May 27, 2011Another common thunk leak arises from mapping functions over containers, which do not execute their combining function strictly. The usual fix is to instead use a strict version of the function, ala foldl' or insertWith', or perhaps using a completely strict version of the structure. In today’s post, we’ll look at this situation more closely. In particular, the questions I want to answer are as follows:
- Why do we need to create strict and lazy versions of these functions—why can’t these leaks be fixed by the user adding appropriate bang-patterns to some functions?
- Though introducing a stricter API is usually the correct fix, in some circumstances, the problem is not that the API is insufficiently strict, but that the data structure is too insufficiently lazy (that is, inappropriately spine strict.) That is to say, what do I mean by an insufficiently lazy map?
- For data structures in which spine-strictness is necessary, is there any reason that this strictness should not extend to the values themselves? I want to argue that in fact, all spine strict data structures should also be value strict. This may be a bit controversial.
Our example is a very simple data structure, the spine-strict linked list:
data SpineStrictList a = Nil | Cons a !(SpineStrictList a)
ssFromList [] l = l
ssFromList (x:xs) l = ssFromList xs (Cons x l)
ssMap _ Nil l = l
ssMap f (Cons x xs) l = ssMap f xs (Cons (f x) l)
main = do
let l = ssFromList ([1..1000000] :: [Int]) Nil
f x = ssMap permute x Nil
evaluate (f (f (f (f (f (f (f (f l))))))))
permute y = y * 2 + 1
We first create an instance of the data structure using the ssFromList, and then we perform a map over all of its elements using ssMap. We assume the structure of the list is not semantically important (after all, the distribution of trees in an opaque data structure is of no interest to the user, except maybe for performance reasons. In fact, ssFromList and ssMap reverse the structure whenever they’re called, in order to avoid stack overflows.) The space leak here exemplifies the classic “non-strict container function” problem, where a call to a function like map looks harmless but actually blows up.

If you look at the implementation, this is not too surprising, based on a cursory look at SpineStrictList: of course it will accumulate thunks since it is not strict in the values, only the structure itself. Let’s look at some of the fixes.
Bang-pattern permute. This fix is tempting, especially if you were thinking of our last example:
permute !y = y * 2 + 1
But it’s wrong. Why is it wrong? For one thing, we haven’t actually changed the semantics of this function: it’s already strict in y! The resulting seq is too deeply embedded in the expression; we need permute y to be invoked earlier, not y. Also, remember that fixing our combining function last time only worked because we managed to enable a GHC optimization which unboxed the tuples, avoiding allocating them at all. However, that won’t work here, because we have a strict data structure which GHC doesn’t know if it can get rid of, so all of the allocation will always happen.
Rnf the structure on every iteration. This works, but is pretty inelegant and inefficient. Essentially, you end up traversing every time, for ultimately quadratic runtime, just to make sure that everything is evaluated. rnf is a pretty heavy hammer, and it’s generally a good idea to avoid using it.
Use a strict version of ssMap. This is a pretty ordinary response that anyone who has every changed a function from foo to the foo' version has learned to try:
ssMap' _ Nil l = l
ssMap' f (Cons x xs) l = ssMap' f xs ((Cons $! f x) l)

The remaining space usage is merely the strict data structure sitting in memory. In order to make this fix, that we had to go in and fiddle with the internal representation of our SpineStrictList in order to induce this strictness. Here is the answer to question one: we can’t fix this space leak by modifying the combining function, because the extra strictness we require needs to be “attached” (using a seq) to the outer constructor of the data structure itself: something you can only access if you’re able to manipulate the internal structure of the data structure.
One upshot of this is that it’s quite annoying when your favorite container library fails to provide a strict version of a function you need. In fact, historically this has been a problem with the containers package, though I’ve recently submitted a proposal to help fix this.
Make the structure value strict. This is a “nicer” way of turning ssMap into its strict version, since the bang patterns will do all the seq work for you:
data StrictList a = Nil | Cons !a !(SpineStrictList a)
Of course, if you actually want a spine strict but value lazy list, this isn’t the best of worlds. However, in terms of flexibility, a fully strict data structure actually is a bit more flexible. This is because you can always simulate the value lazy version by adding an extra indirection:
data Lazy a = Lazy a
type SpineStrictList a = StrictList (Lazy a)
Now the constructor Lazy gets forced, but not necessarily its insides. You can’t pull off this trick with a lazy data structure, since you need cooperation from all of the functions to get the inside of the container evaluated at all. There is one downside to this approach, however, which is that the extra wrapper does have a cost in terms of memory and pointer indirections.
Make the structure lazy. Fascinatingly enough, if we add laziness the space leak goes away:
data SpineStrictList a = Nil | Cons a (SpineStrictList a)
instance NFData a => NFData (SpineStrictList a) where
rnf Nil = ()
rnf (Cons x xs) = rnf x `seq` rnf xs
main = do
let l = ssFromListL ([1..1000000] :: [Int])
f x = ssMapL permute x
evaluate (rnf (f (f (f (f (f (f (f (f l)))))))))
ssFromListL [] = Nil
ssFromListL (x:xs) = Cons x (ssFromListL xs)
ssMapL _ Nil = Nil
ssMapL f (Cons x xs) = Cons (f x) (ssMapL f xs)
We’ve added an rnf to make sure that everything does, in fact, get evaluated. In fact, the space usage dramatically improves!

