Today I would like to describe how I pin down compiler bugs, specifically, bugs tickled by optimizations, using a neat feature that Hoopl has called optimization fuel. Unfortunately, this isn’t a particularly Googleable term, so hopefully this post will get some Google juice too. Optimization fuel was originally introduced by David Whalley in 1994 in a paper Automatic isolation of compiler errors. The basic idea is that all optimizations performed by the compiler can be limited (e.g. by limiting the fuel), so when we suspect the optimizer is misbehaving, we binary search to find the maximum amount of fuel we can give the compiler before it introduces the bug. We can then inspect the offending optimization and fix the bug. Optimization fuel is a feature of the new code generator, and is only available if you pass -fuse-new-codegen to GHC.
Read more...
Once you’ve determined what dataflow facts you will be collecting, the next step is to write the transfer function that actually performs this analysis for you!
Remember what your dataflow facts mean, and this step should be relatively easy: writing a transfer function usually involves going through every possible statement in your language and thinking about how it changes your state. We’ll walk through the transfer functions for constant propagation and liveness analysis.
Read more...
The essence of dataflow optimization is analysis and transformation, and it should come as no surprise that once you’ve defined your intermediate representation, the majority of your work with Hoopl will involve defining analysis and transformations on your graph of basic blocks. Analysis itself can be further divided into the specification of the dataflow facts that we are computing, and how we derive these dataflow facts during analysis. In part 2 of this series on Hoopl, we look at the fundamental structure backing analysis: the dataflow lattice. We discuss the theoretical reasons behind using a lattice and give examples of lattices you may define for optimizations such as constant propagation and liveness analysis.
Read more...
Hoopl is a higher-order optimization library. We think it’s pretty cool! This series of blog post is meant to give a tutorial-like introduction to this library, supplementing the papers and the source code. I hope this series will also have something for people who aren’t interested in writing optimization passes with Hoopl, but are interested in the design of higher-order APIs in Haskell. By the end of this tutorial, you will be able to understand references in code to names such as analyzeAndRewriteFwd and DataflowLattice, and make decode such type signatures as:
Read more...
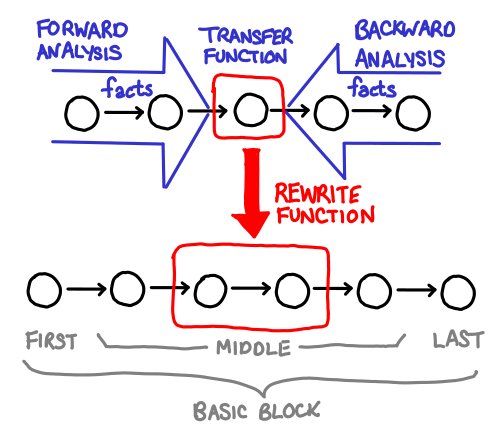
Hoopl is a “higher order optimization library.” Why is it called “higher order?” Because all a user of Hoopl needs to do is write the various bits and pieces of an optimization, and Hoopl will glue it all together, the same way someone using a fold only needs to write the action of the function on one element, and the fold will glue it all together.
Unfortunately, if you’re not familiar with the structure of the problem that your higher order functions fit into, code written in this style can be a little incomprehensible. Fortunately, Hoopl’s two primary higher-order ingredients: transfer functions (which collect data about the program) and rewrite functions (which use the data to rewrite the program) are fairly easy to visualize.
Read more...