Let's talk about the PyTorch dispatcher
September 10, 2020
If this is your first time reading about PyTorch internals, you might want to check out my PyTorch internals post first. In this post, I want to talk about one particular part of PyTorch’s internals: the dispatcher. At a first glance, the dispatcher is just a glorified if statement: based on some information about the tensor inputs, decide what piece of code should be called. So why should we care about the dispatcher?

Well, in PyTorch, a lot of things go into making an operator work. There is the kernel that does the actual work, of course; but then there is support for reverse mode automatic differentiation, e.g., the bits that make loss.backward() work. Oh, and if your code under torch.jit.trace, you can get a trace of all the operations that were run. Did I mention that if you run these operations on the inside of a vmap call, the batching behavior for the operators is different? There are so many different ways to interpret PyTorch operators differently, and if we tried to handle all of them inside a single function named add, our implementation code would quickly devolve into an unmaintainable mess. The dispatcher is not just an if statement: it is a really important abstraction for how we structure our code internally PyTorch… and it has to do so without degrading the performance of PyTorch (too much, anyway).
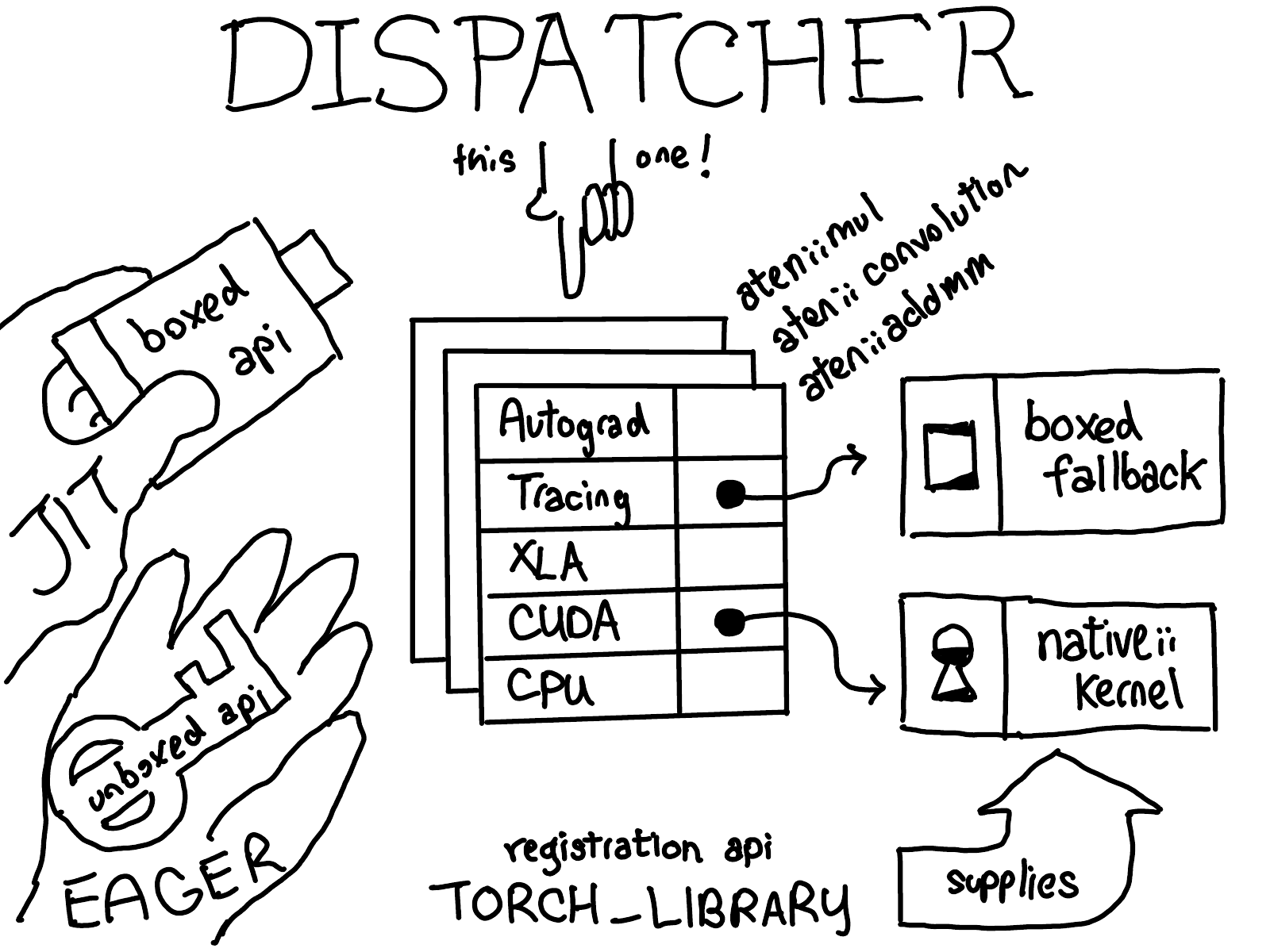
At the end of this post, our goal will be to understand all the different parts of this picture fit together. This post will proceed in three parts.
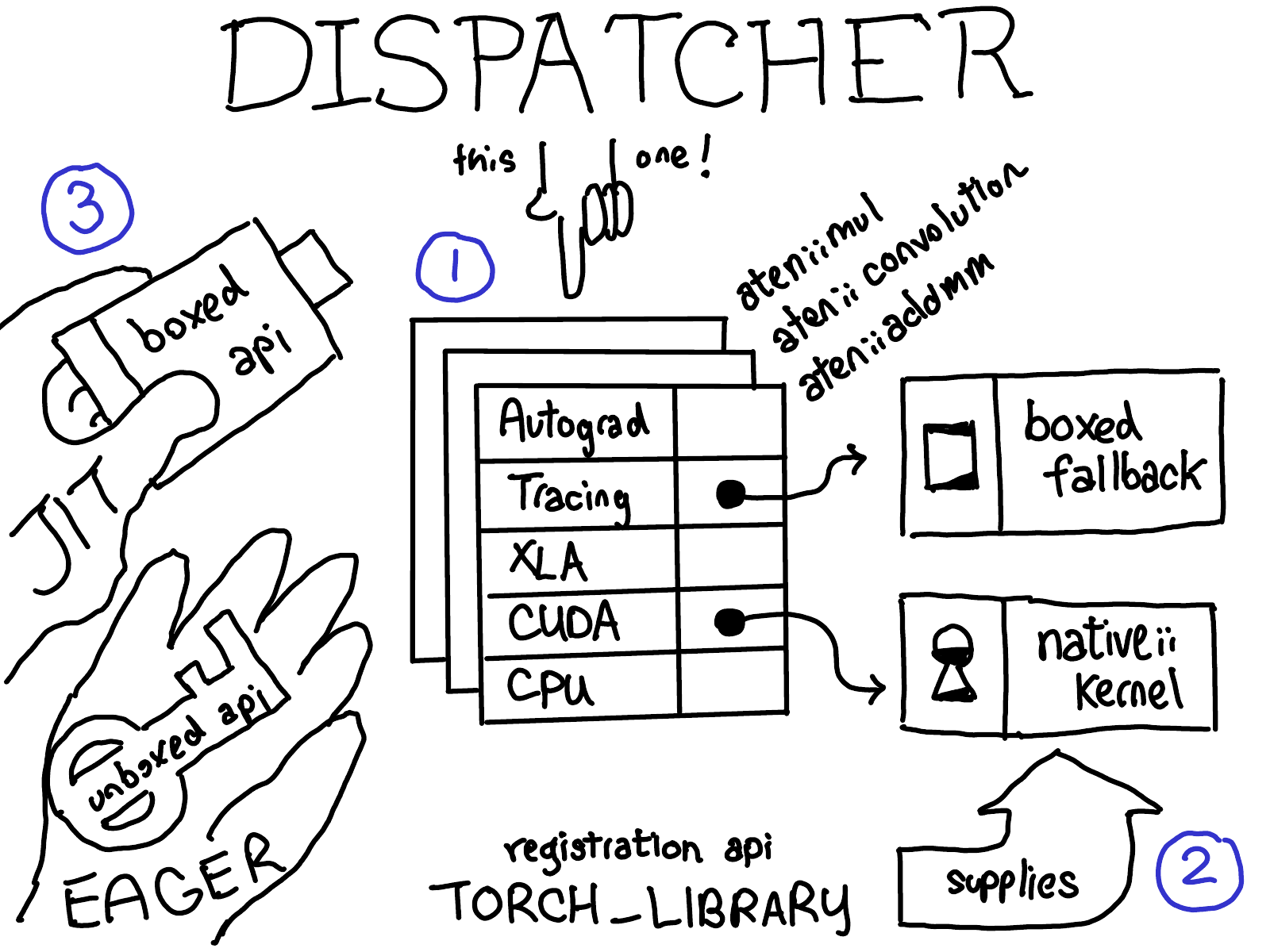
First, we’ll talk about the dispatcher itself. What is the dispatcher, how does it decide what kernel to call? Second, we’ll talk about the operator registration API, which is the interface by which we register kernels into the dispatcher. Finally, we’ll talk about boxing and unboxing, which are a cross-cutting feature in the dispatcher that let you write code once, and then have it work on all kernels.
What is the dispatcher?¶
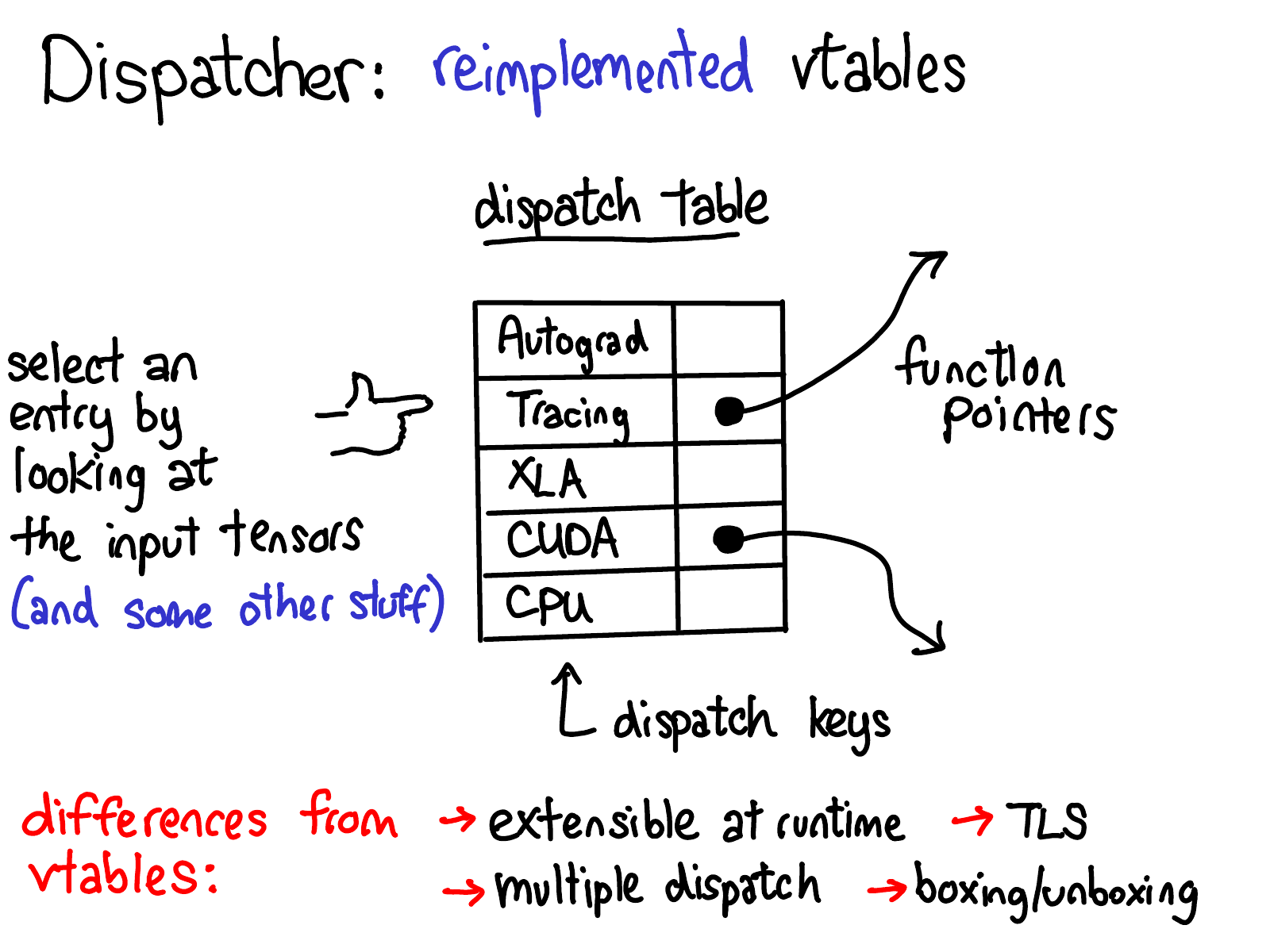
OK, so what is the dispatcher? For every operator, the dispatcher maintains a table of function pointers which provide implementations for each dispatch key, which corresponds roughly to one of the cross-cutting concerns in PyTorch. In the diagram above, you can see there are dispatch entries in this table for backends (CPU, CUDA, XLA) as well as higher-level concepts like autograd and tracing. The dispatcher’s job is to compute a dispatch key, based on the input tensors and some other stuff (more on this shortly), and then do an indirect jump to the function pointed to by the table.