What happened? The trick is that because the data structure was lazy, we didn’t actually bother creating 1000000 thunks at once; instead, we only had thunks representing the head and the tail of the list at any given time. Two is much smaller than a million, and the memory usage is correspondingly smaller. Furthermore, because rnf doesn’t need to hold on to elements of the list after it has evaluated them, we manage to GC them immediately afterwards.
Fusion. If you remove our list-like data constructor wrapper and use the built-in list data type, you will discover that GHC is able to fuse-away all of the maps into one, extremely fast, unboxed operation:
main = do
let l = [1..1000000] :: [Int]
f x = map permute x
evaluate (rnf (f (f (f (f (f (f (f (f l)))))))))

This is not completely fair: we could have managed the same trick with our strict code; however, we cannot use simple foldr/build fusion, which does not work for foldl (recursion with an accumulating parameter.) Nor can we convert our functions to foldr without risking stack overflows on large inputs (though this may be acceptable in tree-like data structures which can impose a logarithmic bound on the size of their spine.) It’s also not clear to me if fusion derives any benefit from spine strictness, though it definitely can do better in the presence of value strictness.
In this post, we discussed how to fix the common accumulation of thunks inside spine-strict data structures. What we found was that if the structure was lazy in its structure, the rampant accumulation of thunks is avoided since not all of the leafs have thunks applied to them, and we found that if the structure was strict in its values, the thunks could also be avoided. We also discovered that, for a spine-strict value-lazy structure, the library itself must provide value-strict versions of all of their functions: these functions cannot be easily implemented by the user.
The conclusion I draw from all of these facts is that the spine-strict, value-lazy data structure is a very specialized beast that should only be used in very rare situations. It can be perhaps used to implement a memotable or dynamic programming, but in the event of updates and other “modification” functions, such a structure will almost never do what an ordinary user expects it to do. It should be noted that this does not mean that laziness is the problem: as we saw, many modifications to structures can be streamed, resulting in much better space usage. This is a point we will return to when we discuss streaming leaks. However, it is unclear if we can profitably convert existing spine-strict data structures into spine-lazy ones without paying large indirection costs. That is a topic of ongoing research.
May 25, 2011Yesterday we had guest speaker Byron Cook come in to give a talk about SLAM, a nice real-world example of theorem proving technology being applied to device drivers.
Having worked in the trenches, Byron had some very hilarious (and interesting) quips about device driver development. After all, when a device driver crashes, it’s not the device driver writer that gets blamed: it’s Microsoft. He pointed out that, in a hardware company, “If you’re not so smart, you get assigned to write software drivers. The smart people go work on hardware”, and that when you’re reading device driver code, “If there are a lot of comments and they’re misspelled, there’s probably a bug.” Zing! We’re always used to extolling the benefits of commenting your code, but it certainly is indisputable that writing comments can help clarify confusing code to yourself, whereas if the code wasn’t confusing in the first place you wouldn’t have felt the need to write comments anyway. Thus, one situation is some guru from the days of yore wrote very clever code, and then you came along and weren’t quite clever enough to fully understand what was going on, so you wrote lots of comments to explain the code to yourself as you went along. Well, it’s not the comment’s fault, but the fact that the code was too clever for you probably means you introduced a bug when you made your modifications.
The approach used by SLAM to deal with the exponential state space explosion was also pretty interesting. What they do is throw out as much state as possible (without eliminating the bug), and then see whether or this simplified program triggers a bug. It usually does, though due to a spurious transition, so then they introduce just enough extra state to remove that spurious path, and repeat until the simplified program is judged to fulfill the assert (success) or we come across a path in the simplified program which is not spurious in the real program. The other really interesting bit was their choice of specification language was essentially glorified asserts. In an academic class like Temporal Logic, you spend most of your time studying logics like CTL and LTL, which are strange and foreign to device driver writers; asserts are much easier to get people started with. I could definitely see this applying to other areas of formal verification as well (assert based type annotations, anyone?)
Postscript. I have some absolutely gargantuan posts coming down the pipeline, but in between revising for exams and last minute review sessions, I haven’t been able to convince myself that finishing up these posts prior to exams is a good use of my time. But they will come eventually! Soon! I hope!
May 23, 2011Recursion is one of those things that functional programming languages shine at—but it seems a bit disappointing that in many cases, you have to convert your beautiful recursive function back into iterative form. After all, iteration is what imperative languages do best, right?
Actually, explicitly tail-recursive functions in functional programming languages can be fairly beautiful: in fact, in the cases of complicated loops, they can be even prettier than their imperative counterparts. Take this midpoint line-drawing algorithm as an example:
circleMidpoint d r = go 0 (-r) k0
where k0 = 5 - 4 * r
x1 = ceiling (fromIntegral r / sqrt 2)
go x y k | x > x1 = return ()
| k > 0 = d (x,y) >> go (x+1) (y+1) (k+8*x+8*y+20)
| otherwise = d (x,y) >> go (x+1) y (k+8*x+12)
There are three loop variables: x, y and k, and depending on various conditions, some of them get updated in different ways. x is a bog-standard loop variable; ye old C-style for loop could handle it just fine. But y and k are updated differently depending on some loop conditions. But since they’re parameters to the go helper function, it’s always clear what the frequently changing variables are. You lose that nice structure in the imperative translation:
// global variables and loop variables are all mixed together
int k = 5 - 4 * r;
int y = -r;
int x1 = ceil(r/sqrt(2));
for (int x = 0; x <= x1; x++) { // only x is obviously an index var
draw(x, y);
if (k > 0) {
y++;
k += 8*x + 8*y + 20;
} else {
k += 8*x + 12;
}
// does it ever make sense for any code to live here?
