C
Return :: [Expr] -> Insn O C
The notable differences are:
Proc has Graph Insn C C as its body, rather than [Block]. Also, because Graph has no conception of a “first” block, we have to explicitly say what the entry is with entry.- Instead of using
String as Lbl, we’ve switched to a Hoopl provided Label data type. Insn, Control and Label have all been squashed into a single Insn generalized abstract data type (GADT) that handles all of them.
Importantly, however, we’ve maintained the information about what shape the node is via the e and x parameters. e stands for entry, x stands for exit, O stands for open, and C stands for closed. Every instruction has a shape, which you can imagine to be a series of pipes, which you are connecting together. Pipes with the shape C O (closed at the entrance, open at the exit) start the block, pipes with the shape O C (open at the entrance, closed at the exit) end the block, and you can have any number of O O pipes in-between. We can see that Insn C O corresponds to our old data type Ast.Lbl, Insn O O corresponds to Ast.Insn, and Insn O C corresponds to Ast.Control. When we put nodes together, we get graphs, which also can be variously open or closed.
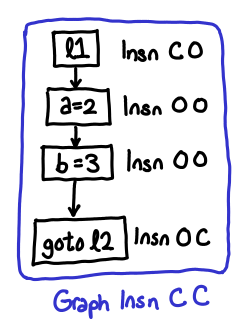
Aside: Generalized Abstract Data Types. GADTs are an indispensable swiss army knife for type-level programming. In this aside, we briefly describe some tricks (ala subtyping) that can be used with Insn e x we gave above.
The first “trick” is that you can ignore the phantom type variable entirely, and use Insn like an ordinary data type:
isLabel :: Insn e x -> Bool
isLabel Label{} = True
isLabel _ = False
I can pass this function a Label and it will return me True, or I can pass it a Branch and it will return me False. Pattern-matching on the GADT does not result in type refinement that I care about in this particular example, because there is no type variable e or x in the fields of any of the constructors or the return type of the function.
Of course, I could have written this function in such a way that it would be impossible to pass something that is not a Label to it:
assertLabel :: Insn C O -> Bool
assertLabel Label{} = True
If you try making a call assertLabel (Branch undefined), you’ll get this nice type error from GHC:
<interactive>:1:13:
Couldn't match expected type `C' against inferred type `O'
Expected type: Insn C O
Inferred type: Insn O C
In the first argument of `assertLabel', namely `(Branch undefined)'
In the expression: assertLabel (Branch undefined)
Let’s unpack this: any constructor Branch will result in a value of type Insn O C. However, the type signature of our function states Insn C O, and C ≠ O. The type error is quite straight-forward, and exactly enough to tell us what’s gone wrong!
Similarly, I can write a different function:
transferMiddle :: Insn O O -> Bool
transferMiddle Assign{} = True
transferMiddle Store{} = False
There’s no type-level way to distinguish between Assign and Store, but I don’t have to provide pattern matches against anything else in the data type: Insn O O means I only need to handle constructors that fit this shape.
I can even partially specify what the allowed shapes are:
transferMiddleOrEnd :: Insn O x -> Bool
For this function, I would need to provide pattern matches against the instructions and the control operators, but not a pattern match for IR.Label. This is not something I could have done easily with the original AST: I would have needed to create a sum type Ast.InsnOrControl.
Quick question. If I have a function that takes Insn e x as an argument, and I’d like to pass this value to a function that only takes Insn C x, what do I have to do? What about the other way around?
Exercise. Suppose you were designing a Graph representation for Hoopl, but you couldn’t use GADTs. What would the difference between a representation Graph IR.Insn (where IR.Insn is just like our IR GADT, but without the phantom types) and a representation Graph Ast.Label Ast.Insn Ast.Control?
