So you want to add a new concurrency primitive to GHC...
January 1, 2014One of the appealing things about GHC is that the compiler is surprisingly hackable, even when you don’t want to patch the compiler itself. This hackability comes from compiler plugins, which let you write custom optimization passes on Core, as well as foreign primops, which let you embed low-level C– to manipulate the low-level representation of various primitives. These hooks let people implement and distribute features that would otherwise be to unstable or speculative to put into the compiler proper.
A particular use-case that has garnered some amount of interest recently is that of concurrency primitives. We engineers like to joke that, in the name of performance, we are willing to take on nearly unbounded levels of complexity: but this is almost certainly true when it comes to concurrency primitives, where the use of ever more exotic memory barriers and concurrent data structures can lead to significant performance boosts (just ask the Linux kernel developers). It’s very tempting to look at this situation and think, “Hey, we could implement this stuff in GHC too, using the provided compiler hooks!” But there are a lot of caveats involved here.
After answering a few questions related to this subject on the ghc-devs list and noticing that many of the other responses were a bit garbled, I figured I ought to expand on my responses a bit in a proper blog post. I want to answer the following questions:
- What does it mean to have a memory model for a high-level language like Haskell? (You can safely skip this section if you know what a memory model is.)
- What is (GHC) Haskell’s memory model?
- How would I go about implementing a (fast) memory barrier in GHC Haskell?
Memory models are semantics¶
What is a memory model? If you ask a hardware person, they might tell you, “A memory model is a description of how a multi-processor CPU interacts with its memory, e.g. under what circumstances a write by one processor is guaranteed to be visible by another.” If you ask a compiler person, they might tell you, “A memory model says what kind of compiler optimizations I’m allowed to do on operations which modify shared variables.” A memory model must fulfill both purposes (a common misconception is that it is only one or the other). To be explicit, we define a memory model as follows (adapted from Adve-Boehm):
A memory model is a semantics for shared variables, i.e. the set of values that a read in a program is allowed to return.
That’s right: a memory model defines the behavior of one the most basic operations in your programming language. Without it, you can’t really say what your program is supposed to do.
Why, then, are memory models so rarely discussed, even in a language community that is so crazy about semantics? In the absence of concurrency, the memory model is irrelevant: the obvious semantics apply. In the absence of data races, the memory model can be described quite simply. For example, a Haskell program which utilizes only MVars for inter-thread communication can have its behavior described completely using a relatively simple nondeterministic operational semantics (see Concurrent Haskell paper (PS)); software transactional memory offers high-level guarantees of atomicity with respect to reads of transactional variables. Where a memory model becomes essential is when programs contain data races: when you have multiple threads writing and reading IORefs without any synchronization, a memory model is responsible for defining the behavior of this program. With modern processors, this behavior can be quite complex: we refer to these models as relaxed memory models. Sophisticated synchronization primitives will often take advantage of a relaxed memory model to avoid expensive synchronizations and squeeze out extra performance.
GHC Haskell’s memory (non) model¶
One might say the Haskell tradition is one that emphasizes the importance of semantics… except for a number of notable blind spots. The memory model is one of those blind spots. The original Haskell98 specification did not contain any specification of concurrency. Concurrent Haskell paper (PS) gave a description of semantics for how concurrency might be added to the language, but the paper posits only the existence of MVars, and is silent on how MVars ought to interact with IORefs.
One of the very first discussions that took place on the haskell-prime committee when it was inaugurated in 2006 was whether or not Concurrent Haskell should be standardized. In the discussion, it was quickly discovered that a memory model for IORefs would be needed (continued here). As of writing, no decision has been made as to whether or not IORefs should have a strong or weak memory model.
The upshot is that, as far as Haskell the standardized language goes, the behavior here is completely undefined. To really be able to say anything, we’ll have to pick an implementation (GHC Haskell), and we’ll have to infer which aspects of the implementation are specified behavior, as opposed to things that just accidentally happen to hold. Notably, memory models have implications for all levels of your stack (it is a common misconception that a memory barrier can be used without any cooperation from your compiler), so to do this analysis we’ll need to look at all of the phases of the GHC compilation chain. Furthermore, we’ll restrict ourselves to monadic reads/writes, to avoid having to wrangle with the can of worms that is laziness.
Here’s GHC’s compilation pipeline in a nutshell:
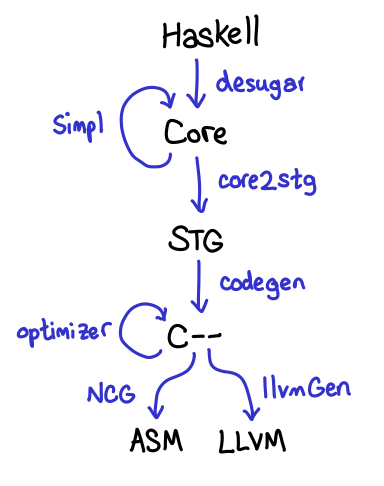
At the very top of the compiler pipeline lie the intermediate languages Core and STG. These will preserve sequential consistency with no trouble, as the ordering of reads and writes is fixed by the use of monads, and preserved throughout the desugaring and optimization passes: as far as the optimizer is concerned, the primitive operations which implement read/write are complete black boxes. In fact, monads will over-sequentialize in many cases! (It is worth remarking that rewrite rules and GHC plugins could apply optimizations which do not preserve the ordering imposed by monads. Of course, both of these facilities can be used to also change the meaning of your program entirely; when considering a memory model, these rules merely have a higher burden of correctness.)