Those of you who are familiar with C++ may observe that this table of function pointers is very similar to virtual tables in C++. In C++, virtual methods on objects are implemented by associating every object with a pointer to a virtual table that contains implementations for each virtual method on the object in question. In PyTorch, we essentially reimplemented virtual tables, but with some differences:
- Dispatch tables are allocated per operator, whereas vtables are allocated per class. This means that we can extend the set of supported operators simply by allocating a new dispatch table, in contrast to regular objects where you can extend from a class, but you can’t easily add virtual methods. Unlike normal object oriented systems, in PyTorch most of the extensibility lies in defining new operators (rather than new subclasses), so this tradeoff makes sense. Dispatch keys are not openly extensible, and we generally expect extensions who want to allocate themselves a new dispatch key to submit a patch to PyTorch core to add their dispatch key.
- More on this in the next slide, but the computation of our dispatch key considers all arguments to the operator (multiple dispatch) as well as thread-local state (TLS). This is different from virtual tables, where only the first object (
this) matters. - Finally, the dispatcher supports boxing and unboxing as part of the calling convention for operators. More on this in the last part of the talk!
Fun historical note: we used to use virtual methods to implement dynamic dispatch, and reimplemented them when we realized we needed more juice than virtual tables could give us.
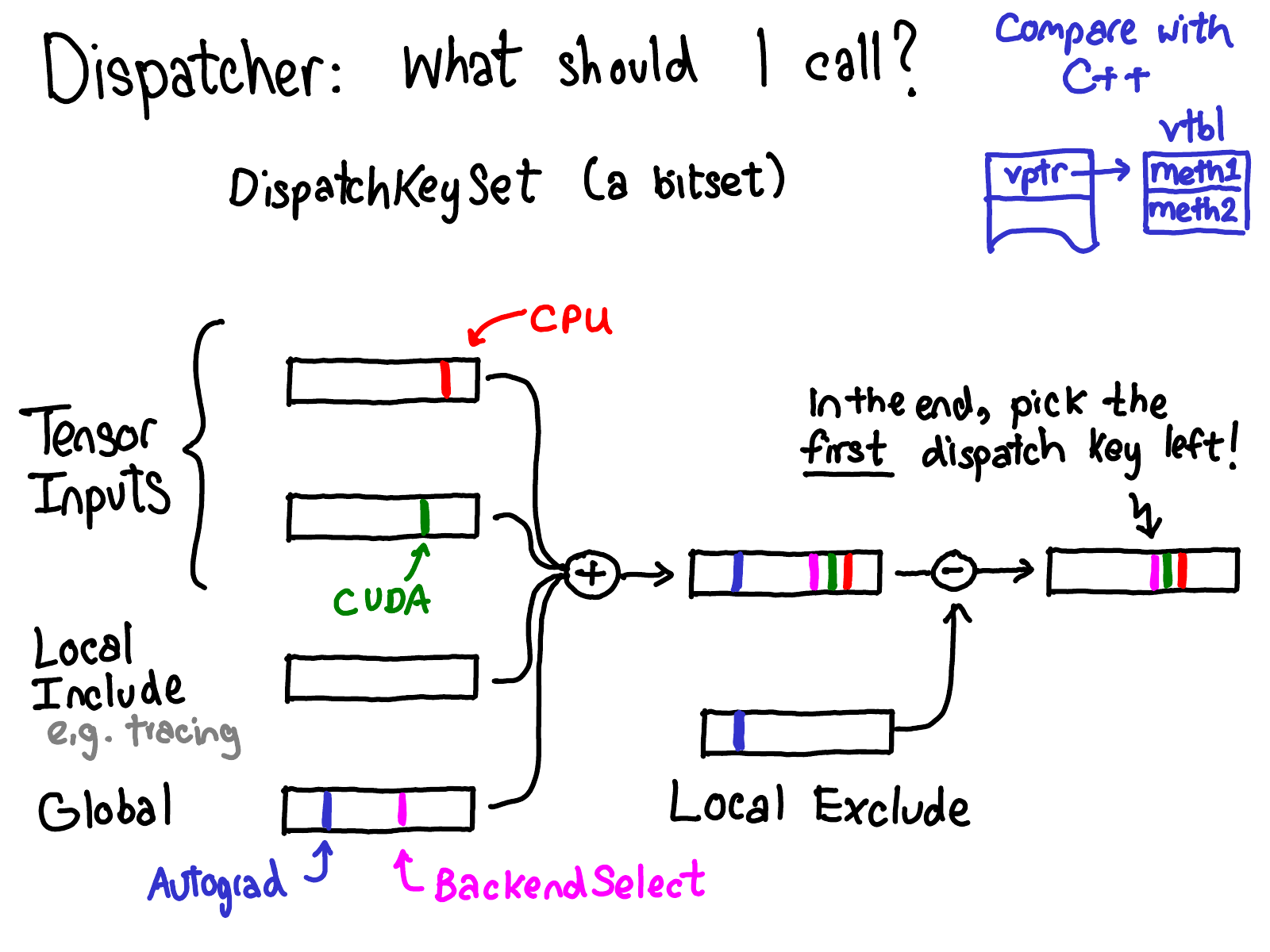
So how exactly do we compute the dispatch key which we use to index into the dispatch table? The basic abstraction we use for computing what dispatch key to use is a dispatch key set, which is a bitset over dispatch keys. The general concept is that we union together dispatch key sets from various sources (and in some case mask out some dispatch keys), giving us a final dispatch key set. Then, we pick the first dispatch key in the set (dispatch keys are implicitly ordered by some priority) and that is where we should dispatch to. What are these sources?
- Each tensor input contributes a dispatch key set of all dispatch keys that were on the tensor (intuitively, these dispatch keys will be things like CPU, telling us that the tensor in question is a CPU tensor and should be handled by the CPU handler on the dispatch table)
- We also have a local include set, which is used for “modal” functionality, such as tracing, which isn’t associate with any tensors, but instead is some sort of thread local mode that a user can turn on and off within some scope.
- Finally, we have a global set, which are dispatch keys that are always considered. (Since the time this slide was written, Autograd has moved off the global set and onto tensor. However, the high level structure of the system hasn’t changed).
There is also a local exclude set, which is used to exclude dispatch keys from dispatch. A common pattern is for some handler to handle a dispatch key, and then mask itself off via the local exclude set, so we don’t try reprocessing this dispatch key later.
Let’s walk through the evolution of dispatch key through some examples.
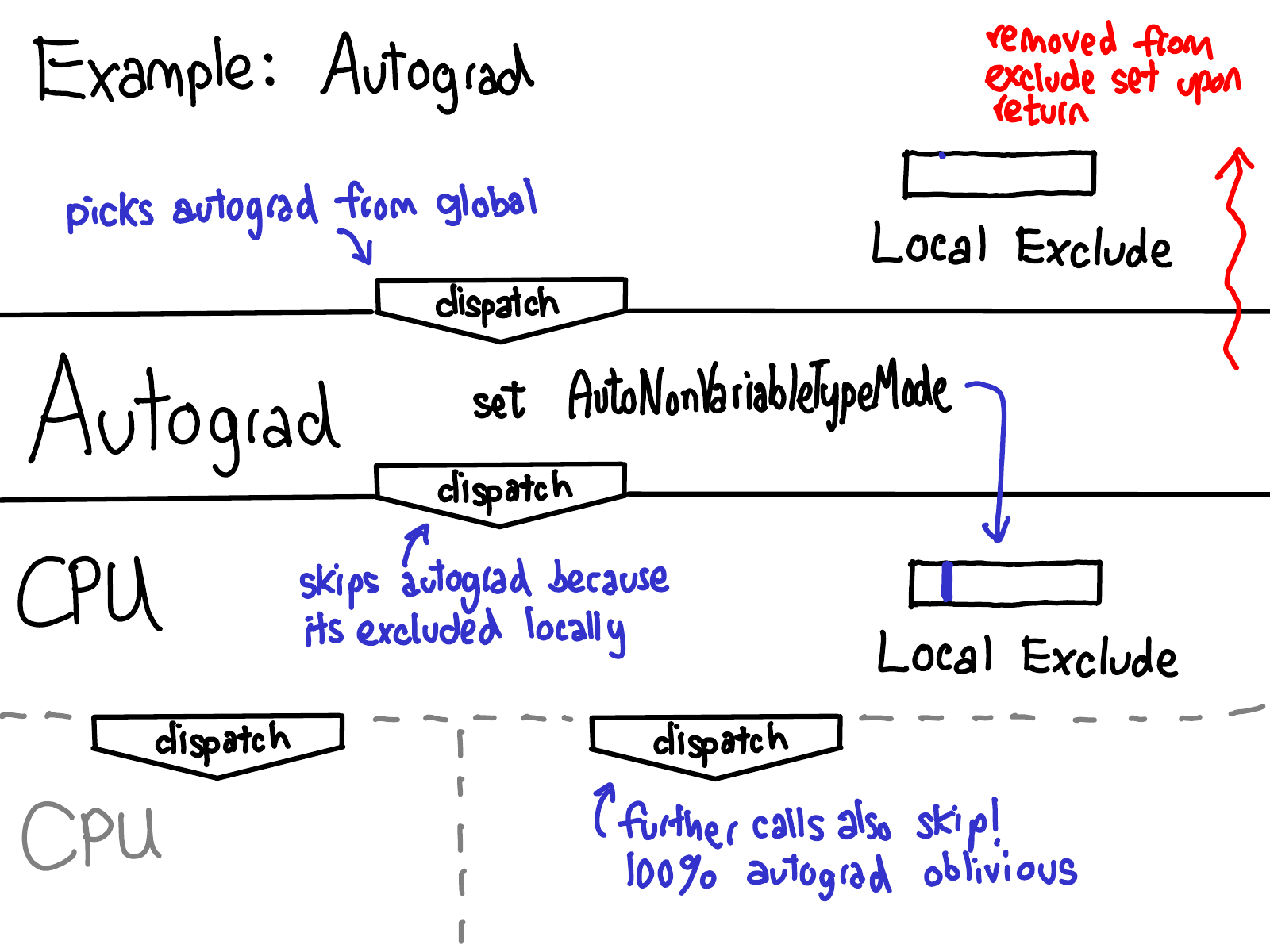
(Warning: This description is out-of-date for PyTorch master. Instead of Autograd being in global, it is instead on the Tensor. Everything else proceeds as before.)