The last file we’ll look at today is a bit of plumbing, for converting abstract syntax trees into the intermediate representation, Ast2ir.hs. Since there’s some name overloading going on, we use A. to prefix data types from Ast and I. to prefix data types from IR. The main function is astToIR:
astToIR :: A.Proc -> I.M I.Proc
astToIR (A.Proc {A.name = n, A.args = as, A.body = b}) = run $
do entry <- getEntry b
body <- toBody b
return $ I.Proc { I.name = n, I.args = as, I.body = body, I.entry = entry }
The code is monadic because as we convert Strings into Labels (which are internally arbitrary, unique integers), we need to keep track of what labels we’ve already assigned so that same string turns into the same label. The monad itself is an ordinary state monad transformer on top of a “fresh labels” monad. (There’s actually another monad in the stack; see IR.M for more details, but it’s not used at this stage so we ignore it.)
getEntry looks at the first block in the body of the procedure and uses that to determine the entry point:
getEntry :: [A.Block] -> LabelMapM Label
getEntry [] = error "Parsed procedures should not be empty"
getEntry (b : _) = labelFor $ A.first b
labelFor is a monadic function that gets us a fresh label if we’ve never seen the string Lbl name before, or the existing one if we already have seen it.
toBody uses some more interesting Hoopl functions:
toBody :: [A.Block] -> LabelMapM (Graph I.Insn C C)
toBody bs =
do g <- foldl (liftM2 (|*><*|)) (return emptyClosedGraph) (map toBlock bs)
getBody g
The Hoopl provided functions here are |*><*| and emptyClosedGraph. Note that Hoopl graphs don’t have to be connected (that is, they can contain multiple basic blocks), thus |*><*| is a kind of graph concatenation operator that connects two closed graphs together (Graph n e C -> Graph n C x -> Graph n e x), that might be connected via an indirect control operator (we have no way of knowing this except at runtime, though—thus those arrows are drawn in red). It’s a bit of an unwieldy operator, because Hoopl wants to encourage you to use <*> as far as possible.
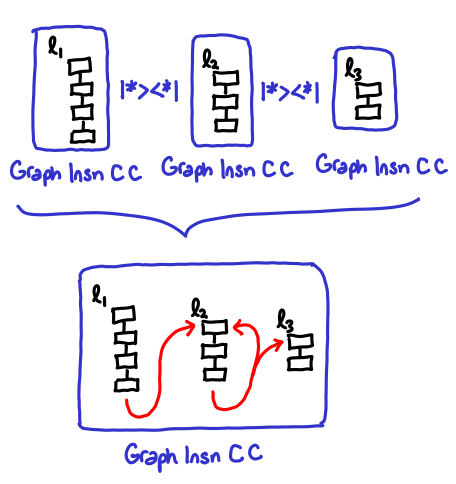
toBlock gives an example of <*>:
toBlock :: A.Block -> LabelMapM (Graph I.Insn C C)
toBlock (A.Block { A.first = f, A.mids = ms, A.last = l }) =
do f' <- toFirst f
ms' <- mapM toMid ms
l' <- toLast l
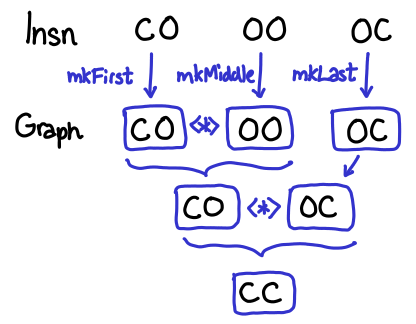
return $ mkFirst f' <*> mkMiddles ms' <*> mkLast l'
We work our way from the bottom up. What are the types of mkFirst f', mkMiddle ms', and mkLast l'? They’re all (Graph I.Insn e x), but f' is C O, ms' is O O, and l' is O C. We build up partial graphs, which are not closed on both sides, and then join them together using <*>, which requires join point between both graphs to be open: Graph n e O -> Graph n O x -> Graph n e x. mkFirst and mkMiddles and mkLast are functions provided by Hoopl that lift I.Insn e x into (Graph I.Insn e x) (or, in the case of mkMiddles, [I.Insn O O]).
