June 20, 2011Over the year, I’ve accumulated three notebooks worth of miscellaneous notes and musings. Since these notebooks are falling apart, I’ve decided to transfer their contents here. Warning: they might be slightly incoherent! This is the first of three notebooks. I recommend skimming the section headers and seeing if any of them pop out.
Tony Hoare wants to leverage “the hard work [that] is already solved” by placing the formalism of separation logic (e.g. Hoare triples) into an abstract algebra. The idea is that by encoding things in pairs, not triples, we can take advantage of the numerous results in algebra. The basic idea is we take a traditional triple {p} q {r} and convert it into a ordered semigroup relation p; q <= r, where ; is a monoidal operation. In the end we end up with a separation algebra, which is a monoidal lattice with an extra star operator. The choice of axioms is all: “This is abstract algebra, so you should be willing to take these axioms without having any model in mind.” (Scribbled here: “Inception as a metaphor for mathematical multi-level thinking.”) We have a homomorphism (not isomorphism) between implementations and specifications (the right direction is simplification, the left direction is a Galois connection.) In fact, as a commenter in the audience points out, this is known as the Stone Dualities—something like how two points determine a line—with contravariant points and properties. I believe Tony’s been thinking about this topic a bit since I went to this talk at the very beginning of this year, so its likely some or all of this has been superseded by later discoveries. C’est la vie!
Can we write parallel code that can execute on multiple types of hardware: e.g. vectorized operations on a traditional CPU, a GPU or an FPGA? He presents an EDSL that can be embedded in any language (well, for this particular representation, C#), with constructs like newFloatParallelArray, dx9Target.toArray1D(z) and overloaded operators. In my notes, I remark: can this representation be implemented taglessly, or do we always pay the cost of building a description of the system before we can execute it? Pushing software to hardware is especially important in the face of heterogenous processors (e.g. Metropolis). Satnam was a very engaging speaker, and many of the quotes here are attributed to him—though one quote I do have is “I hope this is not going to be quoted” (don’t worry, I haven’t quoted that sentence). Dancing is a metaphor for parallel processing (though I don’t remember what the metaphor was.) What about self-modifying hardware: we mmap the circuit description and let the hardware reprogram the FPGA!
Higher level information is crucial to optimization: thus we may want a symbolic evaluator with just in time compilation (except we can’t do that for FPGAs.) Memory access fusion is important: we want to get rid of accidental semicolons. Array -> Stream / Shift = Delay. Research idea: geometric encoding of common concurrency problems. Matrix inversion is a problem (so don’t invert the matrix, silly), local memory bounds GPU versus FPGA, and scheduling problem of energy.
Building “edit automata” with one very easy, simple idea: use strace to generate trees, and then perform regular expression on the system calls to look for viral behavior. It’s an approach similar in spirit to seLinux, which runs the program in order to determine an appropriate policy for it (and then notifies you when it does something outside of normal.) But I remark, the usefulness of an strace might not be so good in the face of poorly written Gnome applications (which touch every file and their mom); nor can you strace the kernel. What about a virus that notices when its being traced? It seems this strategy would need a lot of concrete pouring to become solid. Would an strace puppeteer be useful: that is, we get to fake responses to all syscalls a program makes? Might be kind of interesting, if hard to instrument.
Streambase is a company that implements a visual, event stream processing language. I interviewed with them to possibly work on their compiler; while I ended up turning them down, it was a very interesting interview and I think I would have had a lot of fun working for them (though working in Java, not so much!) The interview was very fun: one question was, “Explain monads to me.” Man, I still don’t know how to do that properly. (Side note: people really, really like side effects. The programming folklore around writing performant programs that work on persistent data is very new, perhaps I’d say even more so than the folklore around lazy evaluation).
One of the things Alexander Bird’s book Philosophy of Science taught me was how to identify unproductive skepticism, even when it is not obvious, in things such as Hume’s problem of induction. My essay on Reliabilism was quite good; it was the only essay I managed to get a first on in my philosophy supervisions during the year. Like type theory, justification is stratified, with layers upon layers.
Programmers in Hindley-Milner type systems have long enjoyed the benefits of practical type inference: we can generally expect the most general type to be inferred, and syntactic substitution of expressions in their use-sites will always typecheck. Of course, type inference algorithms are in general EXPTIME-complete, but type theorists can’t complain too much about that, since for more powerful logics inference is usually undecidable. (BTW: dictionaries constitute runtime evidence. Good way of thinking about it.) Curiously enough, in the presence of more advanced type features, writing type signatures can actually make the type checker’s job harder, but they add local equality assumptions that need to be handled by the constraint solver. Generalized let means that all of these constraints cannot be solved until we reach the call site. Can we work around this problem by doing on the fly solving of equality constraints? The French have a paper about this, but Peyton Jones recommends carrying along a jar of aspirins if you decide to read the paper. After his talk, one of the grad students remarked that Hindley-Milner is, in many ways, an anomaly: users of Agda have an expectation of needing to specify all type signatures, except in some special cases where they can eliminate them, whereas users of Haskell have an expectation of needing to specify no type signatures, except in special cases.
A long-standing problem with the Document Object Model is that it requires the entire document to be loaded up in memory. In cases like PHP’s documentation manual, the memory usage can be over a gigabyte large. Unfortunately, the mental model for manipulating a DOM is much more natural than that for manipulating a stream of XML tag events. Is there a way to automatically project changes to the DOM into changes on a stream? We’d like to construct an isomorphism between the two. I’m seeking a functional representation of the DOM, for manipulation (you’re still going to need mutability for a DOM-style event programming model.) “Clowns to the left of me, jokers to the right” emphasizes the difference between local and global analysis. One way you might look at traversal of a token stream is simply traversal, with a zipper to keep track of where you are. Of course, the zipper takes up memory (in effect, it forms something like a stack, which is exactly how you would convert a token stream into a tree.) So we can efficiently build the tree representation without mutation, but we still end up with a tree representation. At this point, I have written down, “Stop hitting yourself.” Indeed. Can we take advantage of domain specific knowledge, a claim that I promise not to go beyond this point? The idea of projecting DOM operations into XML stream operations, and using this as a sort of measurement for how costly something is may be profitable. Of course, now I should do a literature search.
Given a regular expression and a non-matching string, what is the minimum number of edits necessary to make the string match? There may be multiple answers, and the algorithm should allow you to weight different changes differently.
Apollo takes a hybrid approach to testing web applications, combining concrete and symbolic execution. The idea is that most web applications have diffuse, early conditionalization, with no complex state transformations or loops. So, we generate path constraints on the controller and solve them, and then generate inputs which let us exercise all of the control paths. Data is code: we want to describe the data. I must not have been paying very close attention to the presentation, because I have all sorts of other things scribbled in: “Stacks are the wrong debugging mechanism for STGs” (well, yes, because we want to know where we come from. Unfortunately, knowing where we are going isn’t very useful either) and “Can we automatically generate QuickCheck shrink implementations using execution traces?” (a sort of automated test-case minimization) and a final musing, “Haskell is not a good langauge for runtime inspection or fault localization.”
It would be very cool if someone made an interactive visualization of how type systems grow and are extended as you add new features to them, a sort of visual diff for typing rules and operational semantics.
As a blogger, my page view counts tend to be very spiky, corresponding to when my post hits a popular news site and gets picked up (to date, my Bitcoin post has had 22k views. Not bad!) But this doesn’t help me figure out long term trends for my website. Is there a way to smooth the trends so that spikes become simply “popular points” on a longer term trend?
I want a bible of minimal technical effort best practice user interfaces, patterns that are easy to implement and won’t confuse users too much. UI design is a bit too tweaky for my tastes. In the case of intelligent interfaces, how do we not piss off the user (e.g. Google Instant.) We have a user expectation where the computer will not guess what I want. That’s just strange.
In big letters I have: “Prove locality theorems. No action at a distance.” Almost precisely these same words Norman Ramsey would tell me while I was working with Hoopl. I think this is a pretty powerful idea.
I have some mathematical definitions written down, but they’re incomplete. I don’t think I wrote anything particularly insightful. This says something about the note-taking enterprise: you should record things that you would not be able to get later, but you should also make sure you follow up with all the complete information you said you’d look up later.
I have two pages of scribblings from solving problems over a telephone interview. I quite enjoyed them. One was a dynamic programming question (I moffed the recurrence at first but eventually got it), the second was implementing a functional programming feature in OCaml. Actually, I wanted to write a blog post about the latter, but it’s so far been consigned to my drafts bin, awaiting a day of resurrection. Later in my notes (page 74) I have recorded the on-site interview questions, unfortunately, I can’t share them with you.
“It’s like hiring an attorney to drive you across town.” I don’t remember what the context was, though.
I really enjoyed this talk. Mohan looks at applying NLP at a domain which is likely to be more tractable than the unrestricted human corpus: the domain of mathematical language. Why is it tractable? Math defines its lexicon in text (mathematical words must be explicitly defined), we mix symbols and natural language, and the grammar is restricted. Montague Grammars are in correspondence with Denotational Semantics. Of course, like normal language, mathematical language is heavily ambiguous. We have lexical ambiguity (“prime” can describe numbers, ideals, etc.), structural ambiguity (p is normal if p generates the splitting field of some polynomial over F_0—is F_0 referring to the generating or the polynomial?), symbolic ambiguity (d(x + y), and this is not just operator overloading because parse trees can change: take for example (A+B)=C versus λ+(M=N)), and combined symbolic and textual ambiguity. It turns out the linguistic type system of maths, which is necessary to get the correct parse trees, is not mathematical at all: integers, reals and friends are all lumped into one big category of numbers and types are not extensional (objects have different types depending on contents.) We need a dynamic type system, not a structural or nominal one, and we need to infer types while parsing.
From December 1st. I seem to need to write concluding paragraphs that are more concluding, and use shorter sentences. Summarize parts of my arguments, give more detail about experiments, and not to forget that a large part of historic mathematics was geometry. Aim for more in less sentences. Amen!
Another set of notes: all questions are traps: the examiner wants you to think about what is asked. Think about the broader context around events. You may not have enough time to compare with contemporary perspectives. Put guideposts in your essay. Be careful about non sequiturs. Colons are good: they add emphasis (but use them carefully.) Short sentences!
What a wonderful conference! There were a lot of talks and I should have taken more notes, but this is what I have, some quotes and sketches.
The algebraist versus the analyst. “Four riding in on a bicycle and then riding off again.” Numbers as moments, not an object (though it doesn’t lose generality.) “Cantor is hopeless at it.” (on zero.) “Do [numbers] start with 0 or 1? Yes and yes.” Frege and Russell finally give proper status to zero. The misreading of counting: does arithmetic start from counting? Number sequence is already in place, rather, we construct an isomorphism. There is a mistaken belief we count from one. Isomorphisms avoid counting, give proper status to zero, and sidestep the issue of how counting actually works (a transitive verb: pre-counting, we must decide what to count.) Contrary to popular depiction in Logicomix, Gödel and Russell did meet. Quine logic and Church logic. “It is not true that the square root of two is not irrational” requires every number be rational or irrational.