The most canonical example of the dispatch machinery in operation is how it handles autograd. Read the diagram from the top to the bottom. At the very top, Autograd is in the global set, and the local exclude set is empty. When we do dispatch, we find autograd is the highest priority key (it’s higher priority than CPU), and we dispatch to the autograd handler for the operator. Inside the autograd handler, we do some autograd stuff, but more importantly, we create the RAII guard AutoNonVariableTypeMode, which adds Autograd to the local exclude set, preventing autograd from being handled for all of the operations inside of this operator. When we redispatch, we now skip the autograd key (as it is excluded) and dispatch to the next dispatch key, CPU in this example. As local TLS is maintained for the rest of the call tree, all other subsequent dispatches also bypass autograd. Finally, in the end, we return from our function, and the RAII guard removes Autograd from the local exclude set so subsequent operator calls once again trigger autograd handlers.
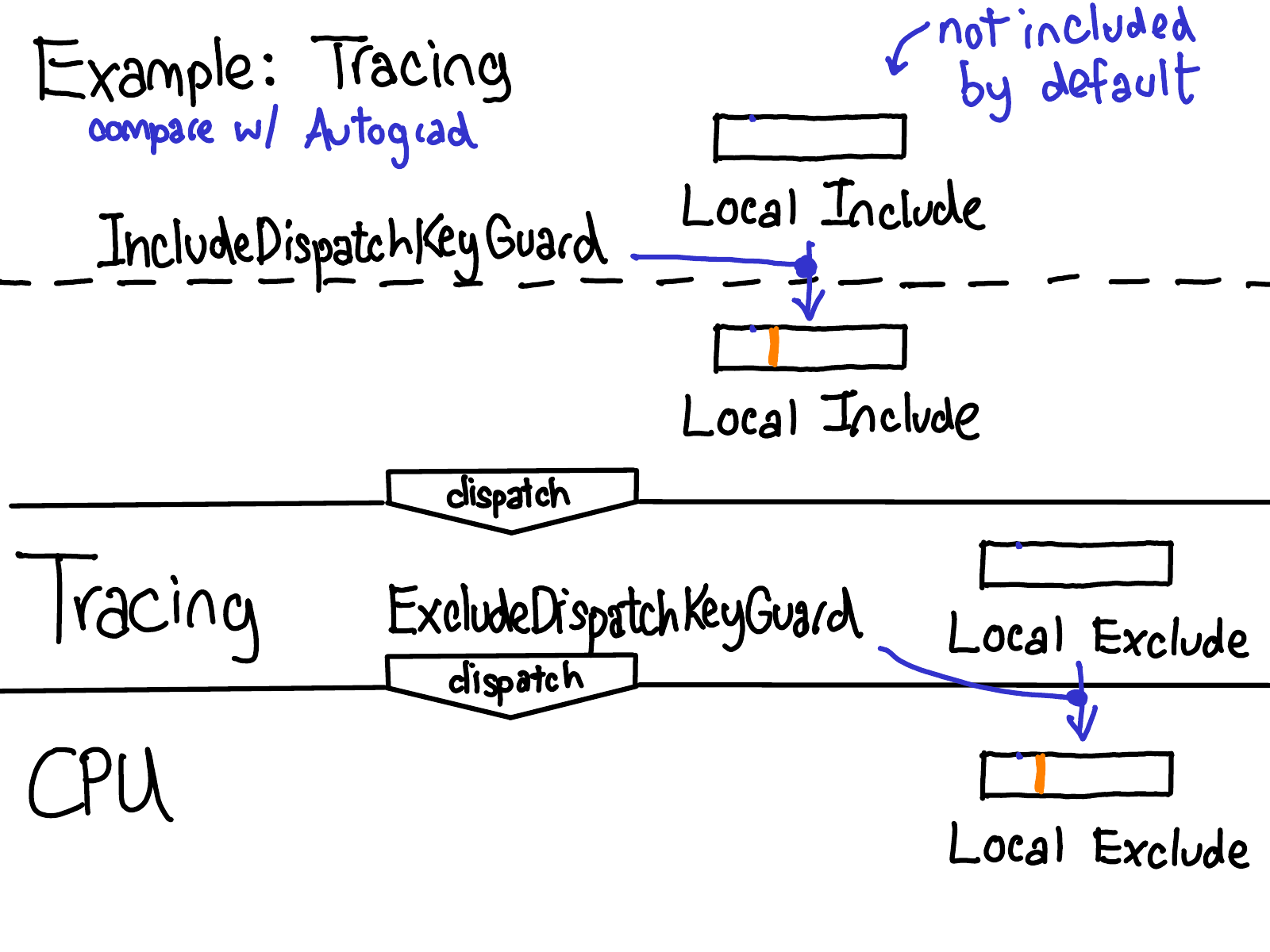
Another similar example is tracing, which is similar to autograd where when we enter the tracing handler, we disable tracing for nested calls with ExcludeDispatchKeyGuard. However, it differs from autograd in how tracing is initially triggered: tracing is toggled by a dispatch key that is added to the local include set when you turn on tracing (with IncludeDispatchKeyGuard), as opposed to the global dispatch key from Autograd (Update: now a dispatch key on tensors).
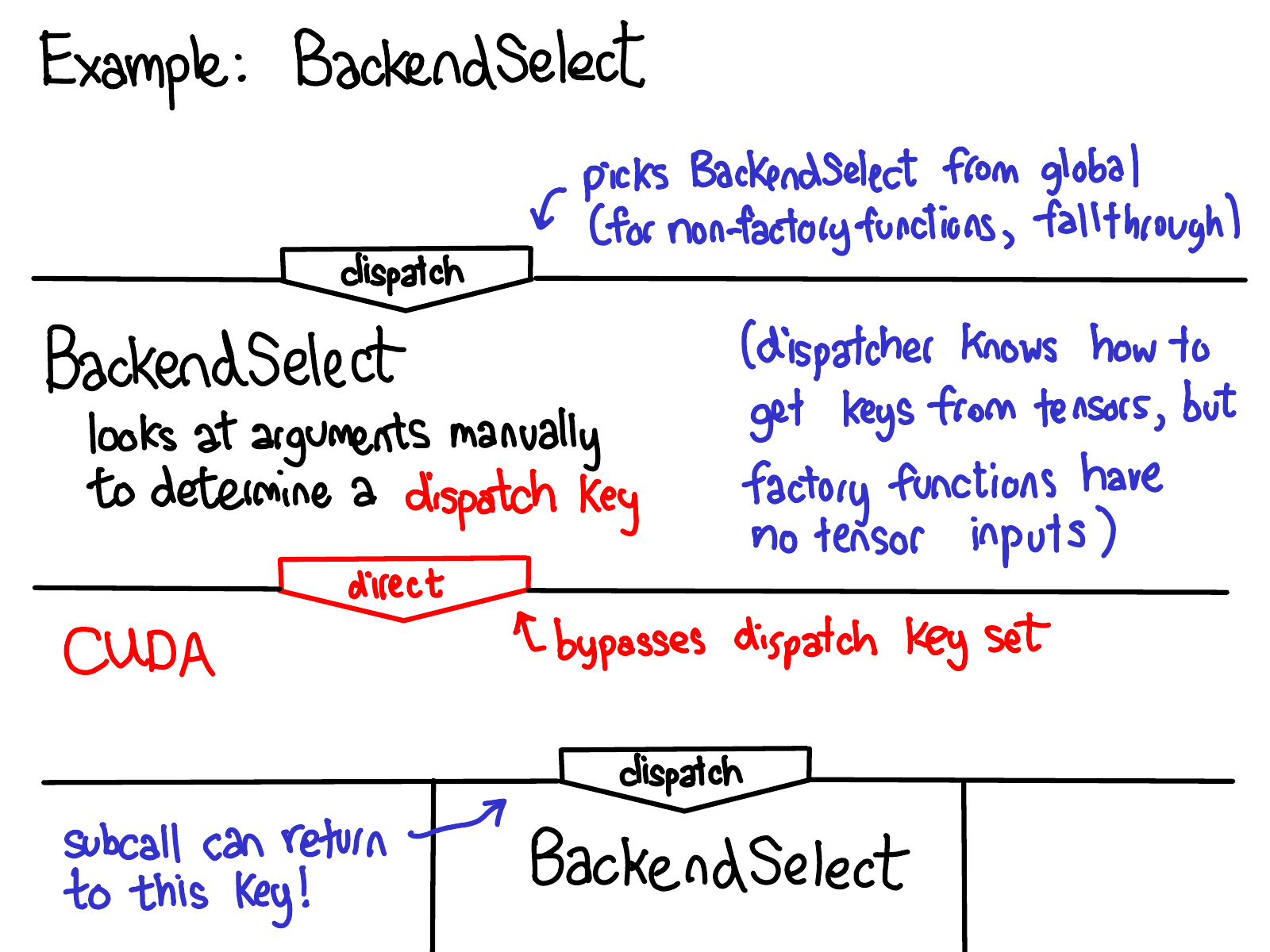
One final example is the BackendSelect key, which operates a little differently from normal keys. The problem backend select solves is that sometimes, the default dispatch key set calculation algorithm doesn’t know how to work out what the correct dispatch key should be. One notable case of this are factory functions, which don’t have any Tensor arguments (and so, naively, would not dispatch to anything). BackendSelect is in the global dispatch key set, but is only registered for a few operators (for the rest, it is a fallthrough key). The BackendSelect handler inspects the arguments and decides what the final dispatch key should be, and then does a direct dispatch to that key, bypassing dispatch key calculation.