}
I’ve also managed to introduce a bug in the process…
May 20, 2011This is an addendum to my second example in Anatomy of a thunk leak, in which I’d like to propose another solution to the space leak, involving computing the composition of all of these thunks. This solution is particularly notable because it preserves the denotation of the original function, that is, that f l (undefined, undefined) = (undefined, undefined). This should be surprising, because I claimed that it would be impossible for GHC to optimize a function with that had this denotation into one without the space leak by more eagerly evaluating some thunks. There is no contradiction: the optimization we would like to apply here is one of partial evaluation. Didn’t understand that? Don’t worry, a concrete example is coming soon.
As Heinrich Apfelmus points out, the space leak can be visualized as a large graph of expressions which has not been collapsed into a single value: 1 + (1 + (1 + (1 + (1 + (1 + ...))))). We can visualize this graph being built up in successive iterations of the function:
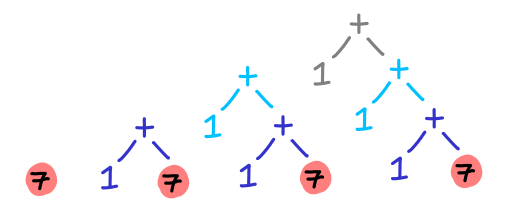
The point of introducing strictness (and thus changing the denotation of the function) is that we keep collapsing (evaluating) the tree.

But notice the value highlighted in red: we must know what this value is before we can do any computation. But if this value is unknown (or, in our case, if we don’t want to evaluate it while we are forming this graph), our strategy doesn’t really work. We can’t collapse the entire tree. However, (and this is the key), because addition is associative, we can rotate the tree, and then evaluate the (now left) subtree.
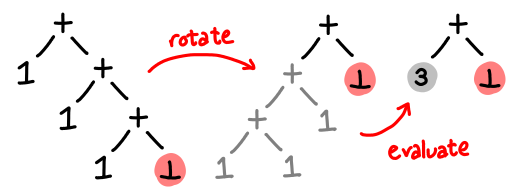
In effect, all of the thunks have been merged together: instead of 1 + 1 + 1 + X. we now have 3 + X. Simple! Here is the implementation:
f l (x0, x1) = go l (0, 0)
where go [] (!c0, !c1) = (c0 + x0, c1 + x1)
go (x:xs) !c = go xs (tick x c)
tick x (!c0, !c1) | even x = (c0, c1 + 1)
| otherwise = (c0 + 1, c1)
go is essentially the strict version of f, but at the end of the iteration it returns a pair with two thunks: c0 + x0 and c1 + x1, were both c0 and c1 have been fully evaluated.
Here’s another way of thinking of how we’re doing things:
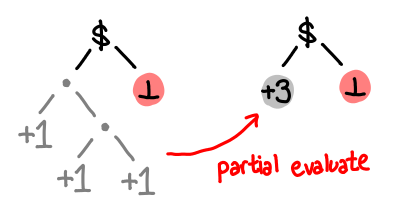
It would be pretty cool if this could be done automatically, and it would pretty applicable in other domains too. Combining functions that are associative are a precious commodity when it comes to parallelization.
May 18, 2011In this post, we discuss the characteristics of a thunk leak, the leak that has come to symbolize the difficulties of “reasoning about space usage” in Haskell. I’ll consider a few examples of this type of leak and argue that these leaks are actually trivial to fix. Rather, the difficulty is when a thunk leak gets confused with other types of leaks (which we will cover in later posts).
I’ll be describing the various leaks in two ways: I will first give an informal, concrete description using the metaphor I developed in the Haskell Heap series, and then I will give a more direct, clinical treatment at the end. If you can’t stand one form of explanation or the other, feel free to skip around.
Thunk leaks occur when too many wrapped presents (thunks) are lying around at the same time.
The creation of thunks is not necessarily a bad thing: indeed, most Haskell programs generate lots of thunks. Sometimes the presence of thunks on the heap is unavoidable. The problem is when they do not get evaluated in due course: like socks in the room of a lazy college student, they start piling up.
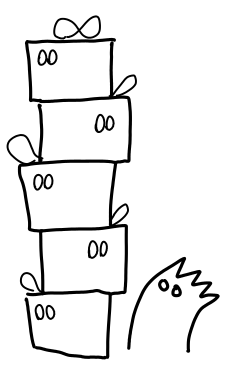
There is a precise sense by which the thunks “pile” up, which can be observed by looking at the presents the ghosts care about.
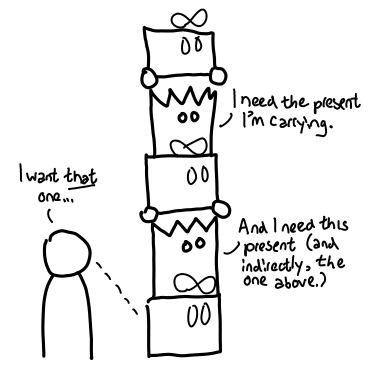
Each ghost cares about the next present in the pile (so the Grinch can’t steal them away), and we (the user) care about the present at the very bottom of the pile. Thus, when we open that present, the whole chain of presents comes toppling down (assuming there are not other references pointed to the pile).
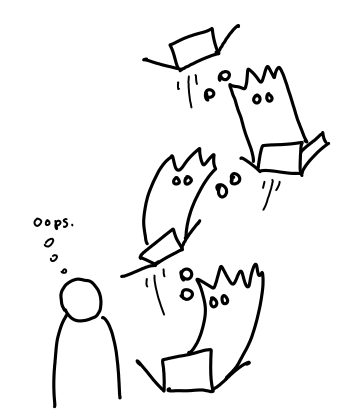
The chain of thunks could really be any shape you want, though linear is the usual case.