Why do we care about old people? How do we make progress in philosophy? Orders were syntactic rather than semantic: Kripke and Tarksi developed a hierarchy of truths. Free variable reasoning helped resolve nominala nd typical ambiguity: a scientific approach to a philosophical problem. “What nowadays constitutes research—namely, Googling it.” Nominal ambiguity: assert “x is even”, actually “forall x, x is even.” Quote: “It’s clear from the letter that he didn’t get past page five [of the Principia].” The word variable is deeply misleading, it’s not a variable name (progress!) “There are no undetermined men.” Anaphoric pronoun. We can’t express rules of inference this way.
Types: variables must have ranges. Hardly any theorems (all of the statements were schemas): we wanted to prove things about all types, but couldn’t on pain of contradiction. So all of the variables are type ically ambiguous. There is an argument in volume 2 respecting infinity, but a small world gives you the wrong mathematics (positivism.) But there was a bright idea:even if there aren’t enough things in the world, if there are k things, there are 2^k classes of things, etc. Go up the hierarchy. This is the interpretation for typical ambiguity. Whitehead thought theories were meaningless strings without types (a sort of macro in theory-land). ST made the language/metalanguage distinction!! “Seeing” is determining the type. The logocentric predicament is you’re supposed to use reasoning, but this reasoning is outside the formal system. Puns of operators on higher types, decorating all operators with a type label. The stratification of types.
Free variable reasoning is the same for typically ambiguous reasoning. Abbreviation for quantified reasoning (needs messy rules for inside quantifiers), indefinite names (can’t be the variable name, can’t lead to indefinite things), schematic names (lambdas: correct for variables, and modern for types.) But arguments that don’t convince someone unless they believe it (skepticism) sees: if the correct logic is type theoretic and oustide it, then we don’t have a position outside reasoning. (It’s a one way direction.) I think there is a way of talking about a system from within it. We have a weakened sense of truth: if you already believe it, it’s OK, but there is no convincing power.
The next lecture came from the computer scientist world. “Arguably, the more [programming languages] took from formal logic, the better it is.” Otherwise, it is the “ad-hoc craetion of electricians”. Computers allow easy formal manipulation and correctness checks. But for the mathematics? There isn’t very much of it. Proofs can be checked algorithmically (with formal inference rules). “Because there are many philosophers here, I hope I can answer questions in a suitably ambiguous manner.” Symbolism allows us to do “easy” things mechanically (Whitehead quote.) Do we need formal methods? In 1994 Pentium was found to have an error in floating point division. Robin’s conjecture was incorrectly proved. Different proof systems: de Bruijn generates proofs which are checked by a separate checker, LCF reduces all rules to primitive inferences checked by a logical kernel. After all, why don’t we prove that our proof assistants work? HOL Light (Principia) is only 430 lines of code. Schaffer’s joke: Ramseyfied Types. Right now, formal logic is on the edge of 20th century research mathematics, proofs needing “only 10k lines of code.” Maintenance of formal proofs is a big problem: we need intermediate declarative abstract models. Check out Flyspeck.
I had some scribblings in the margins: “references in logic?” (I think that’s linear logic), how about performance proofs (guaranteed to run in such-and-such time, realtime proofs), or probabilistically checkable proofs. Maybe complexity theory has something to say here.
Their method of efficient access is… a zipper. Oh man!
My scribblings here are largely illegible, but it seems a few concepts initially gave me trouble:
- Stack layout, keeping up and down straight, info tables, and the motion of the stack pointer. I have a pretty good idea how this all works now, but in the beginning it was quite mysterious.
CmmNode constructors have a lot of field, and constructing a correspondence with printed C– is nontrivial.- Sizes of variables.
- Headers, payloads and code.
- Pointer tagging, esp. with respect to values living in registers, on the stack, and what the tag bits mean depending on context (functions or data). I never did figure out how the compacting GC worked.
This concludes the first notebook.
June 17, 2011I recently encountered the following pattern while writing some Haskell code, and was surprised to find there was not really any support for it in the standard libraries. I don’t know what it’s called (neither did Simon Peyton-Jones, when I mentioned it to him), so if someone does know, please shout out. The pattern is this: many times an endomorphic map (the map function is a -> a) will not make very many changes to the underlying data structure. If we implement the map straight-forwardly, we will have to reconstruct the entire spine of the recursive data structure. However, if we use instead the function a -> Maybe a, we can reuse old pieces of the map if there were no changes to it. (Regular readers of my blog may recognize this situation from this post.) So what is such an alternative map (a -> Maybe a) -> f a -> Maybe (f a) called?
One guess it might be the traverse function in Data.Traversable: it certainly has a very similar type signature: Applicative f => (a -> f b) -> t a -> f (t b). However, the semantics are subtly different, as you can see from this example:
Data.Traversable> traverse (\x -> if x == 2 then Just 3 else Nothing) [1,2,3]
Nothing
Recall that our function only returns Nothing in the event of no change. Thus, we should have gotten the result Just [1,3,3]: the first and third elements of the list unchanged, and the second element of the list with its new value.
How would we implement such a function for lists? Here’s a simple implementation:
nonSharingMap :: (a -> Maybe a) -> [a] -> Maybe [a]
nonSharingMap f xs = let (b, r) = foldr g (False, []) (zip xs (map f xs))
in if b then Just r else Nothing
where g (y, Nothing) (b, ys) = (b, y:ys)
g (_, Just y) (_, ys) = (True, y:ys)
But we can do better than this. Consider a situation where all elements of the list except the head stay the same:
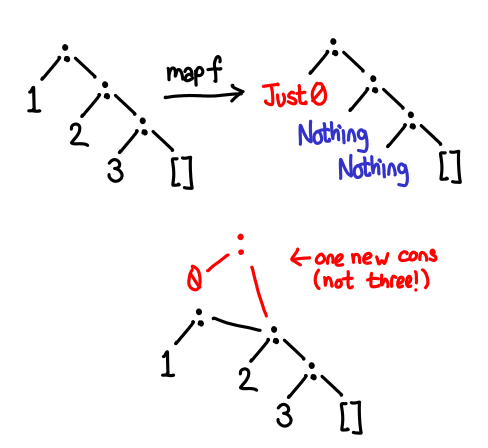
We would like to share the tail of the list between the old and new versions. With a little head-scratching, and the realization that tails shares, we can write this version:
sharingMap :: (a -> Maybe a) -> [a] -> Maybe [a]
sharingMap f xs = let (b, r) = foldr g (False, []) (zip3 (tails xs) xs (map f xs))
in if b then Just r else Nothing
where g (_, y, Nothing) (True, ys) = (True, y:ys)
g (_, _, Just y) (True, ys) = (True, y:ys)
g (ys', _, Nothing) (False, _) = (False, ys')
g (_, _, Just y) (False, ys) = (True, y:ys)
Open questions: what is this pattern called? Why doesn’t it follow the usual applicative structure? Does it fulfill some higher order pattern? Also, this scheme isn’t fully compositional: if I pass you a Nothing, you have no access to the original version in case there was a change elsewhere in the structure: (Bool, a) might be a little more compositional. Does this mean this is an example of the state monad? What about sharing?
Update. Anders Kaseorg writes in with a much more straight-forward, directly recursive version of the function:
sharingMap f [] = Nothing
sharingMap f (x : xs) = case (f x, sharingMap f xs) of
(Nothing, Nothing) -> Nothing
(y, ys) -> Just (fromMaybe x y : fromMaybe xs ys)
I haven’t checked, but one hope of expressing the function in terms of foldr and zip3 is that one may be able to get it to fuse. Of course, for actual recursive spine-strict data types, you usually won’t be able to fuse, and so a more straightforward presentation is more normal.
June 15, 2011I recently had to remove a number of type synonyms from the GHC code base which were along the lines of type CmmActuals = [CmmActual]. The process made me wonder a little about when type synonyms are appropriate for Haskell code. The Wikibooks article says type synonyms are “for making the roles of types clearer or providing an alias to, for instance, a complicated list or tuple type” and Learn You a Haskell says they “make more sense to someone reading our code and documentation.” But under what circumstances is this actually true?
Let’s try dividing the following use-cases of type synonyms:
- They can give extra semantic content, for example
DateString is more informative than String about its contents, though they are the same. - They can abbreviate long constructed types, for example
TcSigFun might abbreviate Name -> Maybe TcSigInfo.
The first is an example of code reader benefit: types with extra semantic information make it easier to see what a function is doing; the second is example of coder writer benefit: abbreviations of long types make writing type signatures more pleasurable. Sometimes a type synonym can give both benefits.
The downside of type signatures is their opacity of implementation. Seeing a value with type Address, I do not know if this is an algebraic data type or a type synonym, where as if it were a String I would know immediately what functions I could use on it. The type synonym adds an extra layer of indirection to figuring out how to manipulate the value: thus, it is a downside for the writer. It is true that algebraic data types and newtypes also add a layer of indirection, but they also bring to the table extra type safety that type synonyms don’t. (Furthermore, an algebraic data type is usually marvelously self documenting, as each of its constructors gets its own name).
I think my taste in the matter is as follows:
- Don’t use type synonyms if are not going to give any extra semantic information beyond the structure of the type.
- Synonyms for atomic types can be used freely, if the correspondence is unique. If you have many synonyms referring to the same atomic type, consider newtypes.
- Synonyms for non-function compound types should be used sparingly. They should not leak out of module boundaries, and are candidates for promotion into algebraic data-types.
- Synonyms for function compound types are mostly OK (since conversion into an ADT doesn’t buy you much, and they are unlikely to get mixed up), but make sure they are documented properly.
- Prefer to keep type synonyms inside module boundaries, un-exported. (Though, I know a few cases where I”ve broken this rule.)
How do you feel about type synonyms?
June 13, 2011There’s networking, and then there’s socialization. Networking is establishing the link, knowing how to find and talk to the person if the need arises. Socialization is communication for the sake of communication; it strengthens networks and keeps people in touch. In many ways, it is the utility a social networking site provides. Trouble is, there are so many different ways to communicate on the Internet these days. In this blog post, I try to explain the essential differences of socialization over the Internet. I believe what is called one-to-many socialization is the fundamental characteristic of the newest social patterns (facilitated by Facebook and Twitter), and describe some of the challenges in designing methods for consuming and aggregating this information.
There are a few obvious ways to slice up communication methods. Here are a few:
- Media. Most current applications are primarily text-based, but people have also tried audio, picture and video based modes with varying degrees of success.