And finally, toFirst, toMid and toLast actually perform the translation:
toFirst :: A.Lbl -> LabelMapM (I.Insn C O)
toFirst = liftM I.Label . labelFor
toMid :: A.Insn -> LabelMapM (I.Insn O O)
toMid (A.Assign v e) = return $ I.Assign v e
toMid (A.Store a e) = return $ I.Store a e
toLast :: A.Control -> LabelMapM (I.Insn O C)
toLast (A.Branch l) = labelFor l >>= return . I.Branch
toLast (A.Cond e t f) = labelFor t >>= \t' ->
labelFor f >>= \f' -> return (I.Cond e t' f')
toLast (A.Call rs f as l) = labelFor l >>= return . I.Call rs f as
toLast (A.Return es) = return $ I.Return es
Notice that we’re careful to specify the return shapes, so that we can use mkFirst, mkMiddles and mkLast. The most interesting thing that happens is we have to convert Lbl strings into Label; otherwise, the code is trivial.
That wraps it up for data representation, next time we’ll look at analysis of dataflow facts in Hoopl.
March 30, 2011From cvs-ghc@haskell.org:
Hi all,
We now plan to do the git switchover this Thursday, 31 March.
Thanks
Ian
There are some things that I will miss from Darcs (darcs send and the cases where “everything is a patch” actually does work well), but all and all I’m quite pleased to see GHC moving to Git.
March 28, 2011The release cycle gets longer and longer… probably to the delight of all those downstream, anyway.
HTML Purifier 4.3.0 is a major security release addressing various security vulnerabilities related to user-submitted code and legitimate client-side scripts. It also contains an accumulation of new features and bugfixes over half a year. New configuration options include %CSS.Trusted, %CSS.AllowedFonts and %Cache.SerializerPermissions. There is a backwards-incompatible API change for customized raw definitions, see the customization documentation for details.
HTML Purifier is a standards-compliant HTML filter library written in PHP (gasp!).
Non sequitur. While researching the security vulnerabilities that were fixed in this version of HTML Purifier, a thought occurred to me: how easy is it to do programming with higher-order functions in JavaScript? JavaScript is extremely fluent when it comes to passing functions around (one might say its OOP facilities are simply taking some base structure and placing functions on it), but the lack of a type system means that it might get kind of annoying documenting the fact that some particular function has some weird higher-order type like Direction -> DataflowLattice -> (Block -> Fact -> (DG, Fact)) -> [Block] -> (Fact -> DG, Fact) (simplified real example, I kid you not!). My experience with the matter in Python is that it just takes too long to explain this sort of thing to ones colleagues, and debugging them is a headache (it’s… hard to inspect functions to see what you got) so it’s better to leave it out.
March 25, 2011Yesterday I cycled from Cambridge to Ely, and back again. The route is a glorious 38 miles (round trip) of British towns and countryside. The cycling around Cambridge is quite good, because there aren’t very many hills, and in the farmland areas you get to see the tractors rolling by. The longest I’d ever cycled before was the Springwater Corridor in Portland, the segment of which I did was only about 10 miles.
*Non sequitur.* ICFP submission deadline is today! Functional programmers around the world have reported a sharp increase in draft paper sightings.
March 23, 2011Ghost in the state machine
A long time ago (circa 2007-2008), I wrote perhaps the single most complicated piece of code in HTML Purifier—one of those real monsters that you don’t think anyone else could ever understand and that you are really grateful you have a comprehensive test suite for. The idea was this: I had a state machine that modified a stream of tokens (since this was a stream of HTML tags and text, the state machine maintained information such as the current nesting stack), and I wanted to allow users to add extra functionality on top of this stream processor (the very first processor inserted paragraph tags when double-newlines were encountered) in a modular way.
The simplest thing I could have done was abstract out the basic state machine, created a separate processor for every transformation I wanted to make, and run them one pass after another. But for whatever reason, this idea never occurred to me, and I didn’t want to take the performance hit of having to iterate over the list of tokens multiple times (premature optimization, much?) Instead, I decided to add hooks for various points in the original state machine, which plugins could hook into to do their own stream transformations.
Even before I had more than one “injector”, as they are called, I had decided that I would have to do something sensible when one injector created a token that another injector could process. Suppose you ran injector A, and then injector B. Any tokens that injector A created would be picked up by injector B, but not vice versa. This seemed to me a completely arbitrary decision: could I make it so that order didn’t matter? The way I implemented this was have the managing state machine figure out what new tokens any given injector had created, and then pass them to all the other injectors (being careful not to pass the token back to the originating injector.) Getting this right was tricky; I originally stored the ranges of “already seen” tokens separately from the token stream itself, but as other injectors made changes it was extremely easy for these ranges to get out of sync, so I ended up storing the information in the token themselves. Another difficulty is preventing A from creating a token which B converts into another token which A converts to B etc; so this skip information would have to be preserved over tokens. (It seems possible that this excluded some possible beneficial interactions between two injectors, but I decided termination was more important.)