The next step of the pipeline is a translation into C–, a high-level assembly language. Here, calls to primitive operations like readMutVar# and writeMutVar# are translated into actual memory reads and writes in C–. Importantly, the monadic structure that was present in Core and STG is now eliminated, and GHC may now apply optimizations which reorder reads and writes. What actually occurs is highly dependent on the C– that is generated, as well as the optimizations that GHC applies, and C– has no memory model, so we cannot appeal to even that.
This being said, a few things can be inferred from a study of the optimization passes that GHC does implement:
- GHC reserves the right to reorder stores: the
WriteBarriermach-op (NB: not available from Haskell!) is defined to prevent future stores from occurring before preceding stores. In practice, GHC has not implemented any C– optimizations which reorder stores, so if you have a story for dealing with the proceeding stages of the pipeline, you can dangerously assume that stores will not be reordered in this phase. - GHC reserves the right to reorder loads, and does so extensively. One of the most important optimizations we perform is a sinking pass, where assignments to local variables are floated as close to their use-sites as possible. As of writing, there is no support for read barrier, which would prevent this floating from occurring.
There are a few situations where we happen to avoid read reordering (which may be dangerously assumed):
- Reads don’t seem to be reordered across foreign primops (primops defined using the
foreign primkeywords). This is because foreign primops are implemented as a jump to another procedure (the primop), and there are no inter-procedural C– optimizations at present. - Heap reads don’t seem to be reordered across heap writes. This is because we currently don’t do any aliasing analysis and conservatively assume the write would have clobbered the read. (This is especially dangerous to assume, since you could easily imagine getting some aliasing information from the frontend.)
Finally, the C– is translated into either assembly (via the NCG—N for native) or to LLVM. During translation, we convert the write-barrier mach-op into an appropriate assembly instruction (no-op on x86) or LLVM intrinsic (sequential consistency barrier); at this point, the behavior is up to the memory model defined by the processor and/or by LLVM.
It is worth summarizing the discussion here by comparing it to the documentation at Data.IORef, which gives an informal description of the IORef memory model:
In a concurrent program, IORef operations may appear out-of-order to another thread, depending on the memory model of the underlying processor architecture…The implementation is required to ensure that reordering of memory operations cannot cause type-correct code to go wrong. In particular, when inspecting the value read from an IORef, the memory writes that created that value must have occurred from the point of view of the current thread.
In other words, “We give no guarantees about reordering, except that you will not have any type-safety violations.” This behavior can easily occur as a result of reordering stores or loads. However, the type-safety guarantee is an interesting one: the last sentence remarks that an IORef is not allowed to point to uninitialized memory; that is, we’re not allowed to reorder the write to the IORef with the write that initializes a value. This holds easily on x86, due to the fact that C– does not reorder stores; I am honestly skeptical that we are doing the right thing on the new code generator for ARM (but no one has submitted a bug yet!)
What does it all mean?¶
This dive into the gory internals of GHC is all fine and nice, but what does it mean for you, the prospective implementor of a snazzy new concurrent data structure? There are three main points:
- Without inline foreign primops, you will not be able to convince GHC to emit the fast-path assembly code you are looking for. As we mentioned earlier, foreign primops currently always compile into out-of-line jumps, which will result in a bit of extra cost if the branch predictor is unable to figure out the control flow. On the plus side, any foreign primop call will accidentally enforce the compiler-side write/read barrier you are looking for.
- With inline foreign primops, you will still need make modifications to GHC in order to ensure that optimization passes respect your snazzy new memory barriers. For example, John Lato’s desire for a load-load barrier (the email which kicked off this post) will be fulfilled with no compiler changes by a out-of-line foreign primop, but not by the hypothetical inline foreign primop.
- This stuff is really subtle; see the position paper Relaxed memory models must be rigorous, which argues that informal descriptions of memory models (like this blog post!) are far too vague to be useful: if you want to have any hope of being correct, you must formalize it! Which suggests an immediate first step: give C– a memory model. (This should be a modest innovation over the memory models that C and C++ have recently received.)
For the rest of us, we’ll use STM instead, and be in a slow but compositional and dead-lock free nirvana.
Thanks for taking the time to write this up, and also for your on-list replies. For me specifically, an out-of-line foreign primop will work until there are interprocedural C– optimizations, making this a dangerous approach. If I use an out-of-line foreign no-op, I could even envision LLVM removing it entirely as dead code, thereby foiling my attempt. In the end, only a proper barrier (respected by the compiler and CPU) is really reliable.
IIRC, I think you’re correct that Ryan was a bit disappointed with the performance of atomic-primops, exactly because the foreign primops aren’t inlined. Sadly, I think you’ve shown that just inlining those calls is not entirely straightforward.
Wow, trip down memory lane. I clearly had this better paged in eight years ago when I was also working on the memory model for Fortress. Ironically I think this was around the time that John Dias was interning with us (before he wrote the dependency graph representation used in C– in GHC).
Ultimately, to get memory model right you’ve got to reflect the memory ordering constraints in the dependency graph (or equivalent) that gets built in the compiler back end. And that means plumbing them through. Often the constructs for doing the plumbing turn out to be a bit of a blunt instrument themselves – memory fences are waaay too coarse-grained for simple loads and stores, for example. So it’s much easier to have a finer-grained dependency semantics for individual memory operations so that you don’t need to insert very many hints. That’s really what the algebraic reordering approach was intended to capture – how to turn a sequence of memory operations into a DAG of memory operations which could then be serialized any way the compiler thought was convenient.
Apropos, I found an interesting out-of-date comment about the memory model for IORefs in “Comparing the Performance of Concurrent Linked-List Implementations in Haskell”: