Optimizing incremental compilation
When you run make to build software, you expect a build on software that has been previously built to take less time than software we are building from scratch. The reason for this is incremental compilation: by caching the intermediate results of ahead-of-time compilation, the only parts of a program that must be recompiled are those that depend on the changed portions of the dependency graph.
The term incremental compilation doesn't say much about how the dependency graph is set up, which can lead to some confusion about the performance characteristics of "incremental compilers." For example, the Wikipedia article on incremental compilation claims that incremental compilers cannot easily optimize the code that it compiles. This is wrong: it depends entirely on how your dependency graph is set up.
Take, for example, gcc for C:
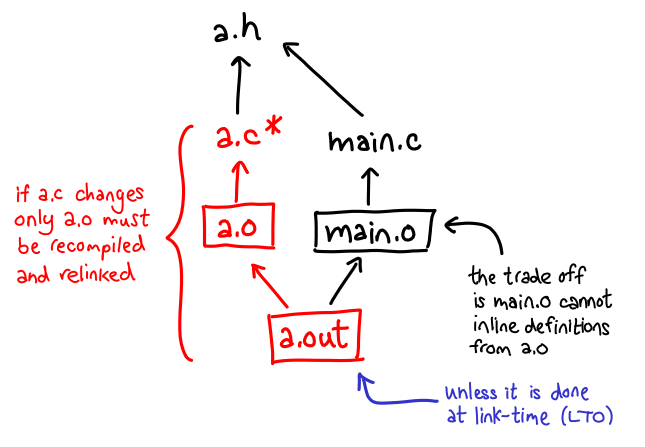
The object file a.o depends on a.c, as well as any header files it (transitively) includes (a.h, in this case.) Since a.o and main.o do not depend on each other, if a.c is rebuilt, main.o does not need to rebuilt. In this sense, C is actually amazingly incremental (said no C programmer ever.) The reason C has a bad reputation for incremental compilation is that, naively, the preprocessing of headers is not done incrementally at all (precompiled headers are an attempt to address this problem).
The dependency graph implies something else as well: unless the body of a function is placed in a.h, there is no way for the compiler that produces main.o to inline the body in: it knows nothing about the C file. a.c may not even exist at the point main.o is being built (parallelism!) The only time such optimization could happen is at link-time (this is why link-time optimization is a thing.)
A nice contrast is ghc for Haskell:
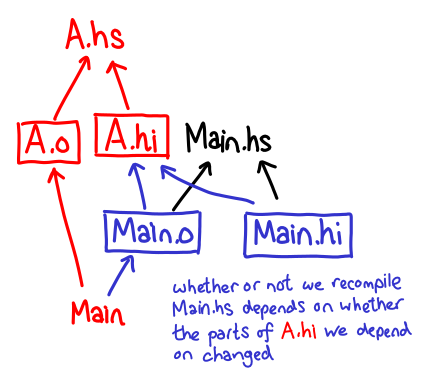
Here, Main.{hi,o} depend not only on Main.hs but A.hi, the module it imports. GHC is still incremental: if you modify an hs file, only things that import that source file that need to be recompiled. Things are even better than this dependency diagram implies: Main.{hi,o} may only depend on specific pieces of A.hi; if those pieces are unchanged GHC will exit early and report compilation is NOT necessary.
Despite being incremental, GHC supports inlining, since unfoldings of functions can be stored in hi files, which can subsequently be used by modules which import it. But now there is a trade-off: if you inline a function, you now depend on the unfolding in the hi file, making it more likely that compilation is necessary when A.hi changes.
As one final example, incremental compilers in IDEs, like the Java compiler in Eclipse, are not doing anything fundamentally different than the operation of GHC. The primary differences are (1) the intermediate products are held in memory, which can result in huge savings since parsing and loading interfaces into memory is a huge timewaster, and (2) they try to make the dependency diagram as fine-grained as possible.