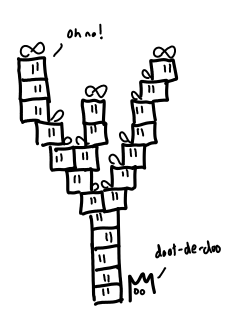
What would fixing the problem look like? It’s certainly not waiting until the presents get piled up and then cleaning them up in one go (as our college student might do): the damage (big memory usage) has already been done!
Rather, we should be a bit more eager and open up our presents as we get them.
This strategy can fail, however. If opening the presents results in something even bigger than we started off with or if we might not need to open all the presents, we might be better off just being lazy about it.

There’s also the question of where all these presents came from in the first place. Maybe we were too eager about getting the presents in the first place…

In summary, a thunk leak is when a Haskell program builds up a large number of thunks that, if evaluated, would result in much smaller memory usage. This requires such thunks to have several properties:
- They must not have external references to them (since the idea is as the thunks are evaluated, their results can get garbage collected),
- They must perform some sort of reduction, rather than create a bigger data structure, and
- They should be necessary.
If (1) fails, it is much more probable that these thunks are legitimate and only incur a small overhead (and the real difficulty is an algorithmic one). If (2) fails, evaluating all of the thunks can exacerbate the memory situation. And if (3) fails, you might be looking at a failure of streaming, since thunks are being eagerly created but lazily evaluated (they should be lazily created as well).
As with most space leaks, they usually only get investigated when someone notices that memory usage is unusually high. However, thunk leaks also tend to result in stack overflows when these thunk chains get reduced (though not always: a thunk chain could be tail recursive.) As with all performance tuning, you should only tune while you are doing measurements: otherwise, you may spend a lot of time optimizing something that is relatively insignificant (or worse yet, that GHC already optimized for you!)
The next line of diagnosis is the heap residency profile, which does not require you to recompile your program with profiling enabled. Just add -hT as an RTS flag. In the case of thunk leak, the heap profile is very tell-tale: a large chunk of the heap will be occupied with THUNK. Bingo!
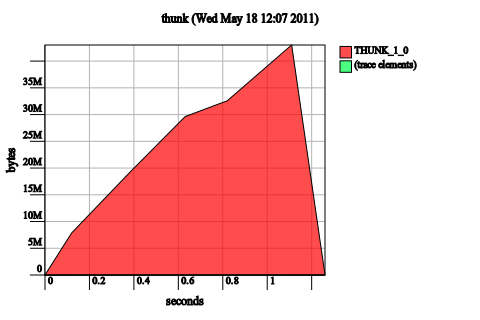
Note. This diagnostic step is why I’ve chosen to distinguish between thunk leaks and live variable leaks. A thunk leak will have thunks dominating the heap because the thunks themselves are numerous and are consuming memory. A live variable leak may be caused by a thunk retaining extra memory, but the thunks themselves may not necessarily show up on the heap, because you only need one reachable thunk to cause memory to be retained.
I’ve distilled some examples in order to help illustrate the phenomenon in question, as well as give direct, source-level indications on all the possible ways you can go about fixing the leak. I’ll also give some examples of things that could have leaked, but didn’t because GHC was sufficiently clever (hooray for optimizations!) Runnable code can be found in the GitHub repository, which I will try to keep up-to-date.
We’ll first start with the classic space leak from naive iterative code:
main = evaluate (f [1..4000000] (0 :: Int))
f [] c = c
f (x:xs) c = f xs (c + 1)
It should be obvious who is accumulating the thunks: it’s c + 1. What is less obvious, is that this code does not leak when you compile GHC with optimizations. Why is this the case? A quick look at the Core will tell us why:
Main.$wf =
\ (w_s1OX :: [GHC.Integer.Type.Integer])
(ww_s1P0 :: GHC.Prim.Int#) ->
case w_s1OX of _ {
[] -> ww_s1P0;
: _ xs_a1MR -> Main.$wf xs_a1MR (GHC.Prim.+# ww_s1P0 1)
}
Notice that the type of c (renamed to ww_s1P0) is GHC.Prim.Int#, rather than Int. As this is a primitive type, it is unlifted: it is impossible to create thunks of this type. So GHC manages to avoid thunks by not creating them at all in the first place. Fixing the unoptimized case is as simple as making c strict, since addition of integers is a strict function.
It is not, in general, possible for GHC to do this kind of unboxing optimization without violating the semantics of our code. Our next piece of code looks at precisely such a case:
main = do
evaluate (f [1..4000000] (0 :: Int, 1 :: Int))
f [] c = c
f (x:xs) c = f xs (tick x c)
tick x (c0, c1) | even x = (c0, c1 + 1)
| otherwise = (c0 + 1, c1)
This space leaks both with and without optimizations. It also stack overflows.
