I’ve had the pleasure of attending a number of really interesting talks over the past few months, so many that I couldn’t find time to write thorough articles for each of them as I did over the summer. So you’ll have to forgive me for putting two of them in compressed form here. There is something of a common theme of recasting a problem on a different input domain in order to achieve results, as I hope will become evident by these summaries.
Read more...
One of the distinctive differences between academic institutions in the United States and in Great Britain is the supplementary learning outside of lectures. We have recitations in the US, which are something like extra lectures, while in the UK they have tutorials, or supervisions as they are called in Cambridge parlance. As always, they are something of a mixed bag: some supervisors are terrible, others are merely competent, and others inspire and encourage a sort of interest in the subject far beyond the outlines of the course.
Read more...
In which Mendeley, Software Foundations and Coq are discussed.
I was grousing on #haskell-blah one day about how annoying it was to organize all of the papers that I have downloaded (and, of course, not read yet.) When you download a paper off the Internet, it will be named all sorts of tremendously unhelpful things like 2010.pdf or icfp10.pdf or paper.pdf. So to have any hope of finding that paper which you skimmed a month ago and vaguely recall the title of, you’ll need some sort of organization system. Pre-Mendeley, I had adopted the convention of AuthorName-PaperTitle.pdf, but I’d always feel a bit bad picking an author out of a list of five people to stick at the beginning, and I still couldn’t ever find the paper I was looking for.
Read more...
The On-Line Encyclopedia of Integer Sequences is quite a nifty website. Suppose that you’re solving a problem, and you come up with the following sequence of integers: 0, 1, 0, 2, 0, 1, 0, 3, 0, 1, 0, 2... and you wonder to yourself: “huh, what’s that sequence?” Well, just type it in and the answer comes back: A007814, along with all sorts of tasty tidbits like constructions, closed forms, mathematical properties, and more. Even simple sequences like powers of two have a bazillion alternate interpretations and generators.
Read more...
I’ve been wanting to implement a count-min sketch for some time now; it’s a little less widely known than the bloom filter, a closely related sketch data structure (that is, a probabilistic data structure that approximates answers to certain queries), but it seems like a pretty practical structure and has been used in some interesting ways.
Alas, when you want to implement a data structure that was proposed less than a decade ago and hasn’t found its way into textbooks yet, there are a lot of theoretical vagaries that get in the way. In this particular case, the theoretical vagary was selection of a universal hash family. Having not taken a graduate-level algorithms course yet, I did not know what a universal hash family was, so it was off to the books for me.
Read more...
This is a bit of a provocative post, and its impressions (I dare not promote them to the level of conclusions) should be taken with the amount of salt found in a McDonald’s Happy Meal. Essentially, I was doing some reading about medieval medicine and was struck by some of the similarities between it and computer engineering, which I attempt to describe below.
Division between computer scientists and software engineers. The division between those who studied medicine, the physics (a name derived from physica or natural science) and those who practiced medicine, the empirics, was extremely pronounced. There was a mutual distrust—Petrarch wrote, “I have never believed in doctors nor ever will” (Porter 169)—that stemmed in part from the social division between the physics and empirics. Physics would have obtained a doctorate from a university, having studied one of the highest three faculties possible (the others being theology and law), and tended to be among the upper strata of society. In fact, the actual art of medicine was not considered “worthy of study,” though the study of natural science was. (Cook 407).
Read more...
Someone told me it’s all happening at the zoo…
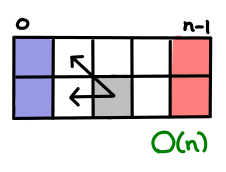
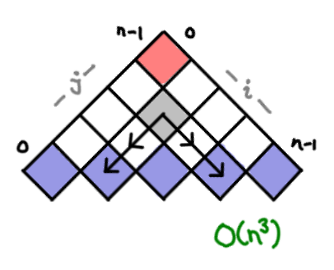
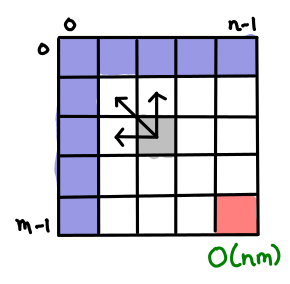
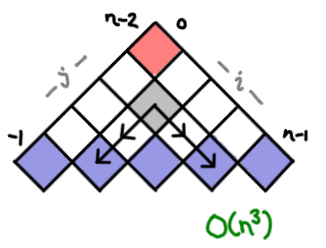
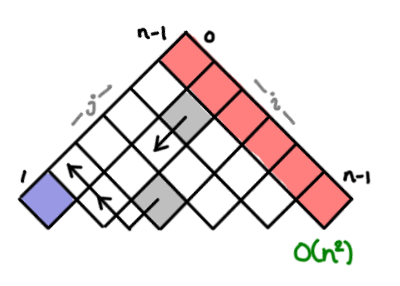
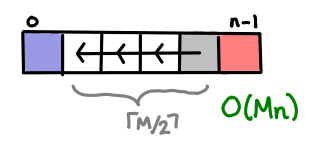
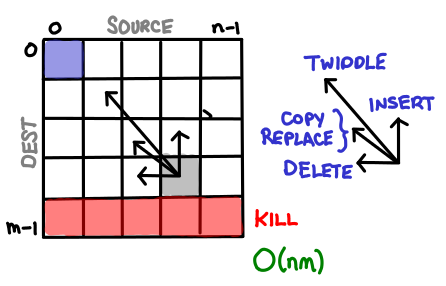
I’ve always thought dynamic programming was a pretty crummy name for the practice of storing sub-calculations to be used later. Why not call it table-filling algorithms, because indeed, thinking of a dynamic programming algorithm as one that fills in a table is a quite good way of thinking about it.
In fact, you can almost completely characterize a dynamic programming algorithm by the shape of its table and how the data flows from one cell to another. And if you know what this looks like, you can often just read off the complexity without knowing anything about the problem.
Read more...
In which the author muses that “semi-formal methods” (that is, non computer-assisted proof writing) should take a more active role in allowing software engineers to communicate with one another.
C++0x has a lot of new, whiz-bang features in it, one of which is the atomic operations library. This library has advanced features that enable compiler writers and concurrency library authors to take advantage of a relaxed memory model, resulting in blazingly fast concurrent code.
Read more...
Hoare logic, despite its mathematical sounding name, is actually a quite practical way of reasoning about programs that most software engineers subconsciously employ in the form of preconditions and postconditions. It explicitly axiomatizes things that are common sense to a programmer: for example, a NOP should not change any conditions, or if a line of code has a postcondition that another line of code has as its precondition, those lines of code can be executed one after another and the inner precondition-postcondition pair ignored. Even if you never actually write out the derivation chains, you’re informally applying Hoare logic when you are trying to review code that uses preconditions and postconditions. Hoare logic is an abstraction that lets us rigorously talk about any imperative language with the same set of rules.
Read more...