This is all fairly well known, so I want to shift gears and think about a less well-understood problem: how does one do incremental compilation for parametrized build products? When I say parametrized, I mean a blend of the C and Haskell paradigms:
- Separate compilation. It should be possible to depend on an interface without depending on an implementation (like when a C file depends on a header file.)
- Cost-free abstraction. When the implementation is provided, we should (re)compile our module so that we can inline definitions from the implementation (like when a Haskell module imports another module.)
This problem is of interest for Backpack, which introduces libraries parametrized over signatures to Haskell. For Backpack, we came up with the following design: generate distinct build products for (1) uninstantiated code, for which we know an interface but not its implementation, and (2) instantiated code, for which we know all of their implementations:
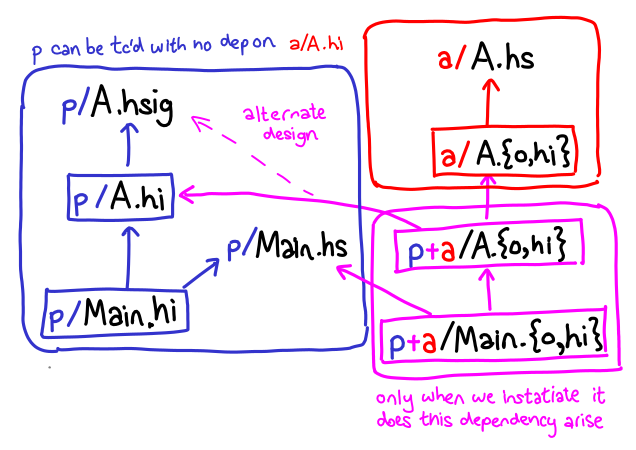
In the blue box, we generate A.hi and Main.hi which contain purely the results of typechecking against an interface. Only in the pink box do we combine the implementation of A (in the red box) with the user of A (Main). This is just a graph; thus, incremental compilation works just as it works before.
We quickly ran into an intriguing problem when we sought to support multiple interfaces, which could be instantiated separately: if a client instantiates one interface but not the other, what should we do? Are we obligated to generate build products for these partially instantiated modules? This is not very useful, since we can't generate code yet (since we don't know all of the implementations.)
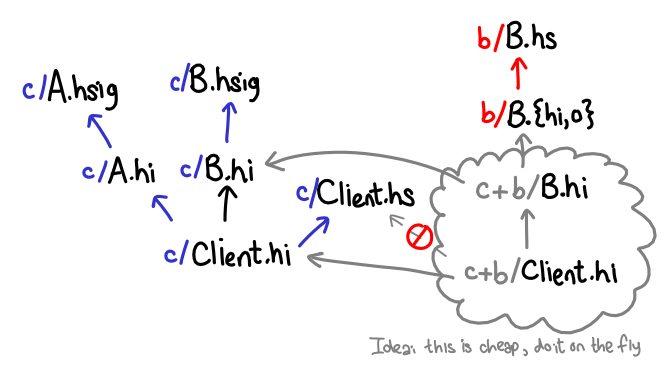
An important observation is that these interfaces are really cheap to generate (since you're not doing any compilation). Thus, our idea was to do the instantiation on-the-fly, without actually generating build products. The partially instantiated interfaces can be cached in memory, but they're cheap to generate, and we win if we don't need them (in which case we don't instantiate them.)
This is a bit of a clever scheme, and cleverness always has a dark side. A major source of complexity with on-the-fly instantiation is that there are now two representations of what is morally the same build product: the on-the-fly products and the actually compiled ones:
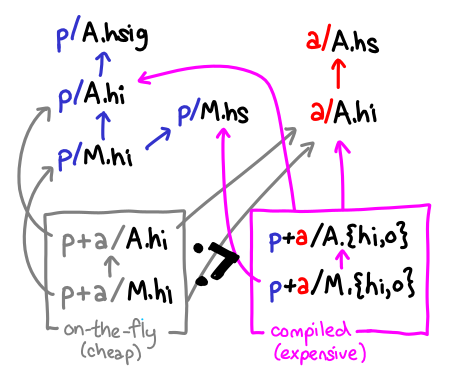
The subtyping relation between these two products states that we can always use a compiled interface in place of an on-the-fly instantiated one, but not vice versa: the on-the-fly interface is missing unfoldings and other important information that compiled code may need.