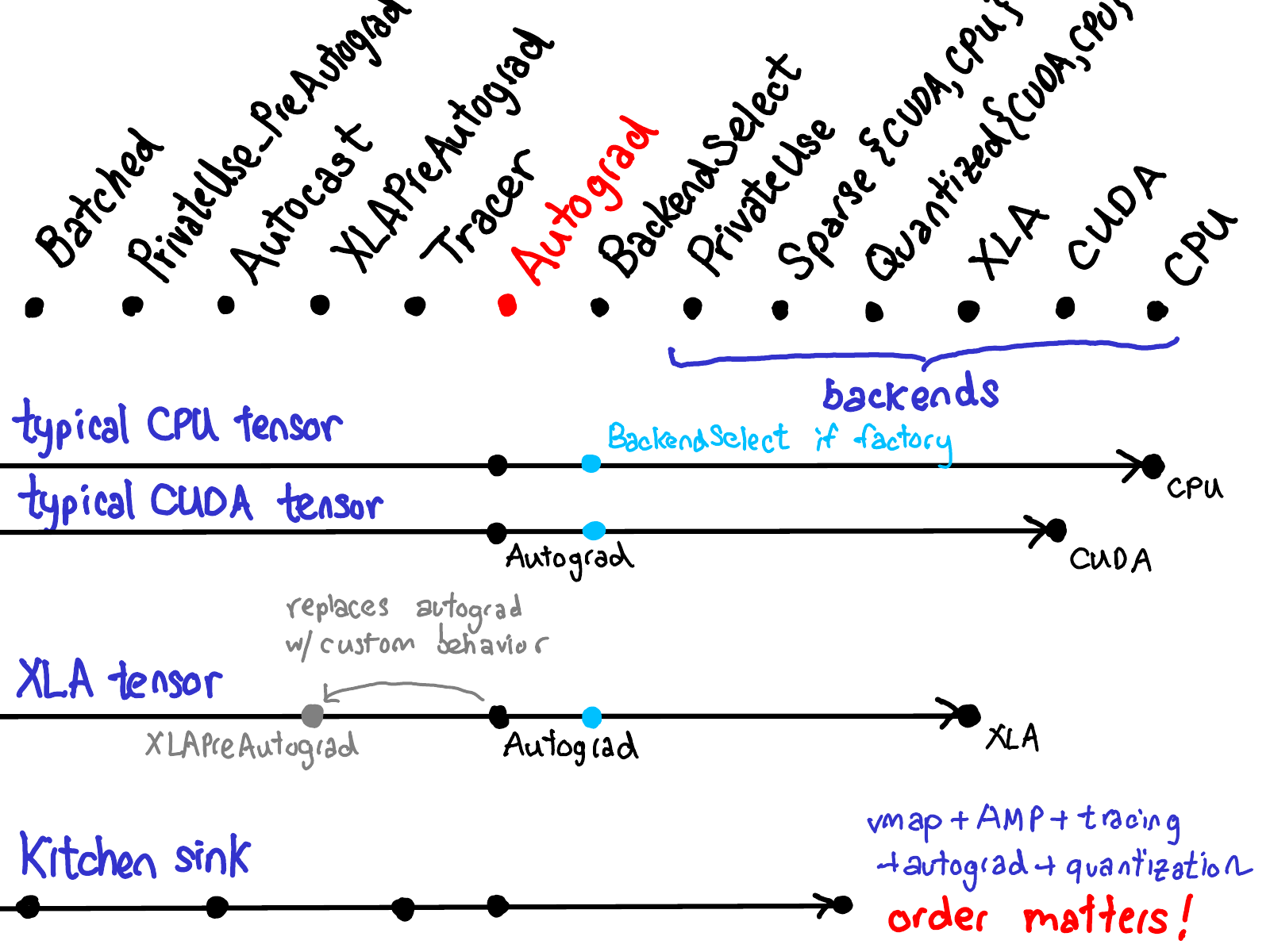
The slide summarizes some of the most common sequences of handlers that get processed when dispatching some operation in PyTorch. Most of the time, it’s autograd, and then the backend (with a backend select in-between if you are a factory function). For XLA, there is also an XLAPreAutograd key (Update: This key is now simply AutogradXLA) which can be used to override the behavior of the Autograd key. And of course, if you turn on every feature in PyTorch all at once, you can end up stopping at a lot of handlers. Notice that the order in which these handlers are processed matters, since handlers aren’t necessarily commutative.
Operator registration¶
So we talked a lot about how we decide what function pointers in the dispatch table to call, but how do these pointers get in the dispatch table in the first place? This is via the operator registration API. If you have never seen this API before, you should take a look at the Dispatcher in C++ tutorial, which describes how the API works at a very high level. In this section, we’ll dive into more detail about how exactly the registration API maps to the dispatch table. Below, you can see the three main ways of interacting with the operator registration API: you define schemas for operators and then register implementations at dispatch keys; finally, there is a fallback method which you can use to define a handler for all operators at some dispatch key.