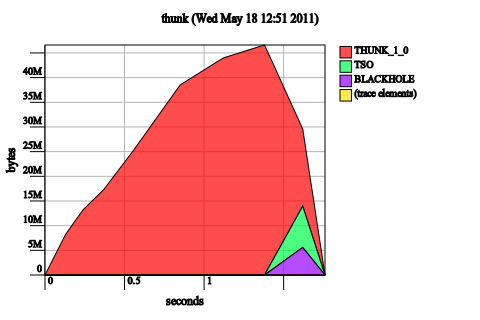
It is not possible for GHC to optimize this code in such a way that the elements of the pair are eagerly evaluated without changing the semantics of the function f. Why is this the case? We consider an alternate call to f: f [1..4000000] (0, undefined). The current semantics of the function demand that the result be (2000000, undefined) (since anything added to undefined is undefined), which means we cannot do any evaluation until the inside of the resulting tuple is forced. If we only ever evaluate the tuple to whnf (as the call to evaluate does) or if we only ever use the first result, then no exception should be thrown. This is indeed the case if we replace 1 :: Int with undefined and run the program.
OK, that’s enough theory, how do we fix this bug? I could just give you a single answer, but I think it will be more informative if we consider a range of possible fixes and analyze their effect on the program. Hopefully, this will make space leaks less like casting the runes, and much more methodical.
Add a bang-pattern to c in f. This doesn’t work:
f [] !c = c
f (x:xs) !c = f xs (tick x c)
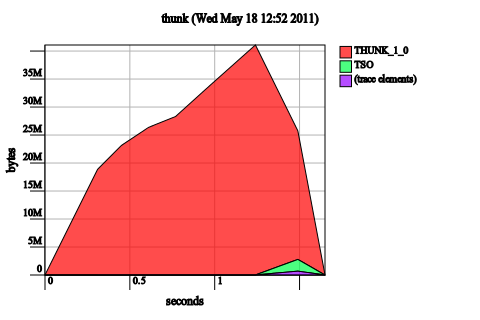
The insight is that we’ve not changed the semantics of the function at all: f l (undefined, undefined) still should result in (undefined, undefined), since seq doesn’t “look inside the tuple”. However, adding this bang-pattern may help in the construction of other solutions, if evaluating the tuple itself has other side-effects (as we might say, that ghost might open some presents for us).
Make the tuple in tick irrefutable. This is just confused:
tick x ~(c0, c1) | even x = (c0, c1 + 1)
| otherwise = (c0 + 1, c1)
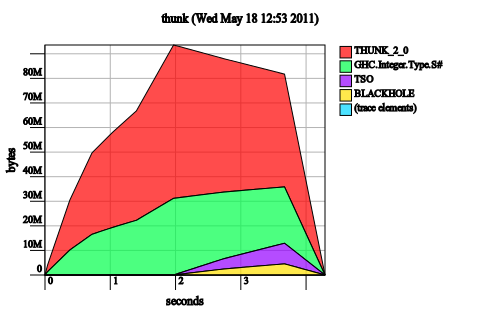
Irrefutable patterns add laziness, not strictness, so it’s not surprising that the problem has gotten worse (note the memory usage is now up to 80M, rather than 40M).
Make tick strict. Notice that the x is already forced immediately by even x, so there’s no need to add a bang pattern there. So we just add bang patterns to c0 and c1:
tick x (!c0, !c1) | even x = (c0, c1 + 1)
| otherwise = (c0 + 1, c1)
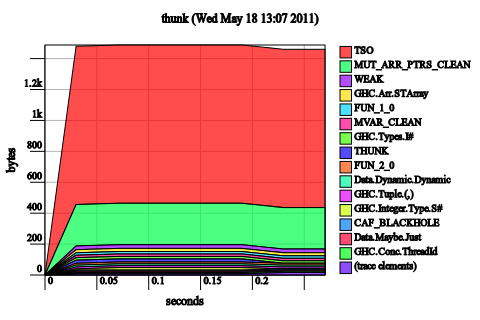
These might look like a terrible graph, but look at the scale. 1.2 kilobytes. In general, if after you make a change to a Haskell program and you start seeing lots of bands again, it means you’ve fixed the leak. So we’ve fixed it!
Well, not quite. The unoptimized code still has a leak:
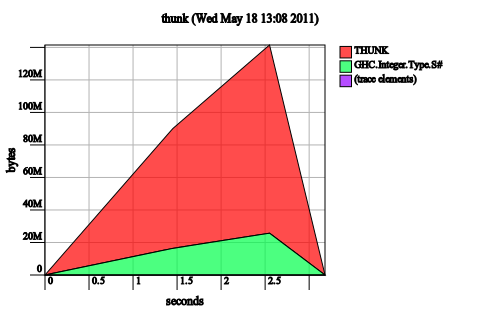
We fixed our space leak by enabling a GHC optimization, similar to the one that fixed our original space leak. Once again, the Core makes this clear:
Main.$wf :: [GHC.Integer.Type.Integer]
-> GHC.Types.Int
-> GHC.Types.Int
-> (# GHC.Types.Int, GHC.Types.Int #)
GHC has optimized the tuple away into an unboxed return and inlined the call to tick, as a result we don’t have any tuple thunks floating around. We could have manually performed this optimization, but it’s better to the let the compiler do it for us (and keep our code clean.)
Strictify tick and f. In analogy with the first example, now that tick is strict, if we strictify both places, the unoptimized code will also be fine. And indeed, it is.
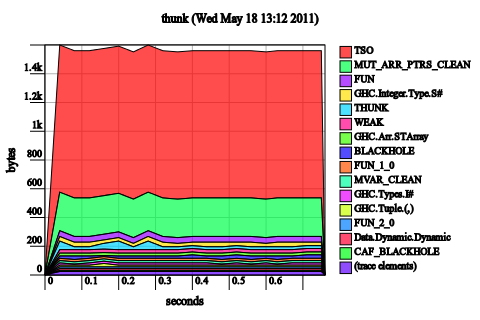
It doesn’t help us much for the optimized case though! (There is essentially no change to the heap profile.)