Extra features also increased complexity. One particular feature needed the ability to rewind back to an earlier part of the stream and reprocess all of those tokens; since most other injectors wouldn’t be expecting to go back in time, I decided that it would be simplest if other injectors were all suspended if a rewind occurred. I doubt there are any sort of formal semantics for what the system as a whole is supposed to do, but it seems to work in practice. After all, complexity isn’t created in one day: it evolves over time.
There are several endings to this story. One ending was that I was amused and delighted to see that the problem of clients making changes, which then are recursively propagated to other clients, which can make other changes, is a fairly common occurrence in distributed systems. If you compress this into algorithmic form, you get (gasp) research papers like Lerner, Grove and Chamber’s Composing Dataflow Analyses and Transformations, which I discovered when brushing against Hoopl (note: I am not belittling their work: dataflow analysis for programming languages is a lot more complicated than hierarchy analysis for HTML, and they allow for a change made by A to affect a change B makes that can affect A again: they cut the knot by ensuring that their analysis eventually terminates by bounding the information lattice—probably something to talk about in another post).
Another ending is that, fascinatingly enough, this complex system actually was the basis for the first external contribution to HTML Purifier. This contributor had the following to say about the system: “I have to say, I’m impressed with the design I see in HTML Purifier; this has been pretty easy to jump into and understand, once I got pointed to the right spot.” The evolution of systems with complex internal state is, apparently, quite well understood by practicing programmers, and I see experienced developers tackling this subsystem, usually with success. From an experience standpoint, I don’t find this too surprising—years after I originally wrote the code, it doesn’t take me too long to recall what was going on. But I do wonder if this is just the byproduct of many long hacking sessions on systems with lots of state.
The final ending is a what-if, the “What if the older Edward came back and decided to rewrite the system.” It seems strange, but I probably wouldn’t have the patience to do it over again. Or I might have recognized the impending complexity and avoided it. But probably the thing that has driven me the most crazy over the years, and which is a technical problem in its own right, is despite the stream-based representation, everything HTML Purifier processes is loaded up in memory, and we don’t take advantage of streams of token at all. Annoying!
March 21, 2011I recently attended a talk which discussed extending proof assistants with diagrammatic reasoning support , helping to break the hegemony of symbolic systems that is predominant in this field. While the work is certainly novel in some respects, I can’t also but help think that we’ve come back full circle to the Ancient Greeks, who were big fans of geometry, and its correspondingly visual form of reasoning. The thought came up again while I was reading a mathematics text and marveling at the multiple methods of presenting a single concept. In this essay, I’d like to look at this return to older, more “intuitive” forms of reasoning: I’ve called it “Hellenistic reasoning” because geometry and the Socratic method nicely sum up visual and interactive reasoning that I’d like to discuss. I argue that this resurgence is a good thing, and that though these forms of reasoning may not be as powerful or general as symbolic reasoning, they will be critical to the application and communication of abstract mathematical results.
Symbolic reasoning involves syntactic manipulation of abstract symbols on a page; as Knuth puts it, it’s the sort of thing we do when we have a symbol that “appears in both the upper and the lower position, and we wish to have it appear in one place rather than two”. It’s a rather unnatural and mechanical mode of reasoning that most people have to be trained to do, but it is certainly one of the most popular and effective modes of reasoning. While I suspect that the deep insights that lead to new mathematical discoveries lie outside this realm, symbolic reasoning derives its power from being a common language which can be used as a communication channel to share these insights. Unlike natural language, it’s compact, precise and easy to write.