To visualize the impact of these registration operators, let us imagine that the dispatch tables for all operators collectively form a grid, like this:
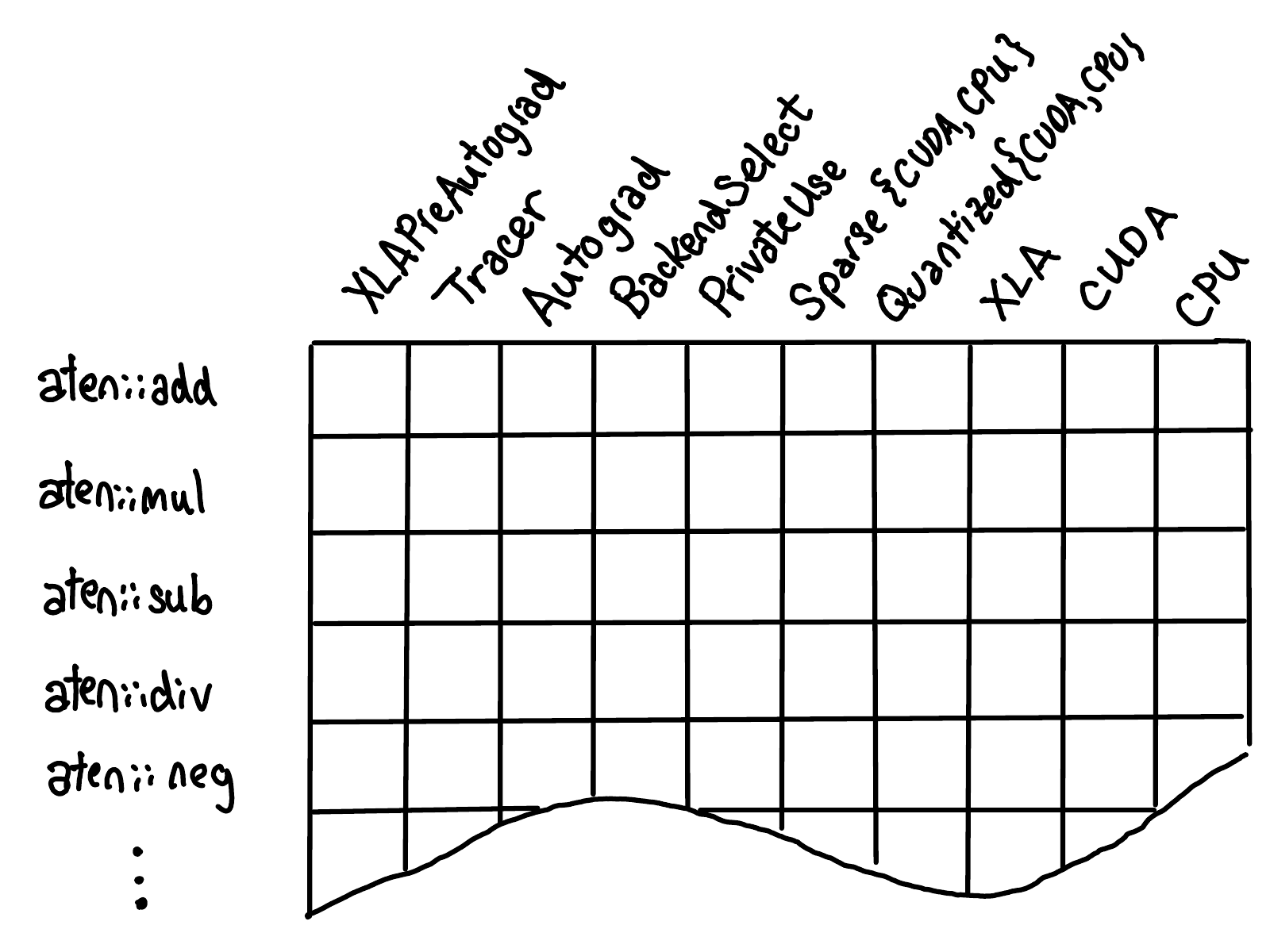
On one axis, we have each operator supported in PyTorch. On the other axis, we have each dispatch key we support in our system. The act of operator registration involves filling in cells with implementations under these two axes.
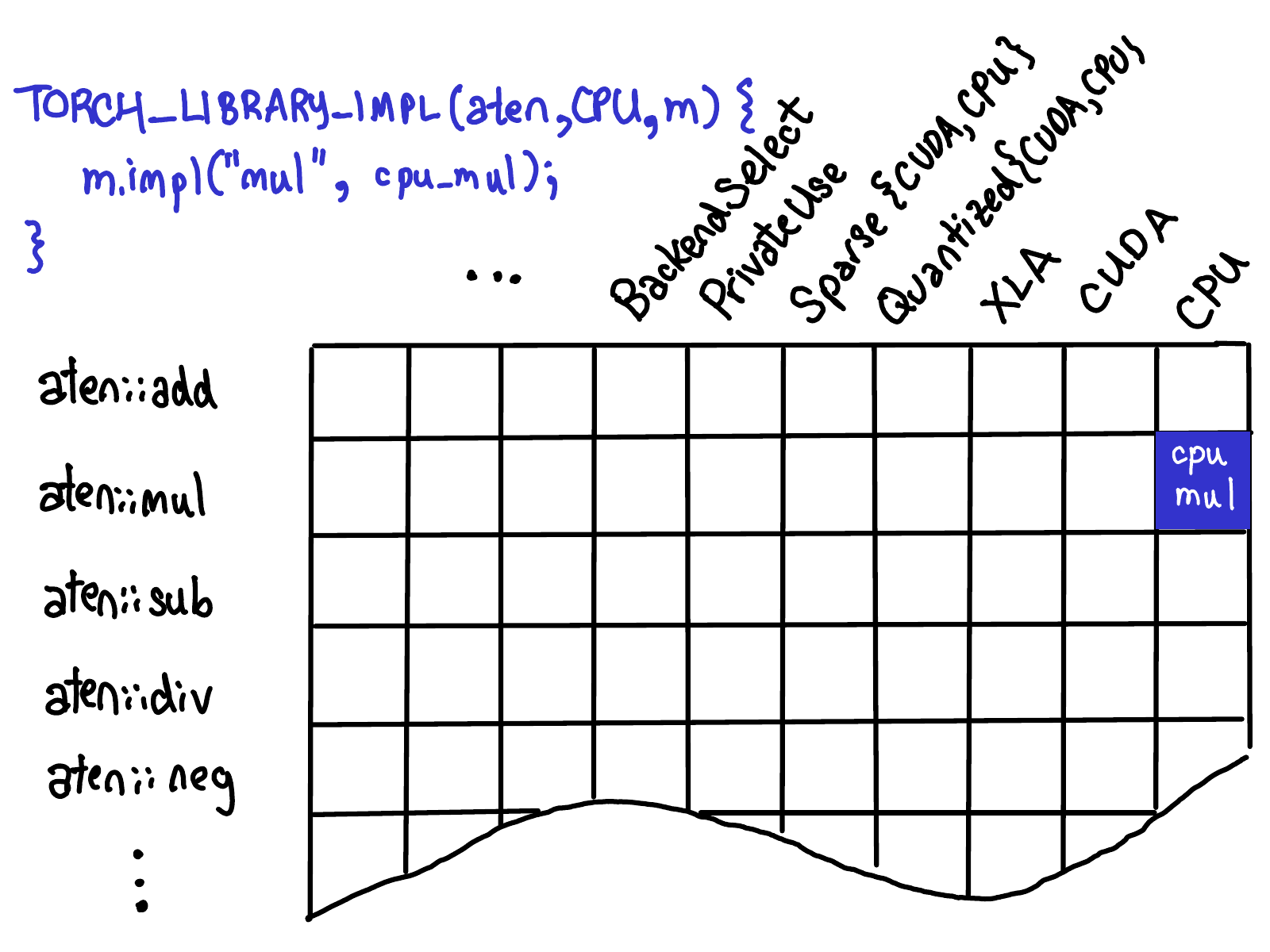
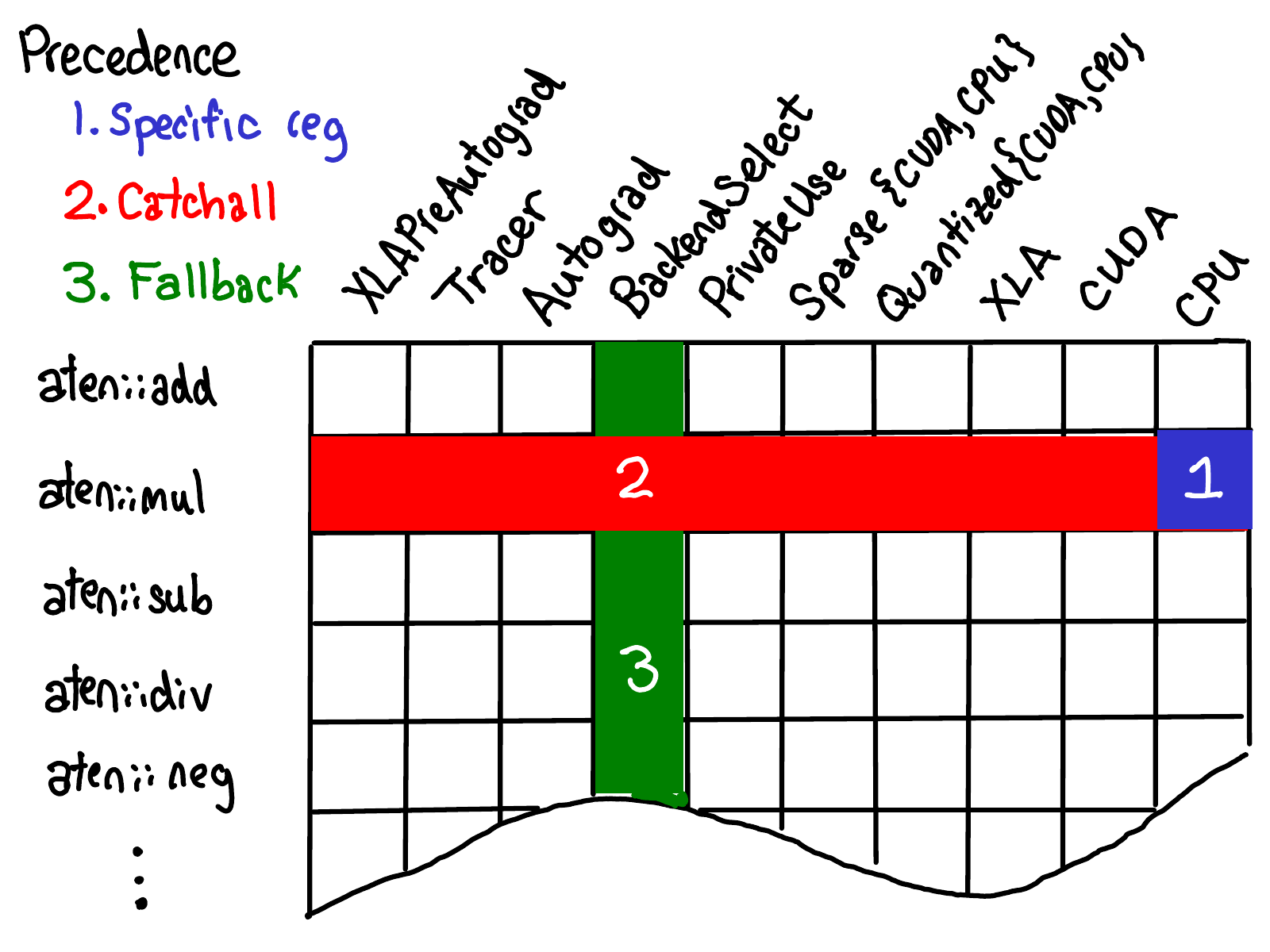
When we register a kernel for a single operator at a specific dispatch key, we fill in a single cell (blue below):
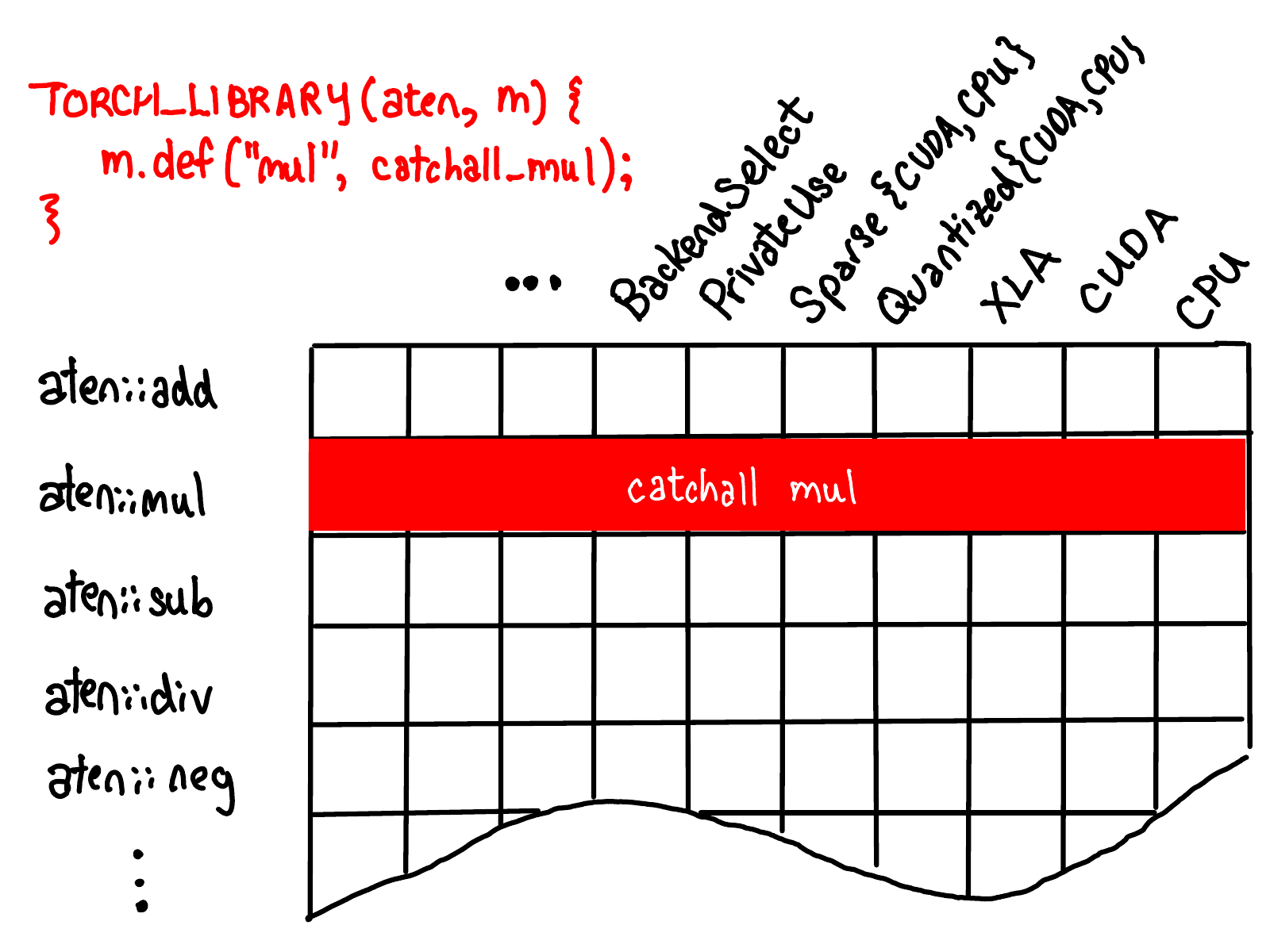
When you register a kernel as a “catch-all” kernel for all dispatch keys in an operator, you fill in an entire row for the operator with one kernel (red below). By the way, if this seems like a strange thing to want to do, it is! And we’re working to remove this capability in favor of more specific fills for a subset of keys.
When you register a kernel as a fallback for kernel for a single dispatch key, you fill in the column for that dispatch key (green).
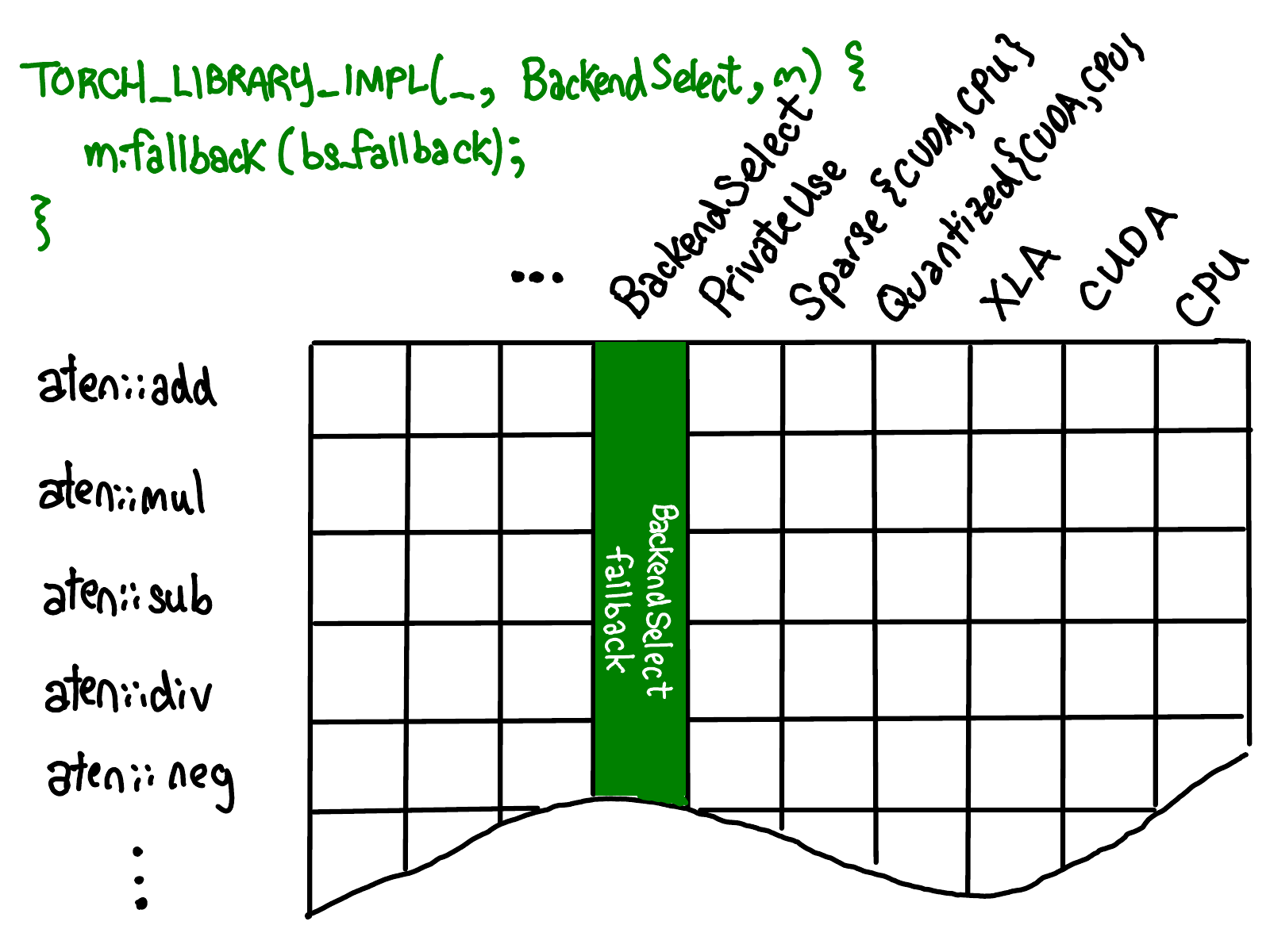
There’s a precedence to these registrations: exact kernel registrations have the highest precedence, and catch all kernels take precedence over fallback.