Make the pair strict. Using a strict pair instead of the default lazy pair is equivalent to inserting bang patterns every where we pattern match on a tuple. It is thus equivalent to strictifying tick, and if you do this you will still need a little extra to get it working in the unoptimized case. This tends to work better when you control the data structure that is going into the loop, since you don’t need to change all of your data declarations.
Deep seq c. If a simple bang pattern for c doesn’t work, a deep bang pattern will:
f [] c = c
f (x:xs) c@(!_,!_) = f xs (tick x c)
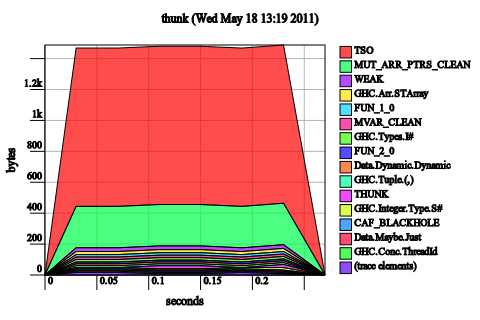
Alternatively, you could have used rnf from the deep seq package. While this does work, I personally think that it’s better policy to just use a strict data type, if you’re going to be rnf’ing willy-nilly, you might as well keep things fully evaluated all the time.
I had another example, but I’m out of time for today! As some parting words, note that tuples aren’t the only lifted types floating around: everything from records to single data constructors (data I a = I a) to mutable references have these extra semantics which can have extra space costs. But identifying and fixing this particular problem is really easy: the heap profile is distinctive, the fix is easy and non-invasive, and you even have denotational semantics to aid your analysis of the code! All you need is a little extra knowledge.
Postscript. Apologies for the wildly varying graph axes and shifty colors. Try to focus on the shape and labeling. I’m still wrangling hp2pretty to get it to generate the right kinds of heap profiles, and I need a more consistent scaling mechanism and more consistent coloring. Experiments were done on GHC 6.12.3.
May 16, 2011A big thanks to everyone who everyone who sent in space leak specimens. All of the leaks have been inspected and cataloged by our experts, and we are quite pleased to open the doors of the space leak zoo to the public!
There are a few different types of space leak here, but they are quite different and a visitor would do well not to confuse them (the methods for handling them if encountered in the wild vary, and using the wrong technique could exacerbate the situation).
- A memory leak is when a program is unable to release memory back to the operating system. It’s a rare beast, since it has been mostly eliminated by modern garbage collection. We won’t see any examples of it in this series, though it is strictly possible for Haskell programs to exhibit this type of leak if they use non-bracketed low-level FFI allocation functions.
- A strong reference leak is when a program keeps around a reference to memory that in principle could be used but actually will never be used anymore. A confluence of purity and laziness make these types of leaks uncommon in idiomatic Haskell programs. Purity sidesteps these leaks by discouraging the use of mutable references, which can leak memory if they are not cleared when appropriate. Laziness sidesteps these leaks by making it difficult to accidentally generate too much of a data structure when you only want parts of it: we just use less memory to begin with. Of course, using mutable references or strictness in Haskell can reintroduce these errors (sometimes you can fix instances of the former with weak references—thus the name, “strong reference” leak), and live variable leaks (described below) are a type of strong reference leak that catch people unfamiliar with closures by surprise.
- A thunk leak is when a program builds up a lot of unevaluated thunks in memory which intrinsically take up a lot of space. It can be observed when a heap profile shows a large number of
THUNK objects, or when you stack overflow from evaluating a chain of these thunks. These leaks thrive on lazy evaluation, and as such are relatively rare in the imperative world. You can fix them by introducing appropriate strictness. - A live variable leak is when some closure (either a thunk or a lambda) contains a reference to memory that a programmer expects to have been freed already. They arise because references to memory in thunks and functions tend to be implicit (via live variables) as opposed to explicit (as is the case for a data record.) In instances where the result of the function is substantially smaller, these leaks can be fixed by introducing strictness. However, these are not as easy to fix as thunk leaks, as you must ensure all of the references are dropped. Furthermore, the presence of a large chunk of evaluated memory may not necessarily indicate a live variable leak; rather, it may mean that streaming has failed. See below.
- A streaming leak is when a program should only need a small amount of the input to produce a small amount of output, thus using only a small amount of memory, but it doesn’t. Instead, large amounts of the input are forced and kept in memory. These leaks thrive on laziness and intermediate data structures, but, unlike the case of thunk leaks, introducing strictness can exacerbate the situation. You can fix them by duplicating work and carefully tracking data dependencies.
- A stack overflow is when a program builds up a lot of pending operations that need to performed after the current execution. It can be observed when your program runs out of stack space. It is, strictly speaking, not a space leak, but an improper fix to a thunk leak or a streaming leak can convert it into a stack overflow, so we include it here. (We also emphasize these are not the same as thunk leaks, although sometimes they look the same.) These leaks thrive on recursion. You can fix them by converting recursive code to iterative style, which can be tail-call optimized, or using a better data structure. Turning on optimization also tends to help.
- A selector leak is a sub-species of a thunk leak when a thunk that only uses a subset of a record, but because it hasn’t been evaluated it causes the entire record to be retained. These have mostly been killed off by the treatment of GHC’s selector thunks by the RTS, but they also occasionally show due to optimizations. (See below.)
- An optimization induced leak is a camouflaged version of any of the leaks here, where the source code claims there is no leak, but an optimization by the compiler introduces the space leak. These are very tricky to identify; we would not put these in a petting zoo! (You can fix them by posting a bug to GHC Trac.)
