In today’s post, we focus on you, the unwitting person rooting around the Haskell heap to open a present. After all, presents in the Haskell heap do not spontaneously unwrap themselves.

Someone has to open the first present.

If the Haskell heap doesn’t interact with the outside world, no presents need to be opened: thus IO functions are the ones that will open presents. What presents they will open is not necessarily obvious for many functions, so we’ll focus on one function that makes it particularly obvious: evaluate. Which tells you to…
Read more...

The Ghost of the Christmas Present
In today’s post, we’ll do a brief survey of the various things that can happen when you open haunted presents in the Haskell heap. Asides from constants and things that have already been evaluated, mostly everything on the Haskell heap is haunted. The real question is what the ghost haunting the present does.
In the simplest case, almost nothing!
Read more...

The Haskell heap is a rather strange place. It’s not like the heap of a traditional, strictly evaluated language…

…which contains a lot of junk! (Plain old data.)
In the Haskell heap, every item is wrapped up nicely in a box: the Haskell heap is a heap of presents (thunks).
When you actually want what’s inside the present, you open it up (evaluate it).

Presents tend to have names, and sometimes when you open a present, you get a gift card (data constructor). Gift cards have two traits: they have a name (the Just gift card or the Right gift card), and they tell you where the rest of your presents are. There might be more than one (the tuple gift card), if you’re a lucky duck!
Read more...
What is the Mailbox? It’s a selection of interesting email conversations from my mailbox, which I can use in place of writing original content when I’m feeling lazy. I got the idea from Matt Might, who has a set of wonderful suggestions for low-cost academic blogging.
From: Brent Yorgey
I see you are a contributor to the sup mail client. At least I assume it is you, I doubt there are too many Edward Z. Yangs in the world. =) I’m thinking of switching from mutt. Do you still use sup? Any thoughts/encouragements/cautions to share?
Read more...
It is often said that the factorial function is the “Hello World!” of the functional programming language world. Indeed, factorial is a singularly useful way of testing the pattern matching and recursive facilities of FP languages: we don’t bother with such “petty” concerns as input-output. In this blog post, we’re going to trace the compilation of factorial through the bowels of GHC. You’ll learn how to read Core, STG and Cmm, and hopefully get a taste of what is involved in the compilation of functional programs. Those who would like to play along with the GHC sources can check out the description of the compilation of one module on the GHC wiki. We won’t compile with optimizations to keep things simple; perhaps an optimized factorial will be the topic of another post!
Read more...
I was supposed to have another post about Hoopl today, but it got scuttled when an example program I had written triggered what I think is a bug in Hoopl (if it’s not a bug, then my mental model of how Hoopl works internally is seriously wrong, and I ought not write about it anyway.) So today’s post will be about the alleged bug Hoopl was a victim of: bugs from using the wrong variable.
Read more...
Once you’ve determined what dataflow facts you will be collecting, the next step is to write the transfer function that actually performs this analysis for you!
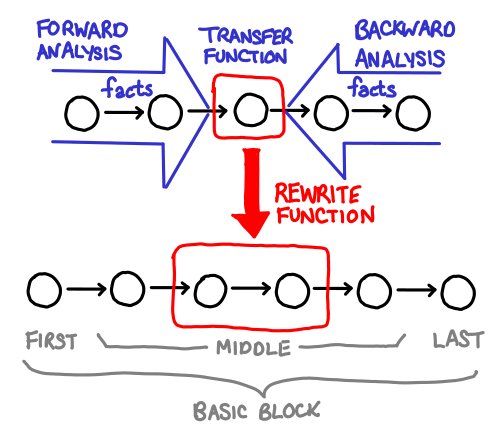
Remember what your dataflow facts mean, and this step should be relatively easy: writing a transfer function usually involves going through every possible statement in your language and thinking about how it changes your state. We’ll walk through the transfer functions for constant propagation and liveness analysis.
Read more...
The imperative. When should you create a custom data type, as opposed to reusing pre-existing data types such as Either, Maybe or tuples? Here are some reasons you should reuse a generic type:
- It saves typing (both in declaration and in pattern matching), making it good for one-off affairs,
- It gives you a library of predefined functions that work with that type,
- Other developers have expectations about what the type does that make understanding quicker.
On the flip side of the coin:
Read more...
The essence of dataflow optimization is analysis and transformation, and it should come as no surprise that once you’ve defined your intermediate representation, the majority of your work with Hoopl will involve defining analysis and transformations on your graph of basic blocks. Analysis itself can be further divided into the specification of the dataflow facts that we are computing, and how we derive these dataflow facts during analysis. In part 2 of this series on Hoopl, we look at the fundamental structure backing analysis: the dataflow lattice. We discuss the theoretical reasons behind using a lattice and give examples of lattices you may define for optimizations such as constant propagation and liveness analysis.
Read more...
Hoopl is a higher-order optimization library. We think it’s pretty cool! This series of blog post is meant to give a tutorial-like introduction to this library, supplementing the papers and the source code. I hope this series will also have something for people who aren’t interested in writing optimization passes with Hoopl, but are interested in the design of higher-order APIs in Haskell. By the end of this tutorial, you will be able to understand references in code to names such as analyzeAndRewriteFwd and DataflowLattice, and make decode such type signatures as:
Read more...