Boxing and unboxing¶
I want to spend the last part of this post talking about the boxing and unboxing facilities in our dispatcher, which turn out to be pretty important for enabling backend fallback. When you are a programming language designer, there is a classic tradeoff you have to make in deciding whether or not you want to use a boxed or unboxed representation for data:
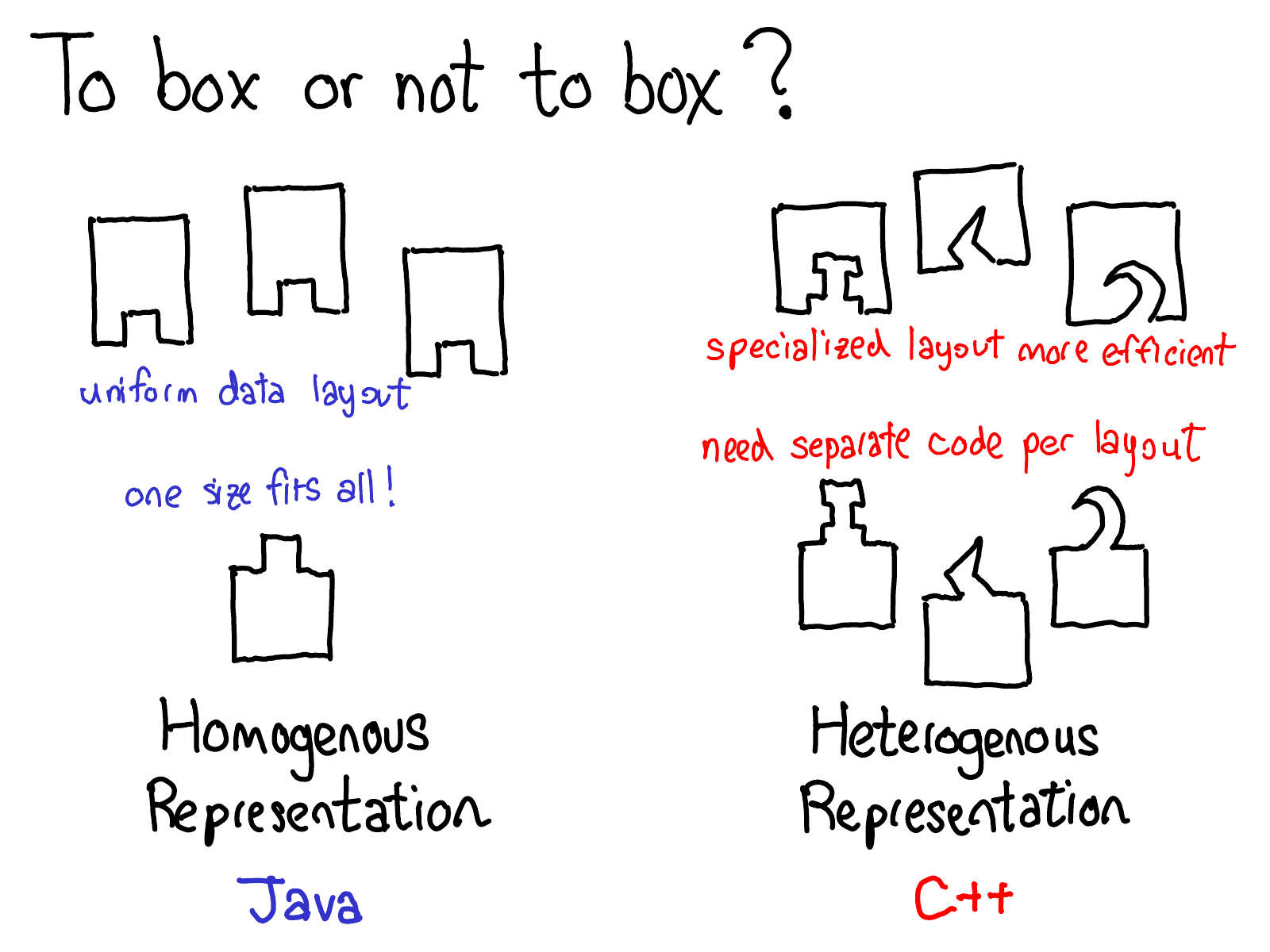
A boxed or homogenous representation is a data representation where every type of object in your system has the same layout. Typically, this means you have some representation that has a header describing what the object in question is, and then some regular payload after it. Homogenous representations are easy to work with in code: because you can always assume that data has some regular layout, you can write functions that work polymorphically over any type of data (think of a function in Java that takes in an arbitrary Object, for example). Most garbage-collected languages have some boxed representation for heap objects, because the garbage collector needs to be able to work over any type of heap object.
In contrast, an unboxed or heterogenous representation allows objects to have a different layout depending on the data in question. This is more efficient than a homogenous representation, as each object can tailor its internal representation to exactly what is needed for the task at hand. However, the downside is we can no longer easily write a single function that works polymorphically over many types of objects. In C++, this problem is worked around using templates: if you need a function to work on multiple types, the C++ compiler will literally create a new copy of the function specialized to each type it is used with.
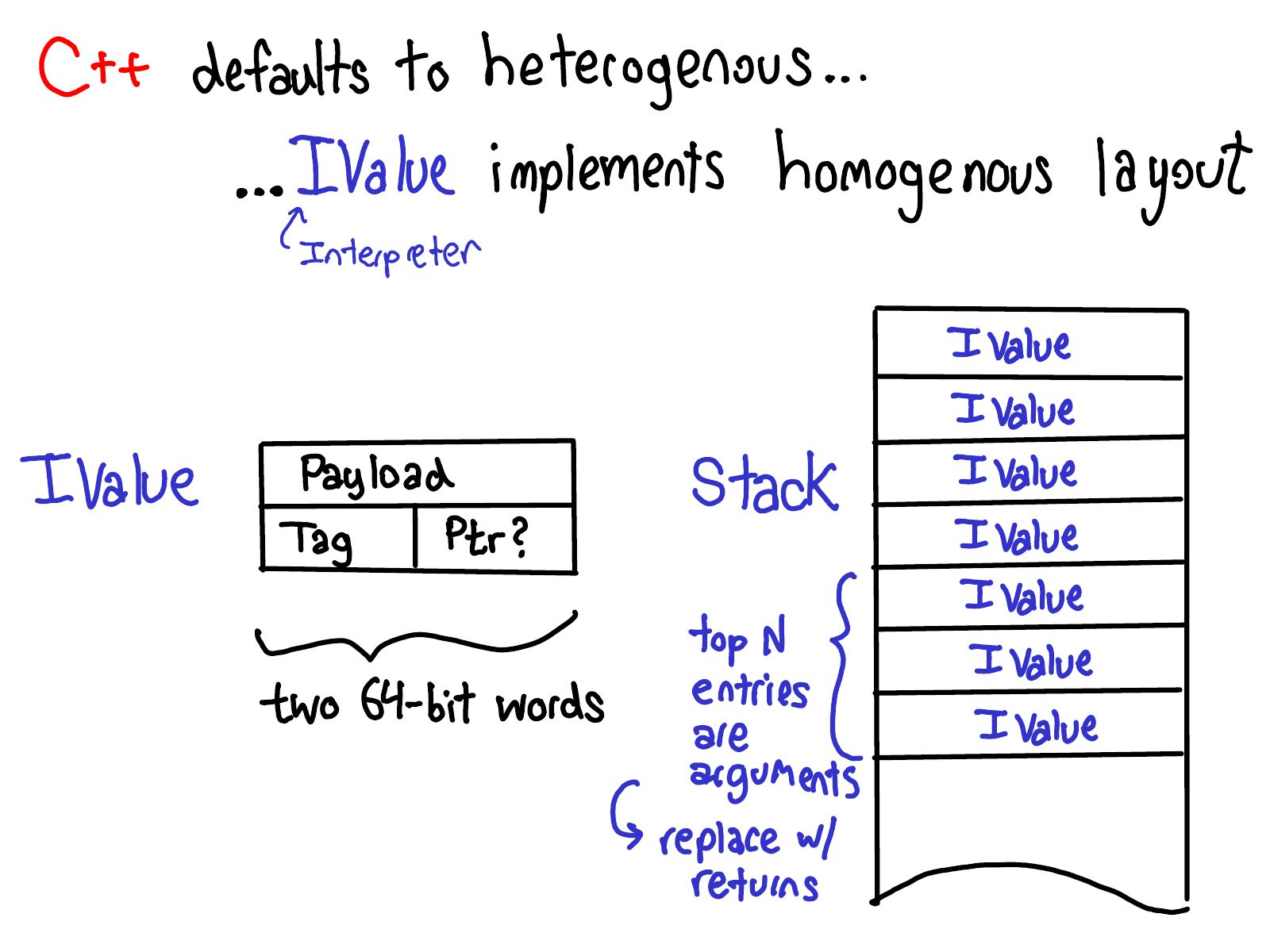
By default, C++ defaults heterogenous layout, but we have implemented homogenous layout in PyTorch by way of the IValue struct (short for interpreter value), which implements a boxed representation that we can use in our interpreter. An IValue is a two word structure consisting of a payload word (usually a pointer, but it could also be an integer or float directly packed into the field) and a tag word which tells us what kind of value the IValue is.
This means we have two calling conventions for functions in PyTorch: the usual, C++, unboxed convention, and a boxed convention using IValues on a stack. Calls (from end users) can come from unboxed API (direct C++ call) or boxed API (from the JIT interpreter); similarly, kernels can be implemented as direct C++ functions (unboxed convention), or can be implemented as a boxed fallback (which by necessity is boxed, as they are polymorphic over all operators).
If I call from boxed API to a boxed fallback, it’s easy to see how to plug the two components together…
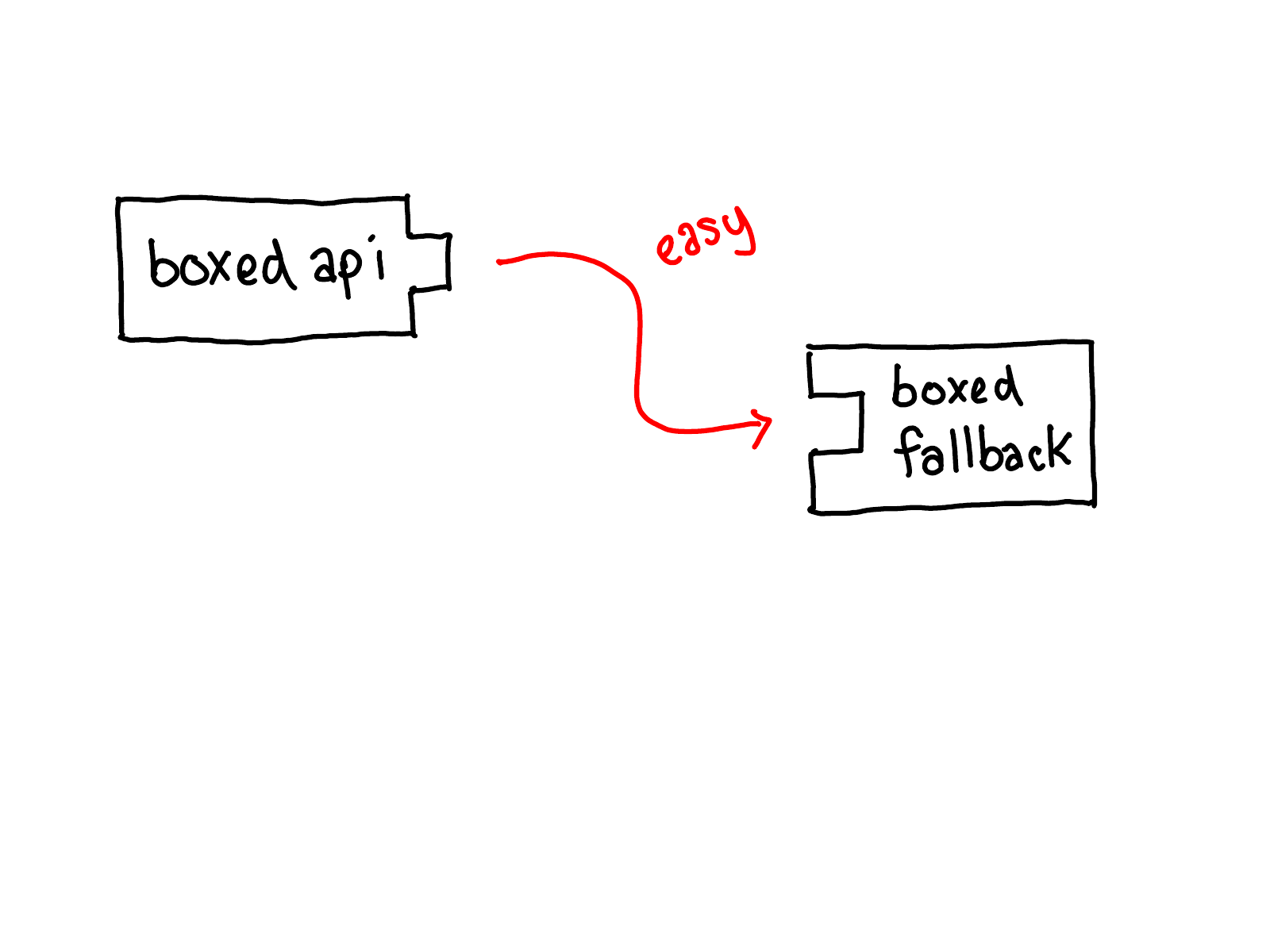
…but how do I get from the unboxed API to the boxed fallback?