- A thread leak is when too many Haskell threads are lying around. You can identify this by a contingent of TSO on the heap profile: TSO stands for thread-state object. These are interesting to debug, because there are a variety of reasons why a thread may not dying.
In the next post, we’ll draw some pictures and give examples of each of these leaks. As an exercise, I invite interested readers to categorize the leaks we saw last time.
Update. I’ve separated thunk leaks from what I will now call “live variable leaks,” and re-clarified some other points, especially with respect to strong references. I’ll expand on what I think is the crucial conceptual difference between them in later posts.
May 13, 2011Short post, longer ones in progress.
One of the really neat things about the Par monad is how it explicitly reifies laziness, using a little structure called an IVar (also known in the literature as I-structures). An IVar is a little bit like an MVar, except that once you’ve put a value in one, you can never take it out again (and you’re not allowed to put another value in.) In fact, this precisely corresponds to lazy evaluation.

The key difference is that an IVar splits up the naming of a lazy variable (the creation of the IVar), and specification of whatever code will produce the result of the variable (the put operation on an IVar). Any get to an empty IVar will block, much the same way a second attempt to evaluate a thunk that is being evaluated will block (a process called blackholing), and will be fulfilled once the “lazy computation” completes (when the put occurs.)
It is interesting to note that this construction was adopted precisely because laziness was making it really, really hard to reason about parallelism. It also provides some guidance for languages who might want to provide laziness as a built-in construct (hint: implementing it as a memoized thunk might not be the best idea!)
May 11, 2011I’m currently collecting non-stack-overflow space leaks, in preparation for a future post in the Haskell Heap series. If you have any interesting space leaks, especially if they’re due to laziness, send them my way.
Here’s what I have so far (unverified: some of these may not leak or may be stack overflows. I’ll be curating them soon).
import Control.Concurrent.MVar
-- http://groups.google.com/group/fa.haskell/msg/e6d1d5862ecb319b
main1 = do file <- getContents
putStrLn $ show (length $ lines file) ++ " " ++
show (length $ words file) ++ " " ++
show (length file)
-- http://www.haskell.org/haskellwiki/Memory_leak
main2 = let xs = [1..1000000::Integer]
in print (sum xs * product xs)
-- http://hackage.haskell.org/trac/ghc/ticket/4334
leaky_lines :: String -> [String]
leaky_lines "" = []
leaky_lines s = let (l, s') = break (== '\n') s
in l : case s' of
[] -> []
(_:s'') -> leaky_lines s''
-- http://stackoverflow.com/questions/5552433/how-to-reason-about-space-complexity-in-haskell
data MyTree = MyNode [MyTree] | MyLeaf [Int]
makeTree :: Int -> MyTree
makeTree 0 = MyLeaf [0..99]
makeTree n = MyNode [ makeTree (n - 1)
, makeTree (n - 1) ]
count2 :: MyTree -> MyTree -> Int
count2 r (MyNode xs) = 1 + sum (map (count2 r) xs)
count2 r (MyLeaf xs) = length xs
-- http://stackoverflow.com/questions/2777686/how-do-i-write-a-constant-space-length-function-in-haskell
leaky_length xs = length' xs 0
where length' [] n = n
length' (x:xs) n = length' xs (n + 1)
-- http://stackoverflow.com/questions/3190098/space-leak-in-list-program
leaky_sequence [] = [[]]
leaky_sequence (xs:xss) = [ y:ys | y <- xs, ys <- leaky_sequence xss ]
-- http://hackage.haskell.org/trac/ghc/ticket/917
initlast :: (()->[a]) -> ([a], a)
initlast xs = (init (xs ()), last (xs ()))
main8 = print $ case initlast (\()->[0..1000000000]) of
(init, last) -> (length init, last)
-- http://hackage.haskell.org/trac/ghc/ticket/3944
waitQSem :: MVar (Int,[MVar ()]) -> IO ()
waitQSem sem = do
(avail,blocked) <- takeMVar sem
if avail > 0 then
putMVar sem (avail-1,[])
else do
b <- newEmptyMVar
putMVar sem (0, blocked++[b])
takeMVar b
-- http://hackage.haskell.org/trac/ghc/ticket/2607
data Tree a = Tree a [Tree a] deriving Show
data TreeEvent = Start String
| Stop
| Leaf String
deriving Show
main10 = print . snd . build $ Start "top" : cycle [Leaf "sub"]
type UnconsumedEvent = TreeEvent -- Alias for program documentation
build :: [TreeEvent] -> ([UnconsumedEvent], [Tree String])
build (Start str : es) =
let (es', subnodes) = build es
(spill, siblings) = build es'
in (spill, (Tree str subnodes : siblings))
build (Leaf str : es) =
let (spill, siblings) = build es
in (spill, Tree str [] : siblings)
build (Stop : es) = (es, [])
build [] = ([], [])
May 9, 2011Today, we discuss how presents on the Haskell Heap are named, whether by top-level bindings, let-bindings or arguments. We introduce the Expression-Present Equivalent Exchange, which highlights the fact that expressions are also thunks on the Haskell heap. Finally, we explain how this let-bindings inside functions can result in the creation of more presents, as opposed to constant applicative forms (CAFs) which exist on the Haskell Heap from the very beginning of execution.
When we’ve depicted presents on the Haskell Heap, they usually have names.
