Last post, I talked about some of the notable difficulties in emulating pthread_cancel on Windows. Today, I want to talk about what a platform agnostic compiler like GHC actually ought to do. Recall our three design goals:
- GHC would like to be able to put blocking IO calls on a worker thread but cancel them later; it can currently do this on Linux but not on Windows,
- Users would like to write interrupt friendly C libraries and have them integrate seamlessly with Haskell’s exception mechanism, and
- We’d like to have the golden touch of the IO world, instantly turning blocking IO code into nice, well-behaved, non-blocking, interruptible code.
I am going to discuss these three situations, described concisely as blocking system calls, cooperative libraries and blocking libraries. I propose that, due to the lack of a cross-platform interruption mechanism, the correct interruptibility interface is to permit user defined handlers for asynchronous exceptions.
Read more...
Edward, I’m afraid I have some bad news. Your interruptible GHC patch; it was involved in a terrible accident on the way to Windows portability. I hope you understand: we’re doing our best to patch it up, but there have been some complications…
Pop quiz! What does this pthreads code do? :
#include <pthread.h>
#include <stdio.h>
void *thread1(void *arg) { sleep(10000); }
void *thread2(void *arg) { while (1) {} }
void *psycho_killer(void *arg) {
pthread_t *id = (pthread_t*)arg;
pthread_cancel(*id);
printf("[%p] Psycho killer...\n", id);
pthread_join(*id, NULL);
printf("[%p] ...qu'est-ce que c'est.\n", id);
}
int main(char* argv, int argc) {
pthread_t t1, t2, k1, k2;
pthread_create(&t1, NULL, thread1, NULL);
printf("[%p] I can't sleep 'cause my bed's on fire\n", &t1);
pthread_create(&t2, NULL, thread2, NULL);
printf("[%p] Don't touch me I'm a real live wire\n", &t2);
pthread_create(&k1, NULL, psycho_killer, &t1);
pthread_create(&k2, NULL, psycho_killer, &t2);
pthread_join(k1, NULL);
pthread_join(k2, NULL);
printf("Run run run away!\n");
return 0;
}
It never manages to terminate the second thread…
Read more...
In my tech talk about abcBridge, one of the “unsolved” problems I had with making FFI code usable as ordinary Haskell code was interrupt handling. Here I describe an experimental solution involving a change to the GHC runtime system as suggested by Simon Marlow. The introductory section may be interesting to practitioners looking for working examples of code that catches signals; the later section is a proof of concept that I hope will turn into a fully fleshed out patch. :
Read more...
While attempting to figure out how I might explain lazy versus strict bytestrings in more depth without boring half of my readership to death, I stumbled upon a nice parallel between a standard implementation of buffered streams in imperative languages and iteratees in functional languages.
No self-respecting input/output mechanism would find itself without buffering. Buffering improves efficiency by grouping reads or writes together so that they can be performed as a single unit. A simple read buffer might be implemented like this in C (though, of course, with the static variables wrapped up into a data structure… and proper handling for error conditions in read…):
Read more...