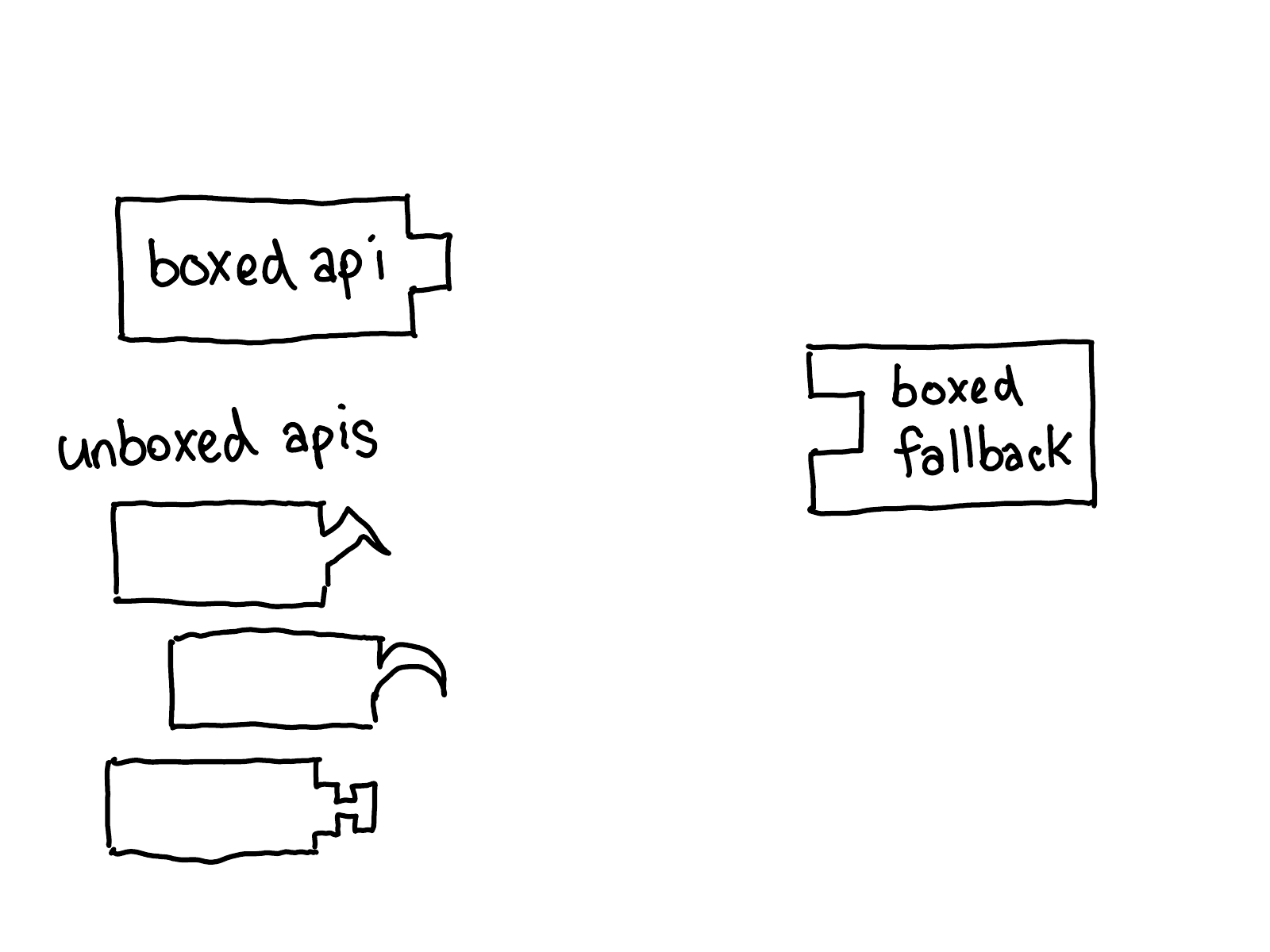
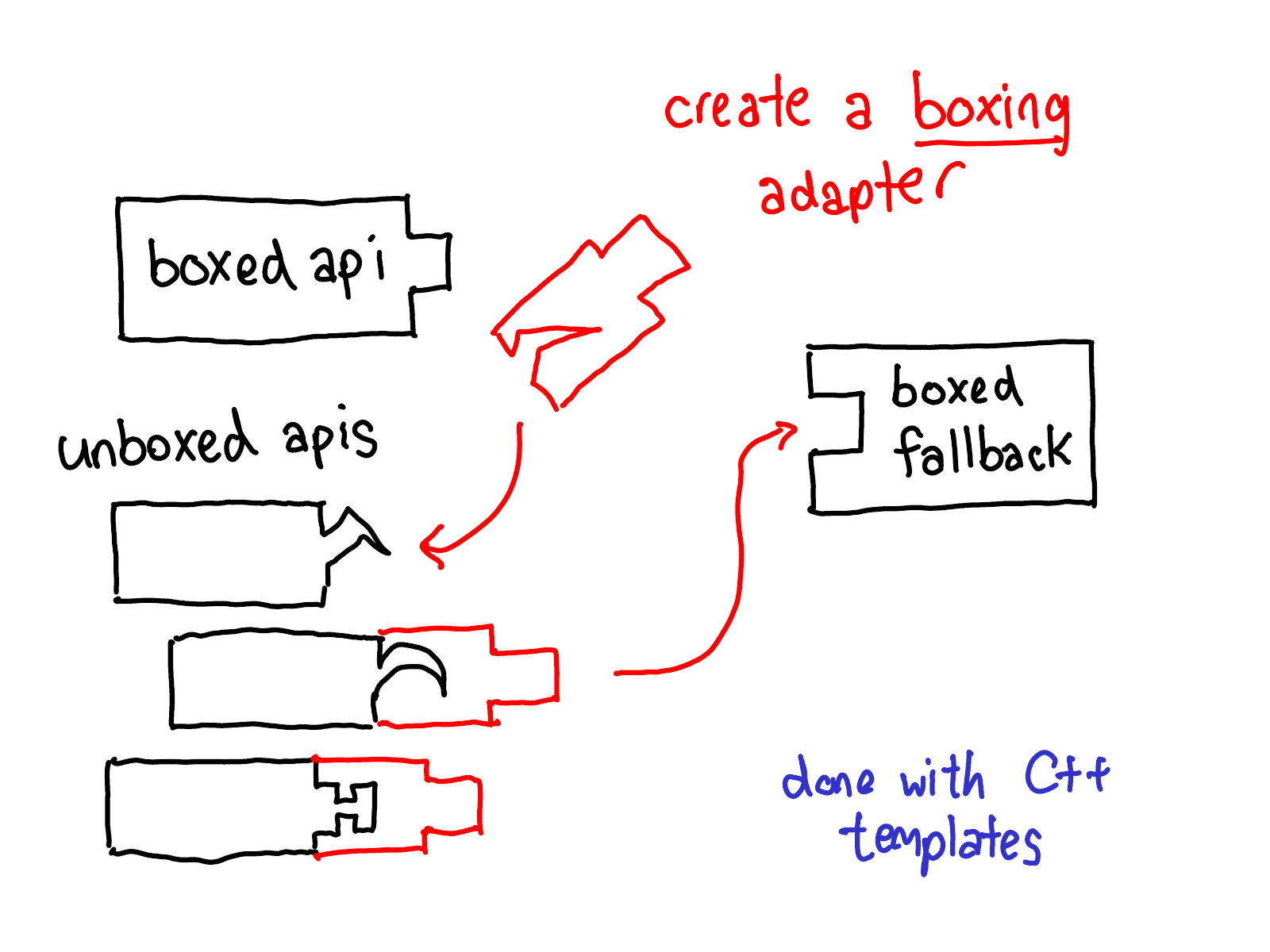
We need some sort of adapter to take the unboxed inputs and turn them into IValues so that they can be passed via the boxed calling convention. This is done via a boxing adapter, which is automatically generated using C++ templates working off of the unboxed C++ types in the outward facing API.
There is also an inverse problem, which is what to do if we have inputs from an boxed API and need to call into an unboxed kernel. Similarly, we have an unboxing adapter, which performs this translation. Unlike the boxing adapter, this adapter is applied to the kernel itself, since C++ templates only work at sites where the unboxed type is statically available (at the boxed API site, these types are not known, so you literally cannot implement this.) Note that we always keep the unboxed API around, so that if a user calls in from the unboxed API, we can fastpath straight to the unboxed kernel.