- Length. How long is the average message in this medium?
- Persistence. If I ignore all activity older than an hour, how much do I miss? Are messages expected to be ephemeral or persistent? Is it even possible to send messages at all times?
- Distribution. Is it one-to-one, one-to-many or many-to-many communication? (For the purposes of this discussion, we’ll define on-to-many when there is an asymmetric flow of information: so a “comment” system does not turn a conversation into many-to-many… unless it manages to capture a conversation of its own.) When there are many listeners, how do we select who is listening?
- Consumption. How do we receive updates about communication?
We can look at a few existing networks and see how they answer these questions:
- Instant messaging (IM). Text, short length, persistent but not always available, one-to-one, consumed via a chat client. Note that with the existence of multi-protocol chat clients, it’s not too difficult to navigate the multitude or protocols employed by people all over the world.
- Internet Relay Chat (IRC) and Jabber. Text, short length, ephemeral, many-to-many, consumed via an IRC/Jabber client. There is some degree of integration between these protocols and instant messengers. Anyone can participate, but people can be kicked or banned from channels.
- Personal email. Text, medium length, persistent, one-to-one, consumed via a webmail interface or a mail client.
- Mailing lists. Text, medium length, persistent, many-to-many, consumed via webmail, mail client, or newsreader. For public mailing lists, anyone can participate.
- Forum. Text, medium length, persistent, many-to-many, consumed via web browser.
- Blog. HTML, medium to long length, persistent, one-to-many, consumed via web browser, possibly with an RSS reader. Anyone can subscribe to a public blog they are interested to.
- Twitter. Text, short length, ephemeral or persistent, one-to-many (though one-to-one communication is possible with at-replies, and in even more rare cases, many-to-many with multiple at-recipients), consumed via web browser or a Twitter client. Anyone can follow a public Twitter user.
- Facebook Wall. Text and images, short to medium length, ephemeral or persistent, one-to-many (but many-to-many with comments), consumed via web browser. Only friends can receive updates.
- Zephyr. (Sorry, had to sneak in an MIT example, since I use this protocol a lot.) Text, short to medium length, ephemeral or persistent, many-to-many (but with personal classes, which let people initiate conversations in a one-to-many fashion), consumed via zephyr client. Effectively limited to members of a university only.
- Social question websites. (e.g. Ask Reddit, Ask Hacker News, Stack Overflow.) Text, medium to long length, persistent, one-to-many (discussion itself can range from one-to-one to many-to-many), consumed via web browser. Updates are seen by subscribers of a given topic.
- Skype Voice/Video. Audio/video, short length, ephemeral, one-to-one, done via the Skype client.
There are a few interesting features about this current landscape that I can observe, once we have distilled these protocols down to these levels.
- Upstart companies attempting to create the next big social networks will frequently be innovating specifically in a few of these dimensions. Google Wave tried to innovate on medium, by introducing an extremely rich method of communication. Color is trying to innovate on medium and distribution.
- Communication protocols that lie within the same taxonomy (for example, IM clients) have seen a proliferation of clients that can interoperate before all of them. This has not, however, generally been the case for cross-taxonomy jumps: have you seen a single client which integrates participation with forums, email, Facebook and instant messaging? And if you have, did it work well at all? The method of consumption for one type of social information does not necessarily work well for other types.
- Similarly, it is not too difficult to bootstrap persistent communication protocols on other communication protocols. For example, a reply to a forum post is relatively persistent and not too much is lost if you send an email update whenever a new reply is found, and if you can’t rely on a user regularly checking your website for updates, this can be critical. However, sending instant messages to your email account makes no sense! There is something important here, which is that it does not make sense to mix ephemeral and persistent means of communication.
- Early social networking tools focused on one-to-one and many-to-many interactions, since these closely model how we socialize in real life. However, the advent of Twitter and Facebook has demonstrated that normal people can use a one-to-many medium not just for publishing (as was the case for blogs) but for socialization. People did not pin up sheets of gossip on noticeboards, they disseminated it via one-on-one conversations. But this is exactly what the new Internet is all about. The new social Internet involves exploring between the lines of publishing and private communication. Understanding what this variation is, is in many ways the key to understanding how to use the new social medium correctly.
As an end-user, I’m interested in mechanisms of unifying all social interaction methods which have the same consumption patterns—mostly because I don’t have a long enough attention span to deal with so many different website I have to check. And no, this does not mean just providing a tabbed interface which lets you switch from one network to another. Email and RSS work reasonably well for me for the persistent methods, but I have always found there to be a big void when it comes the new one-to-many styles of ephemeral (yet persistent) communication. Part of the reason is that we’re still trying to figure out what an optimal way of approaching this is, even when only one communication protocol is involved. (Remember that Facebook’s news feed was much loathed when it was originally released—but this was the key feature that moved Facebook from being a social networking site to a social communication site.) The situation becomes much more complex when multiple, subtly incompatible modes of communication are thrown into the mix.
Kyle Cordes writes about this topic from the perspective of a power user. I agree with him that it’s unclear whether or not there would actually be a market for such a unified social media client outside of power users. But it’s unclear to me if the open source community will step up to the bat and create such a client. I hope to be proven wrong.
June 10, 2011What is the biggest possible Haskell program that you could try debugging a space leak in? One very good choice is GHC, weighing in nearly a 100k lines of code (though, thankfully, 25% of that figure is comments.) Today, I’m going to describe one such space leak that I have fixed in GHC. This is not a full story: my code was ultimately the culprit, so not covered is how to debug code you did not write. However, I still like to think this story will cover some of the major points:
- How to setup a reproducible and manageable test-case for the leak,
- How to narrow down the source of the space leak,
- How to identify code is more prone to space leaking,
- How to determine what kind of leak it is,
- How to inspect libraries to determine if they are leaky, and
- How to test your fixes to see if they worked.
I really like this case because I had to do all of these things in order to pinpoint and ultimately fix this space leak. I hope you do too!
(Note: The diagrams are a bit big, because I generated them with hp2ps -c in order to make them look as close to what you might actually see in the field—as opposed to my hacked up copy of hp2pretty. Unfortunately, if I resized them, the text would be illegible. Suggestions welcome!)
I first noticed something amiss when my builds of GHC with the new code generator enabled at stage 1 and 2 started OOM’ing. I’d come back after letting the build run, and notice that the build had failed on Parser.hs due to an out of memory. (In retrospect, the fact that the failure was from Parser.hs—a half a megabyte ball of autogenerated source code—should have been a good clue.) The first time, I didn’t think much of it: I re-ran the command manually, and it seemed to work. Perhaps I had gotten unlucky and some background process in my machine had been gobbling lots of memory while ghc-stage1 was running.
Of course, it happened again the next time I did a full build, and at that point I thought something a little fishy might have been going on. Because my normal testing did not uncover this problem, and because I did not relish having to spend time fixing a mysterious bug (most bugs in GHC are quite tricky devils to fix), I let things go for a few weeks. What had I done to merit such memory usage? I had no clue. Certainly the -hT profile (which I could easily add, since it doesn’t require you to recompile the program with profiling) wasn’t giving me much: a lot of thunks and integer maps (which, in GHC, are accessed using a wrapper module called UFM, or unique finite maps).
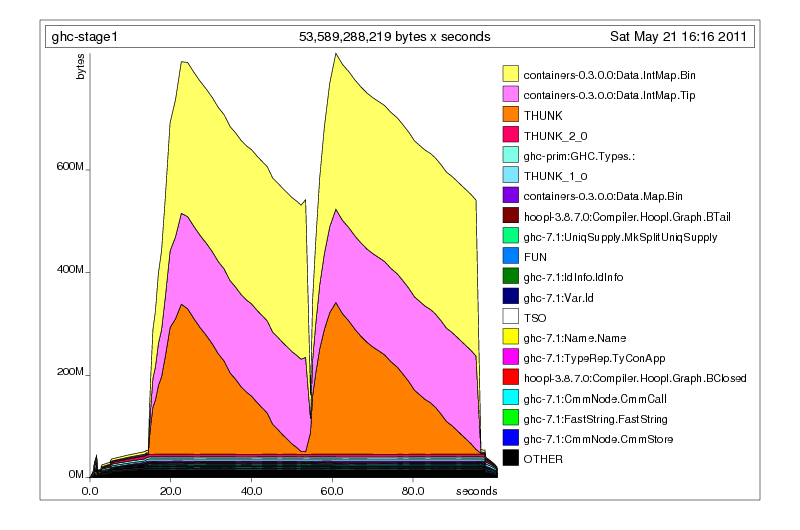
When I finally got around to attacking this bug seriously, the first thing I wanted to do was make a reduced test-case of Parser.hs, effectively the input file that was causing the out-of-memory. Why not test on Parser.hs directly?
- Big inputs result in lots of data, and if you don’t really know what you’re looking for lots of data is overwhelming and confusing. The answer might be really obvious, but if there is too much cruft you’ll miss it.
- This was a file that was OOM-ing a machine with 2GB of RAM. Space is time, and Haskell programs that use this much memory take correspondingly longer to run. If I was looking to make incremental changes and re-test (which was the hope), waiting half an hour between iterations is not appealing.
- It was a strategy that had worked for me in the past, and so it seemed like a good place to start collecting information.
Actually, I cheated: I was able to find another substantially smaller test file lying around in GHC’s test suite that matched the heap profile of GHC when run on Parser.hs, so I turned my attentions there.
In your case, you may not have a “smaller” test case lying around. In that case, you will need to reduce your test-case. Fortunately, inputs that are not source programs tend to be a lot easier to reduce!
- Binary search for a smaller size. Your null hypothesis should be that the space leak has been caused strictly more data, so if you delete half of your input data, the leak should still be present, just not as severe. Don’t bother with anything sophisticated if you can chop and re-test.
- Sometimes a space leak is caused by a specific type of input, in which case deleting one half of the input set may cause the leak to go away. In this case, the first thing you should test is the other half of the input set: the culprit data is probably there, and you can continue binary searching on that chunk of code. In the worst case scenario (removing either half causes the leak to go away), buckle down and start selectively removing lines that you believe are “low risk.” If you remove a single line of data and the leak goes away, you have some very good data about what may actually be happening algorithmically.
- In the case of input data that has dependencies (for example, source code module imports), attempt to eliminate the dependencies first by re-creating them with stub data.