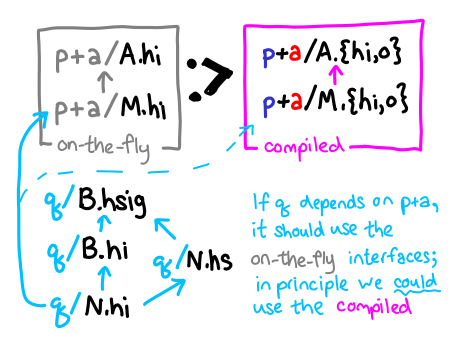
If we are type-checking only (we have uninstantiated interfaces), we might prefer on-the-fly interfaces, because they require less work to create:
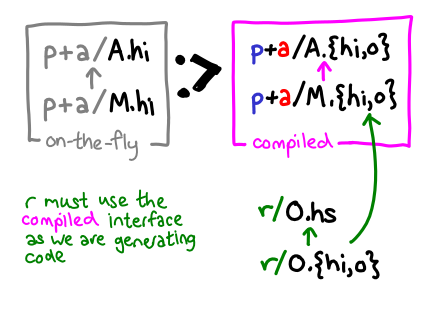
In contrast, if we are compiling a package, we must use the compiled interface, to ensure we see the necessary unfoldings for inlining:
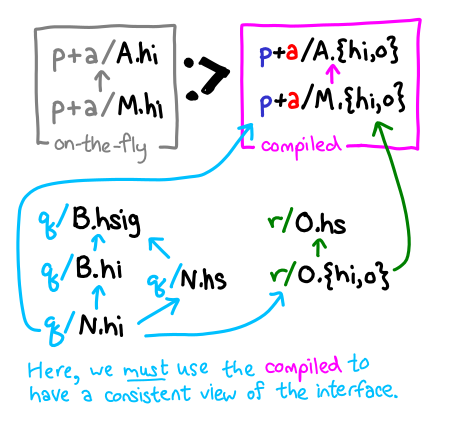
A particularly complicated case is if we are type-checking an uninstantiated set of modules, which themselves depend on some compiled interfaces. If we are using an interface p+a/M.hi, we should be consistent about it, and since r must use the compiled interfaces, so must q:
The alternative is to ensure that we always build products available that were typechecked against the on-the-fly interfaces, as below:
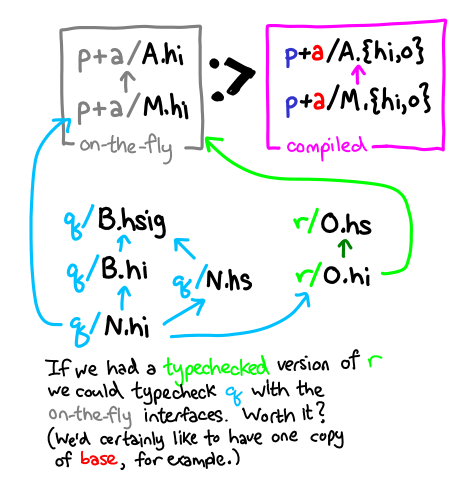
But this has the distasteful effect of requiring everything to be built twice (first typechecked against the on-the-fly interfaces, and then built for real).
The dependency graphs of build products for an ahead-of-time compiler is traditionally part of the public API of a compiler. As I've written previously, to achieve better incrementality, better parallelism, and more features (like parametrized modules), dependency graphs become more and more complicated. When compiler writers don't want to commit to an interface and build tool authors aren't interested learning about a complicated compilation model, the only systems that work well are the integrated ones.
Is Backpack's system for on-the-fly interface instantiation too clever for its own good? I believe it is well-designed for the problem it tries to solve, but if you still have a complicated design, perhaps you are solving the wrong problem. I would love to hear your thoughts.