While symbols are an imperfect but serviceable basis for communication among the mathematically inclined, they strike fear and terror in the hearts of everyone else. A conference room of mathematicians will sigh in relief when the slide of axioms and equations shows up; a conference room of systems researchers will zone out when the same slide rolls around. Is this a sign to just give up and start using UML? My answer should be obvious: No! The benefits of a precise formalism are too great to give up. (What are those benefits? Unfortunately, that’s out of the scope of this particular essay.) Can we toss out the symbols but not the formalism? Maybe…
First on the list is visual reasoning. If you can find one for your problem, they can be quite elegant. Unfortunately, the key word is if: proofs with visual equivalents are the exception, not the rule. But there are some encouraging theorems and other efforts that can show a class of statements can be “drawn as pictures on paper.” Here are some examples:
- Theorem. Let $\mathcal{H}$ be the algebra of all open subsets (for the non-topologically inclined, you can think of this as sets minus their “edges”: the interior (Int) of all subsets) of the set $\mathbb{R}$ or $\mathbb{R}^2$ (or any Cartesian product of the above). Then $\mathcal{H} \vdash p$ if and only if $p$ is intuitionistically valid. What this means is that it is always possible to give a counterexample for an invalid formula over the real line or Euclidean plane. One example is Peirce’s law $((p \rightarrow q) \rightarrow p) \rightarrow p$: the counter-example on the real line is as such: let the valuation of p be $\mathbb{R} - \lbrace 0\rbrace$ and the valuation of q be $\emptyset$. The recipe is to repeatedly apply our rules for combining these subsets, and the see if the result covers all of the real line (if it doesn’t, it’s not intuitionistically valid). The rule for $A \rightarrow B$ is $\mathrm{Int}(-A \cup B)$, so we find that $p \rightarrow q$ is $\emptyset$ and $(p \rightarrow q) \rightarrow q$ is $\mathbb{R}$, and the full expression is $\mathbb{R} - \lbrace 0\rbrace$, just one point shy of the full number line.
- von Neumann famously remarked: “I do not believe absolutely in Hilbert space no more.” He was referring to the growing pains of the Hilbert Space formalism for quantum mechanics. If you’ve ever played around with tensor products and quibts, you’ll know that it takes a lot of work to show even the simplest calculations. The quantum picturalism movement attempts to recast quantum computation in terms of a graphical language, with the goal of making simple theorems, well, simple. No word yet if they will actually be successful, but it’s a very interesting vein of investigation.
- Commutative diagrams in category theory make proving properties a cinch: one simply needs to understand what it is that is being proved and draw the appropriate diagram! One particularly elegant proof of the Church-Rosser theorem (confluence of the untyped lambda calculus) uses a diagram chase after addressing one small technical detail.
We proceed on to interactive reasoning. These are methods that involve dialogues and games: they find their roots in game theory, but have since then popped up in a variety of contexts.
- The act of creating a construction for a formula can be thought of as a dialogue between a prover (who claims to know how to produce the construction), and a skeptic (who claims the construction doesn’t exist.) We can bundle up all of the information content of a proof by specifying a “strategy” for the prover, but the little bit of specificity that a particular instance of the game can be exceedingly enlightening. They also highlight various “interesting” logical twists that may not necessarily be obvious from applying inference rules: ex falso sequitur quodlibet corresponds to tricking the skeptic into providing contradictory information and classical logic permits Catch-22 tricks (see section 6.5 of Lectures on the Curry-Howard Isomorphism).
- Game semantics gives meaning to program execution in terms of games. Some interesting results include increased expressiveness over the more traditional denotational semantics (game semantics is able to “see” if a function requests the value of one of its argument), but in my opinion this is perhaps the most natural way to talk about laziness: when a thunk is forced I am asking someone for an answer; if I never force the thunk then this conversation never happens.
- In a much more mundane sense, traditional debuggers are a interactive reasoning system: the programmer converses with the program, asks questions and gets answers.
(It is that last sense that makes wonder if interactional reasoning is something that could become very widely used among software engineers: if you want to reason about the correctness of a system as a whole using a game, you still need to prove facts about strategies in general, but in an adversarial context (for example, compiler error) it could be very simple and useful. This is idle speculation: interactive error systems have been built before, e.g. LaTeX, and unfortunately, they’re not very good. One wonders why.)
I could end this essay with an admonition to “draw pictures and describe interactions”, but that would be very silly, since people do that already. What I would like to suggest is that there is rich theory that formalizes these two very informal activities, and this formalism is a good thing, because it makes our tools more precise, and thereby more effective.