We’ve been a bit hush-hush about where these names come from, however. Partially, this is because the source of most of these names is straight-forward: they’re simply top-level bindings in a Haskell program:
y = 1
maxDiameter = 100
We also have names that come as bindings for arguments to a function. We’ve also discussed these when we talked about functions. You insert a label into the machine, and that label is how the ghost knows what the “real” location of x is:
f x = x + 3
pred = \x -> x == 2
So if I write f maxDiameter the ghost knows that wherever it sees x it should instead look for maxDiameter. But this explanation has some gaps in it. What if I write f (x + 2): what’s the label for x + 2?
One way to look at this is to rewrite this function in a different way: let z = x + 2 in f z, where z is a fresh variable: one that doesn’t show up anywhere else in the expression. So, as long as we understand what let does, we understand what the compact f (x + 2) does. I’ll call this the Expression-Present Equivalent Exchange.

But what does let do anyway?
Sometimes, exactly the same job as a top-level binding. These are Constant Applicative Forms (CAF).

So we just promote the variable to the global heap, give it some unique name and then it’s just like the original situation. We don’t even need to re-evaluate it on a subsequent call to the function. To reiterate, the key difference is free variables (see bottom of post for a glossary): a constant-applicative form has no free variables, whereas most let bindings we write have free variables.
Glossary. The definition of free variables is pretty useful, even if you’ve never studied the lambda calculus. The free variables of an expression are variables for which I don’t know the value of simply by looking at the expression. In the expression x + y, x and y are free variables. They’re called free variables because a lambda “captures” them: the x in \x -> x is not free, because it is defined by the lambda \x ->. Formally:
fv(x) = {x}
fv(e1 e2) = fv(e1) `union` fv(e2)
fv(\x -> e1) = fv(e1) - {x}
If we do have free variables, things are a little trickier. So here is an extended comic explaining what happens when you force a thunk that is a let binding.


Notice how the ghosts pass the free variables around. When a thunk is left unevaluated, the most important things to look at are its free variables, as those are the other thunks that will have been left unevaluated. It’s also worth repeating that functions always take labels of presents, never actual unopened presents themselves.
The rules are very simple, but the interactions can be complex!
Last time: How the Grinch stole the Haskell Heap
Technical notes. When writing strict mini-languages, a common trick when implementing let is to realize that it is actually syntax sugar for lambda application: let x = y in z is the same as (\x -> z) y. But this doesn’t work for lazy languages: what if y refers to x? In this case, we have a recursive let binding, and usually you need to use a special let-rec construction instead, which requires some mutation. But in a lazy language, it’s easy: making the binding will never evaluate the right-hand side of the equation, so I can set up each variable at my leisure. I also chose to do the presentation in the opposite way because I want people to always be thinking of names. CAFs don’t have names, but for all intents and purposes they’re global data that does get shared, and so naming it is useful if you’re trying to debug a CAF-related space leak.
Perhaps a more accurate translation for f (x + 2) is f (let y = x + 2 in y), but I thought that looked kind of strange. My apologies.

This work is licensed under a Creative Commons Attribution-ShareAlike 3.0 Unported License.
May 6, 2011One of the persistent myths about Aristotelean physics—the physics that was proposed by the Ancient Greeks and held up until Newton and Galileo came along—is that Aristotle thought that “heavier objects fall more quickly than light objects”, the canonical example being that of a cannon ball and feather. Although some fraction of contemporary human society may indeed believe this “fact,” Aristotle had a far more subtle and well-thought out view on the matter. If you don’t believe me, an English translation of his original text (Part 8) adequately gives off this impression. Here is a relevant quote (emphasis mine):
We see the same weight or body moving faster than another for two reasons, either because there is a difference in what it moves through, as between water, air, and earth, or because, other things being equal, the moving body differs from the other owing to excess of weight or of lightness.
The “other things being equal” is a critical four words that are left out even of Roman accounts of the theory. See for example Roman philosopher Lucretius:
For whenever bodies fall through water and thin air, they quicken their descents in proportion to their weights…
While I do not mean to imply the Aristotle was correct or at all near a Newtonian conception of physics, Aristotle was cognizant of the fact that the shape of the falling object could affect its descent (“For a moving thing cleaves the medium either by its shape”) and in fact, the context of these quotes is not a treatise on how bodies move, but about how bodies move through a medium: in particular, Aristotle is attempting to argue how bodies might move in “the void.” But somehow, this statement got misinterpreted into a myth that the majority of Westerners believed up until the advent of Galilean physics. Where did all of these essential details go?
My belief is that Aristotle lacked the crucial conceptual framework—Newtonian physics—to fit these disparate facts together. Instead, Aristotle believed in the teleological principal, that all bodies had natural places which they natural moved toward, which failed to have any explanatory power for many instances of physical experience. What generalizations he were able to make were riddled with special cases and the need for careful thought, that made the ideas difficult to be communicated without losing something in the process. This is not to say the careful thinking is not necessary: even when we teach physics today, it is extremely easy to make the same mistakes that our historic predecessors made: the facts of the matter may all “be in Newton’s laws”, but it’s not necessarily obvious that this is the case!
But as you learn about the applications of a theory, about the places where it easily can go wrong, it is critical to remember that these thoughts and intuitions are to be hung on the grander tree of the unifying and adequate theory. Those who do not are forever doomed to juggling a confusing panoply of special cases and disjoint facts and cursed with the inability to concisely express their ideas. And though I have not the space to argue it here, I also claim that this applies for every other sort of discipline for which you must accumulate knowledge.
tl;dr — Facts without structure are facts easily forgotten.