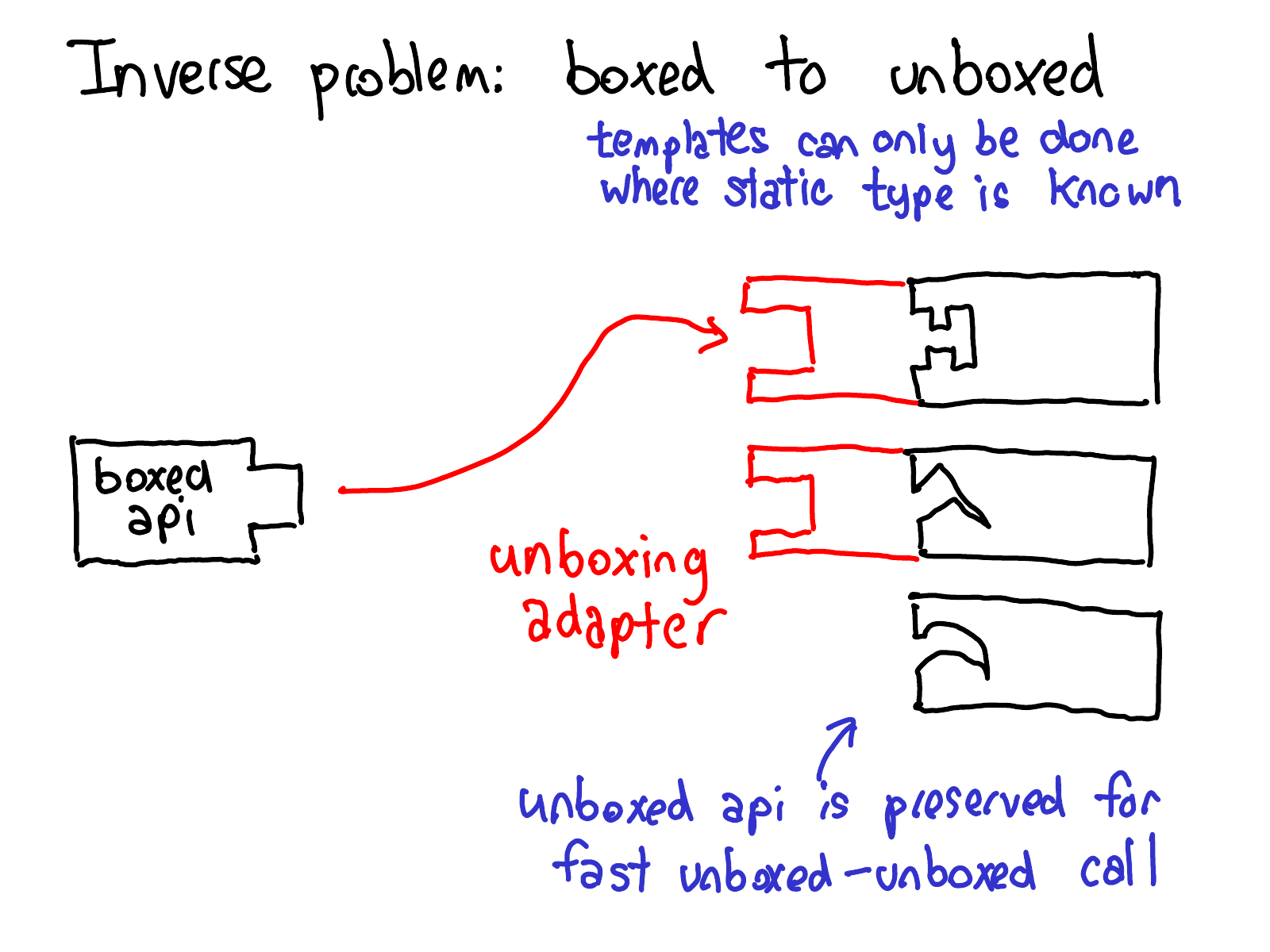
So here is what boxing and unboxing looks overall:
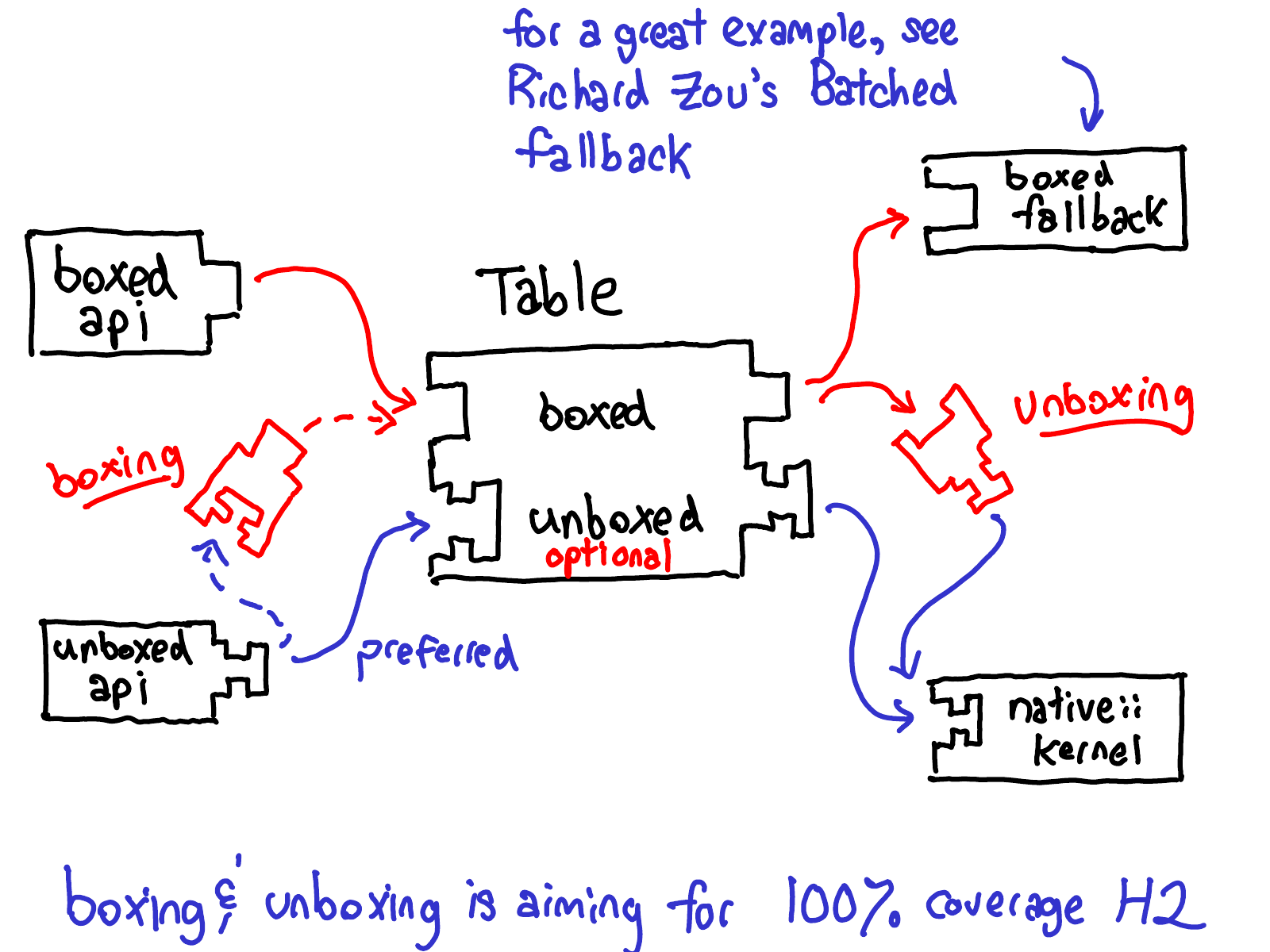
Boxing and unboxing are a key feature in the implementation of boxed fallback: without them, we could not let people write single kernels which would work everywhere (and indeed, in the past, people would write code generators to generate repetitive kernels for every function). With template-based boxing and unboxing, you can write a single boxed kernel, and then have it work for operators, even if those operators are defined externally from the library.
Conclusion¶
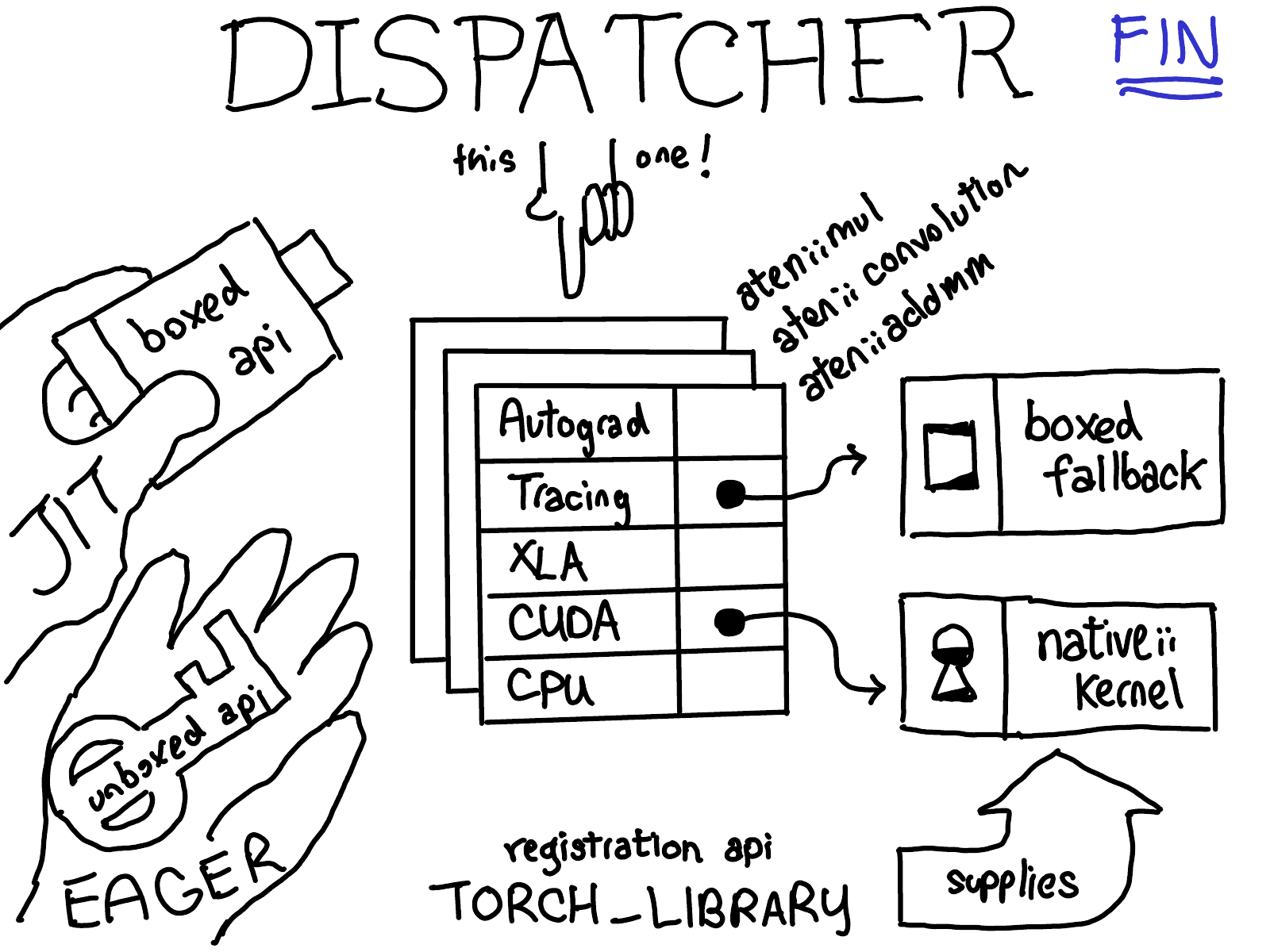
So that’s PyTorch’s dispatcher in a nutshell! The dispatcher is still being continuously worked on; for example, Ailing Zhang recently landed a rework of how autograd dispatch keys are handled, which means that we actually no longer have a single Autograd key but have split autograd keys for AutogradCPU/AutogradCUDA/… We’re generally interested in improving the user experience for people who register kernels to the dispatcher. Let us know if you have any questions or comments!
Small typo here:
> This is done via a boxing adapter, which is automatically generate using C++ templates working off of the unboxed C++ types in the outward facing API.
generateD maybe?
Edward: Thanks anonymous, fixed!
Anonymous: Their articles on jaxprs (https://jax.readthedocs.io/en/latest/jaxpr.html) and interpreters (https://jax.readthedocs.io/en/latest/notebooks/Writing_custom_interpreters_in_Jax.html) are well written and are serve a similar role to our dispatcher. I recommend taking a look at those.
Bob Liao: They’re done in Xournal; see http://blog.ezyang.com/2010/04/diagramming-in-xournal-and-gimp/
Ed: IIUC those docs might not be the best connection to draw. The most analogous part of JAX doesn’t have to do with jaxprs, since most transformations (like jvp and vmap) overload eager dispatch and don’t form jaxprs at all. The interpreter to which JAX dispatches as the user’s Python code is executed is controlled by Primitive.bind and find_top_trace in jax/core.py. The fact that JAX transforms as it traces, rather than first forming a jaxpr up front, is how differentiation of control flow works, and how one can print- or pdb-debug to inspect vmapped values. For pedagogical purposes, and to make users adding their own transformations easier, we’ve only documented the jaxpr-interpreter version though. It’s simpler!
There are probably interesting connections to draw between the PyTorch dispatcher and how JAX overloads primitive application.
Hi Anonymous.
We actually fixed this later; now dispatch keys are formed by combining functionality bit (quantization, sparse, etc) with backend bit (CPU, CUDA, etc). So it now indeed works the way you want it to :)