In the best case situation, this process will only take a few minutes. In the worst case situation, this process may take an hour or so but will yield good insights about the nature of the problem. Indeed, after I had gotten my new test-case, I reduced it even further, until it was a nice compact size that I could include in a blog post:
main = print $ length [
([0,0,0],0),([0,0,0],0),([0,0,0],0),([0,0,0],0),([0,0,0],0),
([0,0,0],0),([0,0,0],0),([0,0,0],0),([0,0,0],0),([0,0,0],0),
([0,0,0],0),([0,0,0],0),([0,0,0],0),([0,0,0],0),([0,0,0],0),
([0,0,0],0),([0,0,0],0),([0,0,0],0),([0,0,0],0),([0,0,0],0),
([0,0,0],0),([0,0,0],0),([0,0,0],0),([0,0,0],0),([0,0,0],0),
([0,0,0],0),([0,0,0],0),([0,0,0],0),([0,0,0],0),([0,0,0],0),
([0,0,0],0),([0,0,0],0),([0,0,0],0),([0,0,0],0),([0,0,0],0),
([0,0,0],0),([0,0,0],0),([0,0,0],0),([0,0,0],0),([0,0,0],0),
([0,0,0],0),([0,0,0],0),([0,0,0],0),([0,0,0],0),([0,0,0],0),
([0,0,0],0),([0,0,0],0),([0,0,0],0),([0,0,0],0),([0,0,0],0),
([0,0,0],0),([0,0,0],0),([0,0,0],0),([0,0,0],0),([0,0,0],0),
([0,0,0],0),([0,0,0],0),([0,0,0],0),([0,0,0],0),([0,0,0],0),
([0,0,0],0),([0,0,0],0),([0,0,0],0),([0,0,0],0),([0,0,0],0),
([0,0,0],0),([0,0,0],0),([0,0,0],0),([0,0,0],0),([0,0,0],0),
([0,0,0],0),([0,0,0],0),([0,0,0],0),([0,0,0],0),([0,0,0],0),
([0,0,0],0),([0,0,0],0),([0,0,0],0),([0,0,0],0),([0,0,0],0),
([0,0,0],0),([0,0,0],0),([0,0,0],0),([0,0,0],0),([0,0,0],0)]
A plain heap profile of looks very similar to the bigger Parser case, and even if it’s a different space leak, it’s still worth fixing.
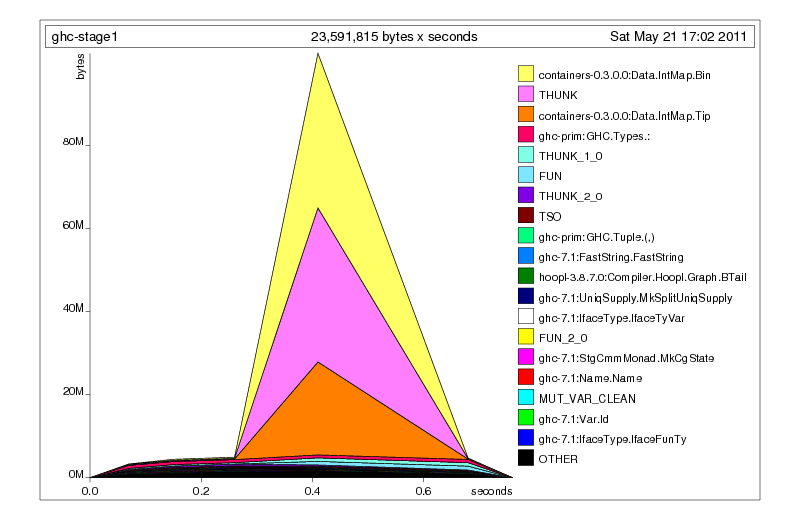
After you have your test case, the next step is to compile with profiling enabled. With GHC, this is as simple as switching your build settings to build a profiled stage 2 compiler; for a more ordinary Haskell project, all you need to do is add -prof -auto-all to your ghc invocation, or invoke Cabal with --enable-executable-profiling --enable-library-profiling --ghc-option=-auto-all. You may need to install profiling versions of your libraries, so a useful line to have in your .cabal/config file is library-profiling: True, which causes all libraries you cabal install or cabal configure to have profiling enabled. In fact, if you don’t have this setting on, turn it on right now. The extra time you spend when installing packages is well worth it when you actually want to profile something.
GHC has a large array of heap and time profiling options, but in general, the first two flags you want to try are -hc (for a traditional, cost-center based heap profile) and -prof (this gives a time profile—but we’ll see how this can be useful):
./ghc-stage2 -fforce-recomp -c Mu.hs +RTS -hc
./ghc-stage2 -fforce-recomp -c Mu.hs +RTS -prof
One quick remark: the program being tested here is ghc-stage2.hs (which is really big), not Mu.hs (which is really small.) I don’t actually care about what the output program is!
Here’s what the heap report tells us.
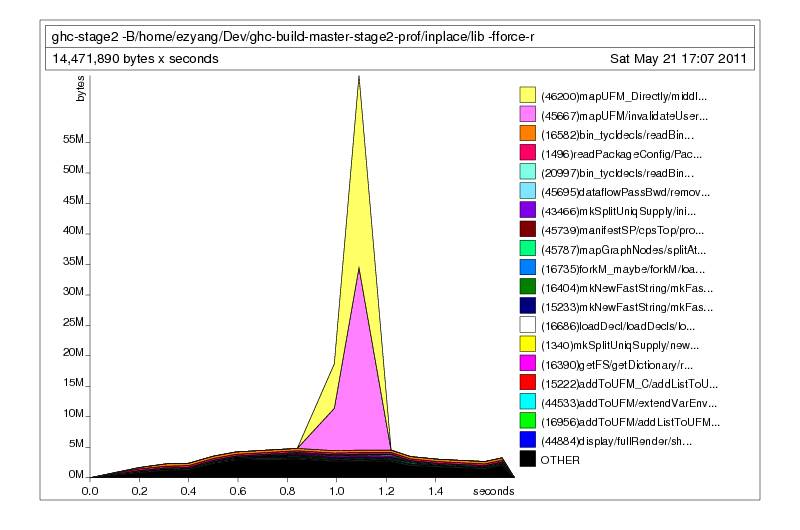
This is much better; rather than telling us what was on the heap, it tells us who put it on the heap. The main offenders seem to be mapUFM and mapUFM_Directly, which are utility functions mapping IntMap. But we also see that they are being called by two other functions. Their names have been truncated, but this is no problem: we can simply rerun the profiler with a longer cost center name using the -L flag:
./ghc-stage2 -fforce-recomp -c Mu.hs +RTS -hc -L50
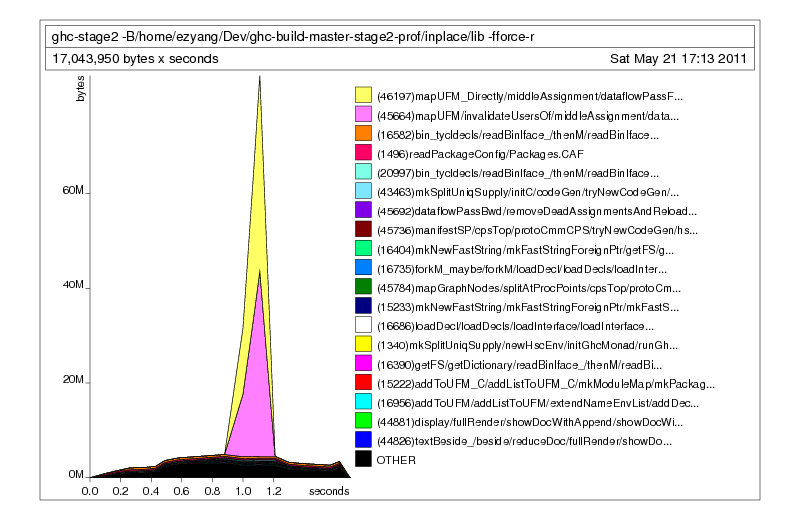
Much better! You could have also consulted the prof file to find the primary callees of the offending functions:
individual inherited
COST CENTRE MODULE no. entries %time %alloc %time %alloc
middleAssignment CmmSpillReload 45804 5324 0.0 0.0 15.7 33.8
callerSaves StgCmmUtils 46347 8 0.0 0.0 0.0 0.0
wrapRecExpf CmmNode 46346 8 0.0 0.0 0.0 0.0
xassign CmmSpillReload 46345 8 0.0 0.0 0.0 0.0
foldUFM_Directly UniqFM 46344 4 0.0 0.0 0.0 0.0
mapUFM_Directly UniqFM 46343 1633 9.0 17.3 9.0 17.3
deleteSinks CmmSpillReload 45811 3524 0.0 0.0 0.0 0.0
invalidateUsersOf CmmSpillReload 45809 1887 0.0 0.0 6.7 16.4
regUsedIn CmmExpr 45821 6123 1.1 0.0 1.1 0.0
xassign CmmSpillReload 45820 6123 0.0 0.0 0.0 0.0
mapUFM UniqFM 45810 1887 5.6 16.4 5.6 16.4
Wondrous. We pull open the definitions for mapUFM, mapUFM_Directly, middleAssignment and invalidateUsersOf, all four of which constitute suspicious functions in which the space leak may lurk.
Here I reproduce the relevant source code snippets. mapUFM and mapUFM_Directly are very thin wrappers around M, which is a qualified import for IntMap:
mapUFM f (UFM m) = UFM (M.map f m)
mapUFM_Directly f (UFM m) = UFM (M.mapWithKey (f . getUnique) m)
invalidateUsersOf is a relatively self-contained function:
-- Invalidates any expressions that use a register.
invalidateUsersOf :: CmmReg -> AssignmentMap -> AssignmentMap
invalidateUsersOf reg = mapUFM (invalidateUsers' reg)
where invalidateUsers' reg (xassign -> Just e) | reg `regUsedIn` e = NeverOptimize
invalidateUsers' _ old = old
middleAssignment is a bit trickier: it’s a very large function with many cases, but only one case has an invocation of mapUFM_Directly in it:
-- Algorithm for stores:
-- 1. Delete any sinking assignments that were used by this instruction
-- 2. Look for all assignments that load from memory locations that
-- were clobbered by this store and invalidate them.
middleAssignment (Plain n@(CmmStore lhs rhs)) assign
= mapUFM_Directly p . deleteSinks n $ assign
where p r (xassign -> Just x) | (lhs, rhs) `clobbers` (r, x) = NeverOptimize
p _ old = old
I would like to remark how small the amount of code we have to look at is. If they were much larger, one sensible thing to do would have been to instrument manually with more SCC pragmas, so that you can figure out what local definition to zoom in on. Once you have a small segment of code like this, one of the best ways to proceed is debugging by inspection: that is, stare at the code until the bug becomes obvious.