Foreign.ForeignPtr is a magic wand you can wave at C libraries to make them suddenly garbage collected. It’s not quite that simple, but it is pretty darn simple. Here are a few quick tips from the trenches for using foreign pointers effectively with the Haskell FFI:
- Use them as early as possible. As soon as a pointer which you are expected to free is passed to you from a foreign imported function, you should wrap it up in a ForeignPtr before doing anything else: this responsibility lies soundly in the low-level binding. Find the functions that you have to import as
FunPtr. If you’re using c2hs, declare your pointers foreign. - As an exception to the above point, you may need to tread carefully if the C library offers more than one way to free pointers that it passes you; an example would be a function that takes a pointer and destroys it (likely not freeing the memory, but reusing it), and returns a new pointer. If you wrapped it in a ForeignPtr, when it gets garbage collected you will have a double-free on your hands. If this is the primary mode of operation, consider a
ForeignPtr (Ptr a) and a customized free that pokes the outside foreign pointer and then frees the inner pointer. If there is no logical continuity with respect to the pointers it frees, you can use a StablePtr to keep your ForeignPtr from ever being garbage collected, but this is effectively a memory leak. Once a foreign pointer, always a foreign pointer, so if you can’t commit until garbage do us part, don’t use them. - You may pass foreign pointers to user code as opaque references, which can result in the preponderance of newtypes. It is quite useful to define
withOpaqueType so you don’t have to pattern-match and then use withForeignPtr every time your own code peeks inside the black box. - Be careful to use the library’s
free equivalent. While on systems unified by libc, you can probably get away with using free on the int* array you got (because most libraries use malloc under the hood), this code is not portable and will almost assuredly crash if you try compiling on Windows. And, of course, complicated structs may require more complicated deallocation strategies. (This was in fact the only bug that hit me when I tested my own library on Windows, and it was quite frustrating until I remembered Raymond’s blog post.) - If you have pointers to data that is being memory managed by another pointer which is inside a ForeignPtr, extreme care must be taken to prevent freeing the ForeignPtr while you have those pointers lying around. There are several approaches:
- Capture the sub-pointers in a Monad with rank-2 types (see the
ST monad for an example), and require that the monad be run within a withForeignPtr to guarantee that the master pointer stays alive while the sub-pointers are around, and guarantee that the sub-pointer can’t leak out of the context. - Do funny things with
Foreign.ForeignPtr.Concurrent, which allows you to use Haskell code as finalizers: reference counting and dependency tracking (only so long as your finalizer is content with being run after the master finalizer) are possible. I find this very unsatisfying, and the guarantees you can get are not always very good.
- If you don’t need to release a pointer into the wild, don’t! Simon Marlow acknowledges that finalizers can lead to all sorts of pain, and if you can get away with giving users only a bracketing function, you should consider it. Your memory usage and object lifetime will be far more predictable.
Update. While this blog post presents two true facts, it gets the causal relationship between the two facts wrong. Here is the correction.
Attention conservation notice. Don’t use unsafe in your FFI imports! We really mean it!
Consider the following example in from an old version of Haskellwiki’s FFI introduction:
{-# INCLUDE <math.h> #-}
{-# LANGUAGE ForeignFunctionInterface #-}
module FfiExample where
import Foreign.C -- get the C types
-- pure function
-- "unsafe" means it's slightly faster but can't callback to haskell
foreign import ccall unsafe "sin" c_sin :: CDouble -> CDouble
sin :: Double -> Double
sin d = realToFrac (c_sin (realToFrac d))
The comment blithely notes that the function can’t “callback to Haskell.” Someone first learning about the FFI might think, “Oh, that means I can put most unsafe on most of my FFI declarations, since I’m not going to do anything advanced like call back to Haskell.”
Read more...
In the beginning, there was a binary tree:
struct ctree { // c for children
int val;
struct ctree *left;
struct ctree *right;
}
The flow of pointers ran naturally from the root of the tree to the leaves, and it was easy as blueberry pie to walk to the children of a node.
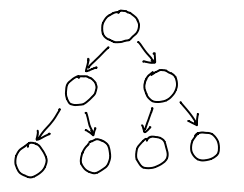
Unfortunately, given a node, there was no good way to find out its parent! If you only needed efficient parent access, though, you could just use a single pointer in the other direction:
Read more...
C is the classic go-to tool for small programs that need to be really fast. When scripts.mit.edu needed a small program to be a glorified cat that also added useful HTTP headers to the beginning of its output, there was no question about it: it would be written in C, and it would be fast; the speed of our static content serving depended on it! (The grotty technical details: our webserver is based off of a networked filesystem, and we wanted to avoid giving Apache too many credentials in case it got compromised. Thus, we patched our kernel to enforce an extra stipulation that you must be running as some user id in order to read those files off the filesystem. Apache runs as it’s own user, so we need another small program to act as the go-between.)
Read more...
A classic stylistic tip given to C programmers is that inline functions should be preferred over macros, when possible. This advice stems from the fact that a macro and an inline function can achieve the same effect, but the inline function also gets type checking.
As it turns out, you can achieve static type checking with macros, if you’re willing to resort to the same cute trick that this following snippet from the Linux kernel uses:
Read more...