If you’ve ever fixed a space leak in Haskell before, or have been reading this blog regularly, there should be an obvious first guess: mapUFM is too lazy, and we are thus accumulating thunks. This is consistent with the presence of thunks in our initial heap profiles. A keen reader may have noticed that the thunks aren’t present in our hc profile, because thunks are not cost-centers. We can verify that they’re still hanging around, though, by running an hd profile:
./ghc-stage2 -fforce-recomp -c Mu.hs +RTS -hd
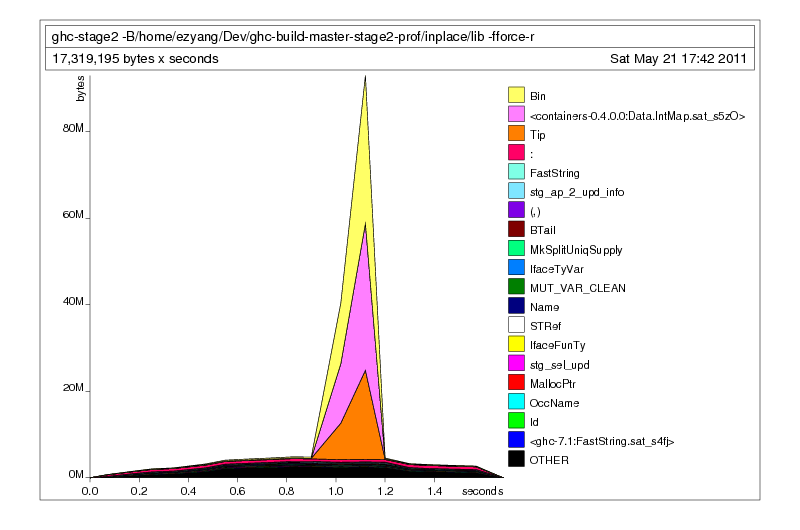
That sat_s5zO is the precise thunk from IntMap that is leaking. A quick look at the source code of IntMap confirms our suspicion:
data IntMap a = Nil
| Tip {-# UNPACK #-} !Key a
| Bin {-# UNPACK #-} !Prefix
{-# UNPACK #-} !Mask
!(IntMap a) !(IntMap a)
mapWithKey :: (Key -> a -> b) -> IntMap a -> IntMap b
mapWithKey f = go
where
go (Bin p m l r) = Bin p m (go l) (go r)
go (Tip k x) = Tip k (f k x)
go Nil = Nil
IntMap is spine-strict, but mapWithKey (which is invoked , lacking any bang-patterns, is clearly lazy in the update function f. Annoyingly enough, it seems that there is no strict version of the function either. Well, let’s quickly add a strict version of this function and test it out:
mapWithKey' f t
= case t of
Bin p m l r -> Bin p m (mapWithKey' f l) (mapWithKey' f r)
Tip k x -> let v = f k x in v `seq` Tip k v
Nil -> Nil
After a recompile, we see the following results with -hc:
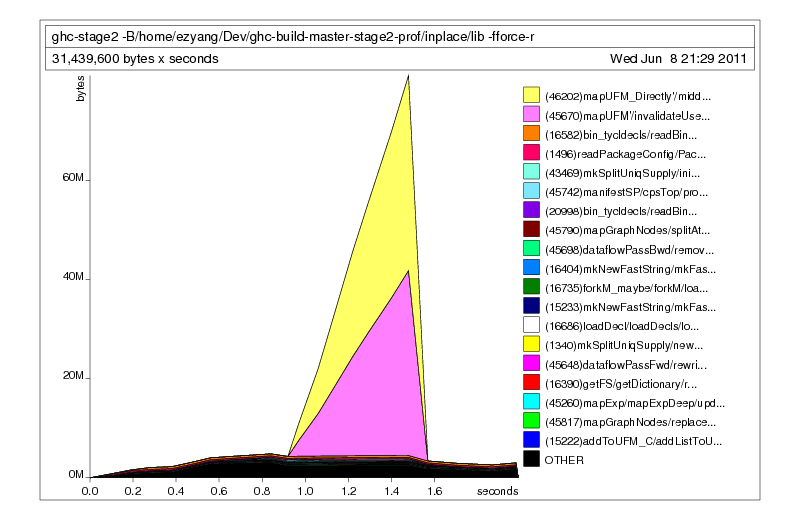
Uh oh! The memory usage improved slightly, but it still looks pretty bad. Did we do something wrong? Let’s find out what the objects on the heap actually look like with -hd:
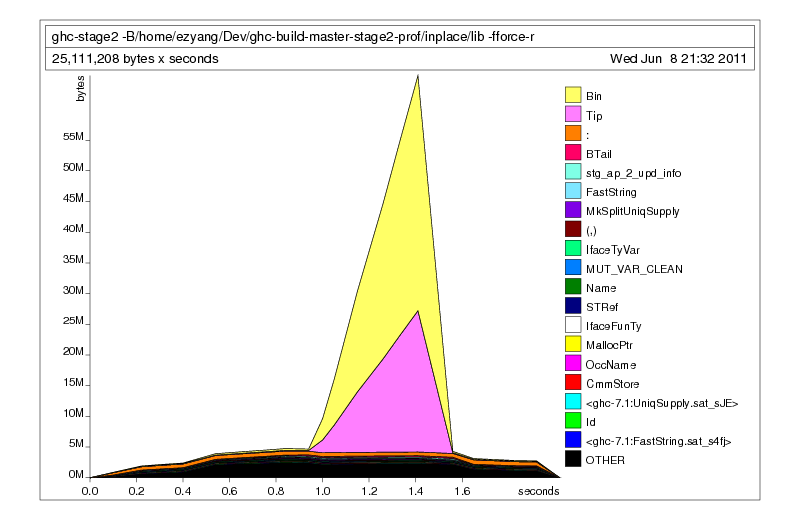
Notice that the thunks have disappeared from the profile! The fix was successful: we’ve eliminated the thunks. Unfortunately, none of the IntMap constructors Bin or Tip have gone away, and those are the true space leaks. So what’s holding on to them? We can use retainer profiling with -hr:
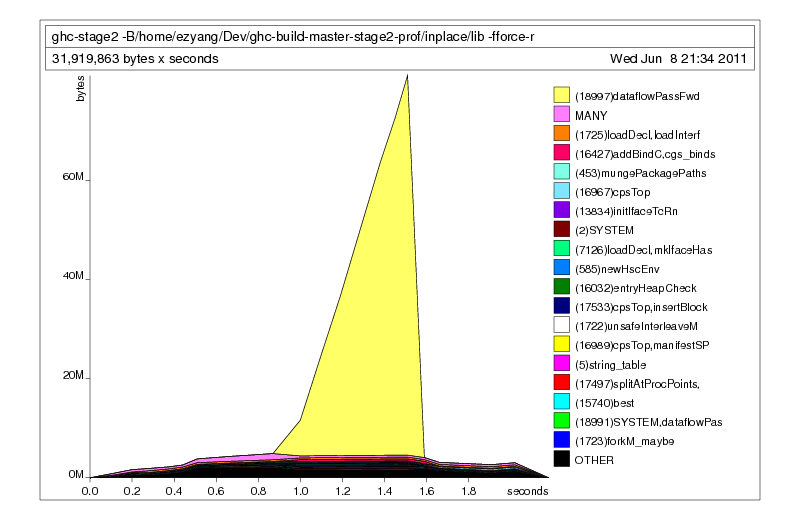
This is not a space leak. In fact, it may very well be a problem with the algorithm we are using. We discard our thunk leak hypothesis, and go back to the drawing board.
I will admit, when I got to this point of the debugging, I was pretty displeased. I thought I had pinned down the space leak, but swapping in a strict map hadn’t helped at all. Instead, all of the maps were being retained by the dataflow pass stage, and I knew I couldn’t eliminate those references, because that was how the algorithm worked. The dataflow analysis algorithm in GHC needs to retain the map it calculates for a given node, because the map is necessary for performing rewrites at every point of the graph, and may be reused in the event of a loop. It would take substantial cleverness to use the map in a non-persistent way.
But it seemed fairly unlikely that this code was strictly to blame, since we had used it with great success in many other parts of the code. Then I had an insight. The map in IntMap does not perform any sharing at all with the original structure: it needs to reconstruct all of the internal nodes. When the function being mapped over the structures preserves the original value of most of the map entries, this is quite wasteful. So perhaps a better strategy would be to pre-calculate which map entries changed, and only update those entries. If no inserts are made, the map gets completely shared; if one insert is made, the majority of the map continues to be shared (only the path is rewritten.) The rewritten functions then look as follows:
invalidateUsersOf reg m = foldUFM_Directly f m m
where f u (xassign -> Just e) m | reg `regUsedIn` e = addToUFM_Directly m u NeverOptimize
f _ _ m = m
middleAssignment (Plain n@(CmmStore lhs rhs)) assign
= let m = deleteSinks n assign
in foldUFM_Directly f m m
where f u (xassign -> Just x) m | (lhs, rhs) `clobbers` (u, x) = addToUFM_Directly m u NeverOptimize
f _ _ m = m
Guess what: it worked!
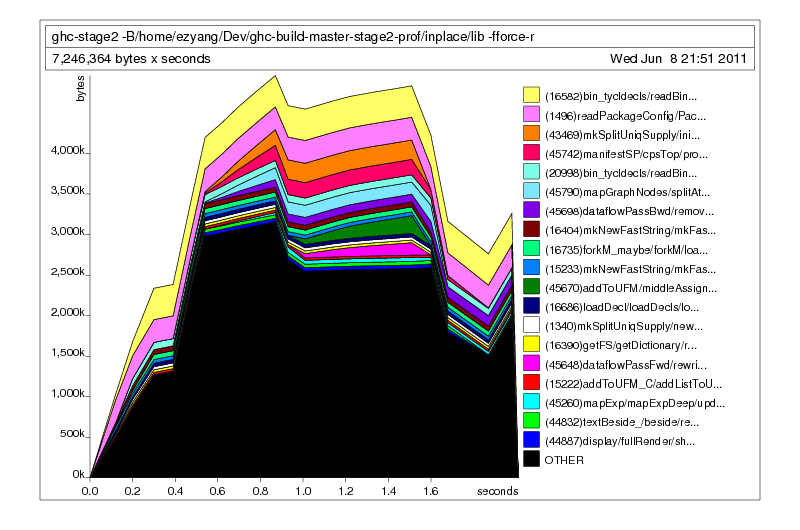
Optimistic, I spun up a new full compile, and most gratifyingly, it did not out-of memory. Victory!
The point of this post was not to show you how lack of sharing could cause the space usage of an algorithm to blow up—delving into this topic in more detail is a subject for another post. The point was to demonstrate how GHC’s profiling tools can really home in on the source of a leak and also let you know if your fixes worked or not. Ultimately, fixing space leaks is a lot like debugging: after you’ve checked the usual culprits, every situation tends to be different. (Of course, check the usual culprits first! They might work, unlike in this situation.)
In particular, I want to emphasize that just because one particular fix didn’t work, doesn’t mean that the leak isn’t still in the location indicated by profiling. The ultimate fix was still in the very same place as the profiling suggested, and checking the retainers also indicated the algorithm that was ultimately tickling a lack of sharing. Furthermore, once you have a reduced test-case that exhibits the leak, making small changes and seeing how the heap usage changing is extremely fast: even for a huge codebase like GHC, a small source level change only results in a ten second recompile, and getting fresh heap statistics only takes another five seconds. This is fast and allows you to experiment.
Now go forth, and slay space bugs in even the largest programs without fear!
June 8, 2011Today we continue the theme, “What can Philosophy of Science say for Software Engineering,” by looking at some topics taken from the Philosophy of Physical Sciences.
Quantification is an activity that is embedded in modern society. We live by numbers, whether they are temperature readings, velocity, points of IQ, college rankings, safety ratings, etc. Some of these are uncontroversial, others, very much so, and a software engineer must always be careful about numbers they deal in, for quantification is a very tricky business.
Philosophers of science can look to history for some insight into this conundrum, for it was not always the case that thermometry was an uncontroversial method of generating numbers. While the thermometer itself was invented in the 16th century, it took centuries to establish the modern standard of measuring temperature. What made this so hard? Early dabblers in thermometry were well aware of the ability to calibrate a thermometer by testing its result at various fixpoints (freezing and boiling), and graduating the thermometer accordingly, and for some period of times this was deemed adequate for calibrating thermometers.
But alas, the thermal expansion of liquids is not uniform across liquids, and what intrepid experimenters like Herman Boerhaave and Daniel Fahrenheit discovered was, in many cases, two thermometers would not agree with each other, even if they had been calibrated in the same way. How would they determine which thermometer was more accurate, without appealing to… another thermometer? Most justifications involving the nature of the liquid “particles” and their forces appealed to (at the time) unjustifiable theoretical principles.
Without the invention of modern thermodynamics, the most compelling case would be put forth Henri Victor Regnault. An outstanding experimentalist, Regnault set forth to solve this problem by systematically eliminating all theoretical assumptions from this work: specific heat, caloric, conservation of heat—all of these did not matter to him. What Regnault cared about was the comparability of thermometers: an instrument that gave varying values depending on the situation could not be trusted. If the thermometer was sensitive to the proportion of alcohol in it, or the way its glass had been blown, it was not to be taken as reflecting reality.
In the face of uncertainty and unsure theoretical basis, even simple criterion like comparability can be useful in getting a grip on the situation. One should not underestimate the power of this technique, due in part to its ability to operate without assuming any sort of theoretical knowledge of the task at hand.
The law of leaky abstractions states that all attempts to hide the low-level details of a system fail in some way or another. Taken to the extreme, it results in something resembling a reductive approach to the understanding of computer systems: in order to understand how some system works, it is both desirable and necessary to understand all of the layers below it.
Of course, we make fun of this sort of reductivism when we say things like, “Real men program with a magnet on their hard drive.” One simply cannot be expected to understand a modern piece of software merely by reading all of the assembly it is based on. Even systems that are written at a low level have implicit higher level structure that enables engineers to ignore irrelevant details (unless, of course, those irrelevant details are causing bugs.)
This situation is fascinating, because it is in many senses the opposite of the reductivism debate in science. For software, many aspects of the end behavior of a system can be deductively known from the very lowest level details—we simply know that this complexity is too much for a human. Science operates in the opposite direction: scientists seek simplifying, unifying principles as the delve deeper into more fundamental phenomena. Biology is applied chemistry, chemistry is applied physics, physics is applied quantum mechanics, etc. Most scientists hold the attitude of ontological reduction: anything we interact with can eventually be smashed up into elementary particles.
But even if this reduction is possible, it may not mean we can achieve such a reduction in our theories. Our theories at different levels may even contradict one another (so called Kuhnian incommensurability), and yet these theories approximate and effective. So is constantly pursuing a more fundamental explanation a worthwhile pursuit in science, or, as a software engineer might think, only necessary in the case of a leaky abstraction?
Postscript. My last exam is tomorrow, at which point we will return to our regularly scheduled GHC programming.
June 6, 2011I spent part of my year in Cambridge reading the History and Philosophy of Science course. It has been a thrilling and enlightening course, and I cannot recommend it highly enough for anyone lucky enough to take the HPS strand at Cambridge. Of course, I was a bit of an odd one out, since the course is designed for Natural Science majors, and I am, of course, a Computer Scientist.
In the next two posts, I’d like to highlight some of the major themes of the Philosophy of Science course, and how they may be applicable to software engineers. (Notably not computer scientists: it seems likely that their philosophy is one rooted in the Philosophy of Maths.) Not all of the questions are relevant: an old tripos question asks “Is there a unified philosophy of science, or disparate philosophies of the sciences?”—I would likely answer “both.” But I think the existing corpus of knowledge can give some insights to some tenacious questions facing us: What constitutes the cause of a bug? How does a software engineer debug? How do we know if a particular measurement or assessment of software is reliable? What reason do we have for extending our realm of experience with a software to areas for which we have no experience? Can all explanations about the high-level behavior of code be reduced to the abstractions behind them? I should be careful not to overstate my case: undoubtedly some of you may think some of these questions are not interesting at all, and others may think the arguments I draw in not insightful at all. I humbly ask for your patience—I am, after all, being examined on this topic tomorrow.
What does it mean when we say an event causes another? This is one of those questions that seem so far removed from practicality to be another one of those useless philosophical exercises. But the answer is not so simple. The philosopher David Hume observes that when we speak of causation, there is some necessary connection between the cause and effect: the bug made the program crash. But can we ever observe this “necessary connection” directly? Hume argues no: we only ever see a succession of one event to another; unlike the programmer, we cannot inspect the source code of the universe and actually see “Ah yes, there’s the binding of that cause to that effect.”
One simple model of causation is the regularity theory, inspired by a comment Hume makes in the Enquiry: a cause is “an object, followed by another, and where all the objects similar to the first are followed by objects similar to the second.” I observe that every event of “me pressing the button” is immediately followed by “the program crashing”, then I might reasonably infer that pressing the button is the cause of the crash. There is nothing unreasonable here, but now the philosopher sees the point of attack. There are many, many cases where such a simple regularity theory fails. Consider the following cases:
- I press the button, but the program only crashes some of the time. Even if the bug is not 100% reproduceable, I might still reasonably say it causes the crash.
- An alert dialog pops up, I press the button, and the program crashes. But it was not my pressing the button that caused the crash: rather, it’s more likely it was whatever caused the alert dialog to pop up. (You may have had an experience explaining this to a less computer-savvy family member.)
- I have only pressed the button once, and that one time the program crashed. It is indeed the case that whenever I pushed the button, a crash came afterwards: but it’s possible for me to press the button now and no crash to occur.
Perhaps no reasonably practiced software engineer uses this model of causation. Here is a more plausible model of causation, the counterfactual model (proposed by David Lewis). Here we pose a hypothetical “if” question: if pushing the button causes a crash, we may equally say “if the button had not been pressed, then the crash would not have happened.” As an exercise, the reader should verify that the above cases are neatly resolved by this improved model of causality. Alas, the counterfactual model is not without its problems as well:
- Suppose that our crashing program has two bugs (here we use “bug” in the sense of “source code defect”). Is it true that the first bug causes the crash? Well, if we removed that bug, the program would continue to crash. Thus, under the counterfactual theory of causation, the first bug doesn’t cause the crash. Neither does the second bug, for that matter. We have a case of causal overdetermination. (Lewis claims the true cause of the bug is the disjunction of the two bugs. Perhaps not too surprising for a computer scientist, but this sounds genuinely weird when applied to every-day life.)
- Suppose that our crashing program has a bug. However, removing the first bug exposes a latent bug elsewhere, which also causes crashes. It’s false to say removing the first bug would cause the crashing to go away, so it does not cause the crash. This situation is called causal preemption. (Lewis’s situation here is to distinguish between causal dependence and causal chains.)
What a software engineer realizes when reading these philosophers is that the convoluted and strange examples of causation are in fact very similar to the knots of causality he is attached to on a day-to-day basis. The analysis here is not too complicated, but it sets the stage for theories of laws of nature, and also nicely introduces the kind of philosophical thinking that encourages consideration of edge-cases: a virtuous trait for software engineers!
One of the most famous debates in philosophy of science to spill over into popular discourse is the debate on scientific methodology—how scientists carry out their work and how theories are chosen. I find this debate has direct parallels into the art of debugging, one of the most notoriously difficult skills to teach fledgling programmers. Here we’ll treat two of the players: inductivism (or confirmation theory) and falsificationism (put forth by Karl Popper.)
Sherlock Holmes once said this about theories: “Insensibly one begins to twist facts to suit theories, instead of theories to suit facts.” He advocated an inductivist methodology, in which the observer dispassionately collects before attempting to extract some pattern of them—induction itself is generalization from a limited number of cases. Under this banner, one is simply not allowed to jump to conclusions while they are still collecting data. This seems like a plausible thing to ask of people, especially perhaps profilers who are collecting performance data. The slogan, as A.F. Chalmers puts it, is “Science is derived from facts.”
Unfortunately, it is well known among philosophers of science that pure inductivism is deeply problematic. These objects range from perhaps unresolvable foundational issues (Hume’s problem of induction) to extremely practical problems regarding what scientists actually practice. Here is a small sampling of the problems:
- What are facts? On one level, facts are merely sense expressions, and it’s an unreasonable amount of skepticism to doubt those. But raw sense expressions are not accessible to most individuals: rather, they are combined with our current knowledge and disposition to form facts. An expert programmer will “see” something very different from an error message than a normal end-user. Fact-gathering is not egalitarian.
- Facts can be fallible. Have you ever analyzed a situation, derived some facts from it, only to come back later and realize, wait, your initial assessment was wrong? The senses can lie, and even low-level interpretations can be mistaken. Inductivism doesn’t say how we should throw out suspicious facts.
- Under what circumstances do we grant more weight to facts? The inductivist says that all facts are equal, but surely this is not true: we value more highly facts which resulted from public, active investigation, than we do facts that were picked up from a private, passive experience. Furthermore, an end-user may report a plethora of facts, all true, which an expert can instantly identify as useless.
- And, for a pure bit of philosophy, the problem of induction says that we have no reason to believe induction is rational. How do we know induction works? We’ve used in the past successfully. But the act of generalizing this past success to the future is itself induction, and thus the justification is circular.
This is not to say that inductivism cannot be patched up to account for some of these criticisms. But certainly the simple picture is incomplete. (You may also accuse me of strawman beating. In an educational context, I don”t think there is anything wrong here, since the act of beating a strawman can also draw out weaknesses in more sophisticated positions—the strawman serves as an exemplar for certain types of arguments that may be employed.)
Karl Popper proposed falsificationism as a way to sidestep the issues plaguing induction. This method should be another one that any software engineer should be familiar with: given a theory, you then seek an observation or experiment that would falsify it. If it is falsified, it is abandoned, and you search for another theory. If it is not, you simply look for something else (Popper is careful to say that we cannot say that the theory was confirmed by this success).
Falsification improves over inductivism by embracing the theory-dependence of observation. Falsificationists don’t care where you get your theory from, as long as you then attempt to falsify it, and also accept the fact that there is no way to determine if a theory is actually true in light of evidence. This latter point is worth emphasizing: whereas induction attempts to make a non-deductive step from a few cases to a universal, falsification can make a deductive step from a negative case to a negative universal. To use a favorite example, it is logically true that if there is a white raven, then not all ravens are black. Furthermore, a theory is better if it is more falsifiable: it suggests a specific set of tests.
As might be expected, naive falsificationism has its problems too, some which are reminiscent of some problems earlier.
- In light of a falsification, we can always modify our theory to account for this particular falsifying instance. This is the so-called ad hoc modification. “All ravens are black, except for this particular raven that I saw today.” Unfortunately, ad hoc modifications may be fair play: after all, there is no reason why software cannot be modified for a particular special case. Better crack open the source code.
- Falsificationism suggests we should always throw out a theory once we have seen falsifying evidence. But as we saw for inductivism, evidence can be wrong. There are many historic cases where new theories were proposed, and it was found that they didn’t actually fit the evidence at hand (Copernicus’s heliocentric model of the universe was one—it did no better than the existing Ptolemaic model at calculating where the planets would be.) Should these new theories have been thrown out? Real scientists are tenacious; they cling to theories, and many times this tenacity is useful.
- To turn this argument on its head, it is never the case that we can test a theory in isolation; rather, an experimental test covers both the theory and any number of auxiliary assumptions about the test setup. When a falsifying test is found, any one of the theory or auxiliary assumptions may be wrong—but we don’t know which! The Duhem-Quine thesis states that given any set of observations, we are always able to modify the auxiliary assumptions to make our theory fit (this thesis may or may not be true, but it is interesting to consider.)
All of these problems highlight how hard it is to come up with an accurate account of what is called the “scientific method.” Simple descriptions do not seem to be adequate: they sound intuitively appealing but have downsides. The practicing scientist is something of an opportunist: he does what works. So is the debugger.
Next time, I hope to talk about quantification, measurement and reduction.
June 3, 2011It is actually surprisingly difficult for a layperson to find out precisely what cryptography Bitcoin uses, without consulting the source of Bitcoin directly. For example, the opcode OP_CHECKSIG, ostensibly checks the signature of something… but there is no indication what kind of signature it checks! (What are opcodes in Bitcoin? Well it turns out that the protocol has a really neat scripting system built in for building transactions. You can read more about it here.) So in fact, I managed to get some factual details wrong on my post Bitcoin is not decentralized, which I realized when commenter cruzer claimed that a break in the cryptographic hash would only reduce mining difficulty, and not allow fake transactions.
So I did my research and cracked open the Bitcoin client source code. The short story is that the thrust of my argument remains the same, but the details of a hypothetical attack against the cryptographic function are a bit more complicated—a simple chosen-prefix collision attack will not be sufficient. The long story? Bitcoin makes some interesting choices of the cryptography it chooses, and the rest of this post will explore those choices. Bitcoin makes use of two hashing functions, SHA-256 and RIPEMD-160, but it also uses Elliptic Curve DSA on the curve secp256k1 to perform signatures. The C++ implementation uses a local copy of the Crypto++ library for mining, and OpenSSL for normal usage. At the end of this post, you should have a better understanding of how Bitcoin employs cryptography to simulate the properties of currency.
In many ways, this is the traditional cryptography in Bitcoin. We ask the question, “How do we know that Alice was authorized to transfer 100 Bitcoins to Bob,” and anyone who has used public-key cryptography knows the answer is, “Alice signs the transaction with her private key and publishes this signature for the Bitcoin network to verify with her public key.” This signature is performed on the secp256k1 elliptic curve (key.h):
CKey()
{
pkey = EC_KEY_new_by_curve_name(NID_secp256k1);
if (pkey == NULL)
throw key_error("CKey::CKey() : EC_KEY_new_by_curve_name failed");
fSet = false;
}
Bitcoin community has discussed the choice of elliptic curve, and it appears this particular one was chosen for possible future speed optimizations.
Like all public cryptography systems, however, Bitcoin does not sign the entire transaction message (that would be far too expensive); rather, it signs a cryptographic hash of the message (script.cpp):
uint256 SignatureHash(CScript scriptCode, const CTransaction& txTo,
unsigned int nIn, int nHashType)
{
// ...
// Serialize and hash
CDataStream ss(SER_GETHASH);
ss.reserve(10000);
ss << txTmp << nHashType;
return Hash(ss.begin(), ss.end());
}
This hash is a double application of SHA-256:
template<typename T1>
inline uint256 Hash(const T1 pbegin, const T1 pend)
{
static unsigned char pblank[1];
uint256 hash1;
SHA256((pbegin == pend ? pblank : (unsigned char*)&pbegin[0]), (pend - pbegin) * sizeof(pbegin[0]), (unsigned char*)&hash1);
uint256 hash2;
SHA256((unsigned char*)&hash1, sizeof(hash1), (unsigned char*)&hash2);
return hash2;
}
Great, so how do we break this? There are several ways:
- We could break the underlying elliptic curve cryptography, by either solving the discrete logarithm problem (this is something quantum computers can do) or by breaking the particular elliptic curve that was chosen. Most research in this area goes towards finding vulnerabilities in specific elliptic curves, so the latter is more likely.
- We could break the underlying cryptographic hash function. In this case, we have a known signature from the user we would like to attack, and we generate another input transaction that hashes to the same value, so we can replay the previous signature. Such an attack would be dependent on the form of the serialized transaction that Bitcoin processes: it does a nontrivial amount of processing on a transaction, so some legwork by the attackers would be necessary; however, because transactions include a scripting system which permits complex transactions to be built, an attacker would have some leeway in constructing such an input. This would not work on single-use addresses, since no such signature exists for replay.
Breaking the signing algorithm requires a selective forgery attack or stronger, and means that arbitrary transactions may be forged and entered into the system. It would be a complete system break. For the signature replay attack, some protection could be gained by adding client-side checks that the same signature is never used for two different transactions.
This is the technically novel use of cryptography in Bitcoin, and it is used to answer the question, “With only traditional signatures, Alice can resend bitcoins she doesn’t actually have as many times as she wants, effectively creating multiple branches of a transaction tree. How do we prevent this?” The answer Bitcoin provides is, “Transaction chains are certified by the solution of a computationally hard problem (mining), and once a transaction is confirmed by its inclusion in a block, clients prefer the transaction chain that has the highest computational cost associated with it, invalidating any other spending on other branches.” Even if you don’t believe in decentralized currency, you have to admit, this is pretty elegant.
In more detail, the computationally hard problem is essentially a watered-down version of the first-preimage attack on a hash function. Miners are given a set of solution hashes (the hash of all zeros to a target hash), and are required to find a message with particular structure (a chain of blocks plus a nonce) that hashes to one of these hashes.
In this case, it is easy to see that a first-preimage attack on a hash function (or perhaps a slightly weaker) attack means that this hashing problem can be solved much more quickly. This is a security break if an adversary knows this method but no one in the network does; he can easily then capture more than 50% of the network’s computing capacity and split the block chain (Remember: this is exponential leverage. I don’t care how many teraflops of power the Bitcoin network has—smart algorithms always win.) In a more serious break, he can rewrite history by reconstructing the entire block chain, performing enough “computational work” to convince other clients on the network that his history is the true one. This attack scenario is well known and is described here. Note that once the method is widely disseminated and adopted by other miners, the computational power imbalance straightens out again, and the difficulty of the hashing problem can be scaled accordingly.
Similar to systems like PGP, Bitcoin users generate public and private keypairs for making signatures, but also publish a convenient “fingerprint”, actually a RIPEMD-160 hash for people to utilize as an identifier for a place you may send Bitcoin to (util.h):
inline uint160 Hash160(const std::vector<unsigned char>& vch)
{
uint256 hash1;
SHA256(&vch[0], vch.size(), (unsigned char*)&hash1);
uint160 hash2;
RIPEMD160((unsigned char*)&hash1, sizeof(hash1), (unsigned char*)&hash2);
return hash2;
}
Unlike systems like PGP, Bitcoin has no public key distribution mechanism: the RIPEMD-160 hash is canonical for a public key. As such, if a collision is discovered in this key space, someone could spend Bitcoins from someone else’s address. This attack scenario is described here. This attack is mitigated by the fact that Bitcoin users are encouraged to use many addresses for their wallet, and that other uses of such collision-power may be more profitable for the attacker (as described above.)
As we can see, multiple different cryptographic primitives are used in ensemble in order to specify the Bitcoin protocol. Compromise of one primitive does not necessarily carry over into other parts of the system. However, all of these primitives are hard-coded into the Bitcoin protocol, and thus the arguments I presented in my previous essay still hold.
June 1, 2011Bitcoin was designed by Satoshi Nakamoto, and the primary client is developed by a bunch of folks at bitcoin.org. Do you care who these people are? In theory, you shouldn’t: all they do is develop an open source client for an open source protocol. Anyone else can develop their own client (and some people have) and no one, save the agreement of everyone in the Bitcoin network, can change the protocol. This is because the Bitcoin network is designed to be decentralized.
If you believe in the long term viability of Bitcoin, you should care who these people are. While Bitcoin itself is decentralized, the transition from Bitcoin to a new currency cannot be. This transition is guaranteed by the fact that all cryptosystems eventually become obsolete. Who will decide how this new currency is structured? Likely the original creators of Bitcoin, and if you have significant holdings in Bitcoin, you should care who these people are.
The following essay will flesh out this argument more carefully, as follows:
- Cryptosystems, including cryptographic hashes, must be used with the understanding that they must eventually be replaced. One might argue that “If Bitcoin’s cryptography is broken, the rest of the financial industry is in trouble too”—we explain why this is irrelevant for Bitcoin. We also see why it’s reasonable to expect Bitcoin, if it becomes a serious currency, to stick around a long enough timespan for this obsolescence to occur.
- There are several rough transition plans circulating the Bitcoin community. We describe the most common decentralized and the most common centralized variant, and explain why the decentralized variant cannot work in a non-disruptive manner, appealing both to economics and existing markets which have similar properties.
- We more carefully examine the implications of these decentralized and centralized transitions, and assess the risk of the transition, in comparison to the other risks facing Bitcoin as a fledgling currency. We suggest that, while the transition of Bitcoin is not a central concern, the idea of naive decentralization is a myth that needs to be dispelled.
I’ve divided the essay into sections so that readers who are interested in specific sections of the argument. Feel free to skip around.
“All cryptosystems eventually become obsolete.” Compared to currency, cryptographic hashes are a relatively recent invention, dating only as far back as the 1970s. MD5 was invented in 1991, and it only took about a decade and a half to thoroughly break it. For computer programmers, the shifting landscape of cryptography is a given, and systems are designed with this in mind. Consider, for example, SSL certificates, which are used to secure many transactions on the Internet, including financial transactions. These need to be renewed every few years, and as new certificates are issued, their level of protection can be increased, to use newer ciphers or longer key sizes. Most current uses of cryptography follow this pattern: the ciphers and keys can be replaced with relative ease.
Bitcoin, however, is special. The way it achieves decentralization is by embedding all of its relevant technical details in the protocol. Among these is the hashing algorithm, SHA-256. It is literally impossible to “change” the hashing algorithm in Bitcoin; any change would constitute a change in the protocol, and thus result in a completely new currency. Don’t believe anyone who tells you otherwise. The argument “If Bitcoin’s cryptography is broken, the rest of the financial industry is in trouble too” is irrelevant, because other financial institutions have central control of the ciphers they use and can easily change them: Bitcoin cannot. And due to the possibility of weaknesses in SHA-1 spilling into the SHA-2 family (among which SHA-256 is a member), a competition for SHA-3 is already being held.
Will Bitcoin last long enough for fraudulent transactions to become practical? It may not (after all, there are many other possible problems with the currency that may kill it off before it ever gets to this stage.) However, if it does become established, you can expect it to be a hardy little bastard. Currencies stick around for a long time.
The Bitcoin community has realized the fact that a transition will become necessary, and though the general sense is that of, “We’ll figure it out when we get there,” there have been some vague proposals floated around. At the risk of constructing strawmen, I would like to now present my perception of the two most popularly voiced plans. First, the decentralized plan:
Because cryptosystems don’t break overnight, once the concern about SHA-256 becomes sufficiently high we will create a new version of Bitcoin that uses a stronger cryptographic hash. We will then let the market decide an exchange rate between these two currencies, and let people move from one to the other.
This is decentralized because anyone can propose a new currency: the market will decide which one will win out in the end. It also cannot possibly work in a nondisruptive manner, for the simple reason that anyone seeking to exchange the old Bitcoin for the new one will have to find a willing buyer, and at some point, hyperinflation will ensure that there are no willing buyers. All existing Bitcoins will then be worthless.
At this point, we’ll take a short detour into the mooncake black market, a fascinating “currency” in China that has many similar properties to an obsolescing Bitcoin. The premise behind this market is that, while giving cash bribes are illegal, giving moon cake vouchers are not. Thus, someone looking to bribe someone can simply “gift” them a moon cake voucher, which is then sold on the black market to be converted back into cash.
Those partaking in the moon cake black market must be careful, because once the Autumn Festival arrives, all of these vouchers must be exchanged for moon cakes or become worthless. As the date arrives, you see an increasingly frenzied game of hot potato for the increasingly devalued vouchers. The losers? They end up with lots of moon cakes. There is of course one critical difference, which is that the losers of the Bitcoin game are left with nothing at all.
Is this a transition? Yes. Is it disruptive? Definitely yes. It is certainly not what you want a currency you’re using for every day transactions to be doing. Of course, this may be acceptable risk for some industries, and we’ll analyze this more in the last section.
Here is the centralized plan:
Once the concern for the hashing algorithm is high enough, we will create a new Bitcoin protocol. This protocol will not only include a new hashing algorithm, but also be based off of the value of the old Bitcoin economy at some date: at that point, all newer transactions are invalid in the new Bitcoin scheme, and that snapshot is used to determine the amount of Bitcoins everyone has.
There is a variant, which deals with the case when active attacks are being carried out against the hashing algorithm before they have managed to switch, which involves marking specific block chains as known good, and zeroing out suspected fraudulent transactions.
Is this plan really centralized? Yes: someone needs to design the new protocol, to convince all the clients to buy into it, and to uniformly switch over to the new economy when the day arrives. The fragmentation of the Bitcoin economy would be extremely disruptive and not in the best interests of any of the main players. Any other changes to the Bitcoin protocol (and at this point, there probably would be many proposals) could have massive implications for the Bitcoin economy.
Here, we assess the question, “Do I really care?” In the short term, no. Bitcoin has many, many weaknesses that it will be tested against. Though I personally hope it will succeed (it is certainly a grand experiment that has never been carried out before), my assessment is that its chances are not good. Worrying excessively about the transition is not a good use of time.
However, this does not mean that it is not an important fact to remember. The future of Bitcoin depends on those who will design its successor. If you are investing substantially in Bitcoin, you should at the very least be thinking about who has the keys to the next kingdom. A more immediate issue are the implications of a Bitcoin client monoculture (one could push out an update that tweaks the protocol for nefarious purposes). Those using Bitcoin should diversify their clients as soon as possible. You should be extremely skeptical of updates which give other people the ability to flip your client from one version of the protocol to another. Preserve the immutability of the protocol as much as possible, for without it, Bitcoin is not decentralized at all.
Thanks to Nelson Elhage, Kevin Riggle, Shae Erisson and Russell O’Connor for reading and commenting on drafts of this essay.
Update. Off-topic comments will be ruthlessly moderated. You have been warned.
Update two. One possible third succession plan that has surfaced over discussion at Hacker News and Reddit is the decentralized bootstrapped currency. Essentially, multiple currencies compete for buy-in and adoption, but unlike the case of two completely separate currencies separated only by an exchange rate, these currencies are somehow pegged to the old Bitcoin currency (perhaps they reject all Bitcoin transactions after some date, or they require some destructive operation in order to convert an old Bitcoin into a new one—the latter may have security vulnerabilities.) I have not analyzed the economic situation in such a case, and I encourage someone else to take it up. My hunch is that it will still be disruptive; perhaps even more so, due to the artificial pegging of the currency.
May 30, 2011(Guess what Edward has in a week: Exams! The theming of these posts might have something to do with that…)
At this point in my life, I’ve taken a course on introductory artificial intelligence twice. (Not my fault: I happened to have taken MIT’s version before going to Cambridge, which also administers this material as part of the year 2 curriculum.) My first spin through 6.034 was a mixture of disbelief at how simple the algorithms were, indignation at their examination methods, and the vague sense at the end that I really should have paid more attention. My second time through, I managed to distill a lot more algorithmic content out of the course, since I wasn’t worrying as much about the details.
The topic of today’s post is one such distillation of algorithmic content from the neural network learning process. Well, at least, for multilayer perceptrons—since that’s what usually gets studied as a case of neural networks. It should be noted that the perceptron is a really simple sort of mathematical function: it’s a multivariable function that takes as arguments a weight vector and an input vector, takes their dot product and runs the result through an activation function (which is usually chosen so that it has nice properties when differentiated.) “Learning” in this case is first-order optimization via gradient descent, and the primarily computational content involves calculating the partial derivative of the function with respect to the weight vector—something that anyone who has taken multivariable calculus ought to be able to do in his sleep.
Note that I say ought. Actually, neural networks gave me a pretty horrendous time both times I had to learn it. Part of the trouble is that once you’ve worked out the update formulas, you don’t actually need to understand the derivation: they “just work.” Of course, no self-respecting course would want to quiz you on your ability to memorize the relevant equations, so they’ll usually ask you to write out the derivation. There you run into the second trouble: most presentations of the derivation are quite long and don’t “compress” well.
The first insight into the process, which I (eventually) picked up the first time I took the course, was that these derivations were actually just repeatedly applying the chain rule. Thus, the laborious analysis of all of the partial derivatives can be replaced with the following algorithm: “Chop the perceptron into smaller functions, calculate the derivative of each function, and then multiply the results back together.” Now, this does require a little bit of care: one normally visualizes the perceptron network as a function on the input values, but the derivative is with respect to the weights. Furthermore, the perceptron network is a much more involved partial differentiation problem than one usually finds on a multivariable calculus exam, so if you don’t have your variable indexing sorted out it’s very easy to get confused. (Here, a notion of fresh names and global names comes in handy, because it sets the ground rules for notational sleights of hands that mathematicians do freely and confusingly.) If you have the chain rule in your arsenal, you have a fairly convincing story for the output perceptron, and with a little bit more confusion you might manage the the internal perceptrons too.
The second insight into the process I didn’t pick up until my second time around: it is the resemblance of backpropagation to dynamic programming. This involved the realization that, in principle, I could calculate the partial derivative of the function with respect to any weight simply by tracing out the nodes “downstream” from it, and calculating the (longer) derivative chains manually. I could do this for every node, although it might get a bit tedious: the key idea of “backpropagation” is that you can reuse results for an efficiency increase, just as you do for dynamic programming. It is also gratifying to see that this explains why both treatments I’ve seen of neural nets obsess over δ, a seemingly innocuous derivative that really shouldn’t get its own symbol. The reason is this value is precisely what is stored in the dynamic programming table (in this case, shaped the same way as the input neural net); the actual partial derivative for a weight isn’t actually what we need. This is actually fairly common, as far as contest dynamic programming problems go—part of the trick is figuring out what intermediate calculations you also need to store in your table. Backpropagation is then just filling out the table from the output node to the input nodes.
So there you have it: chain rule + dynamic programming = neural network backpropagation algorithm. Of course, this formulation requires you to know how to do the chain rule, and know how to do dynamic programming, but I find these concepts much easier to keep in my brain, and their combination pleasantly trivial.
Postscript. No lecturer can resist the temptation to expound on what they think “artificial intelligence” is. I’ll take this opportunity to chime in: I believe that AI is both a problem and an approach:
- Artificial intelligence is a problem, insofar as asking the question “What can humans do that computers cannot” is a tremendous way of digging up computationally interesting problems, and
- Artificial intelligence is an approach, insofar as instances of intelligence in nature suggest possible solutions to computational problems.
I have tremendous respect for the power of AI to frame what questions researchers should be asking, and if we say an approach is AI because it handles a problem in this domain quite well, AI is everywhere. (It also explains why AI thrives at MIT, a very engineering oriented school.) I am still, however, skeptical about “biological inspiration”, since these approaches doesn’t actually seem to work that well (e.g. the fall of “traditional” AI and the rise of statistical NLP methods), and the fact that the resulting methods are a far cry from their biological counterparts, as any neuroscientist who is familiar with “neural” networks may attest. In some cases, the biological analogies may be actively harmful, obscuring the core mathematical issues.