Visualizing range trees
February 26, 2012Range trees are a data structure which lets you efficiently query a set of points and figure out what points are in some bounding box. They do so by maintaining nested trees: the first level is sorted on the x-coordinate, the second level on the y-coordinate, and so forth. Unfortunately, due to their fractal nature, range trees a bit hard to visualize. (In the higher dimensional case, this is definitely a “Yo dawg, I heard you liked trees, so I put a tree in your tree in your tree in your…”) But we’re going to attempt to visualize them anyway, by taking advantage of the fact that a sorted list is basically the same thing as a balanced binary search tree. (We’ll also limit ourselves to two-dimensional case for sanity’s sake.) I’ll also describe a nice algorithm for building range trees.
Suppose that we have a set of points $(x_1, y_1), (x_2, y_2), \cdots (x_n, y_n)$. How do we build a range tree? The first thing we do is build a balanced binary search tree for the x-coordinate (denoted in blue). There are a number of ways we can do this, including sorting the list with your favorite sorting algorithm and then building the BBST from that; however, we can build the tree directly by using quicksort with median-finding, pictured below left.
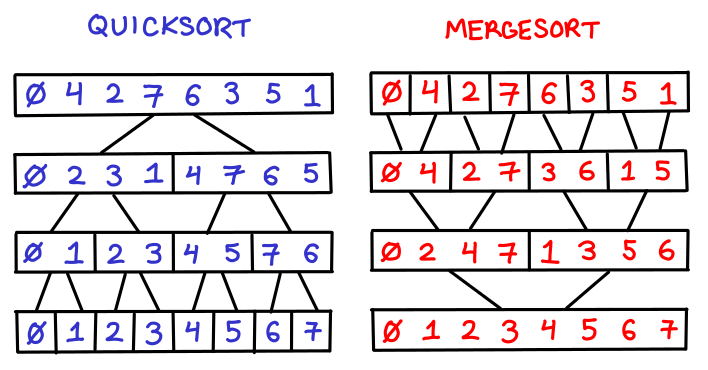
Once we’ve sorted on x-coordinate, we now need to re-sort every x-subtree on the y-coordinates (denoted in red), the results of which will be stored in another tree we’ll store inside the x-subtree. Now, we could sort each list from scratch, but since for any node we’re computing the y-sorted trees of its children, we can just merge them together ala mergesort, pictured above right. (This is where the -1 in $n\lg^{d-1} n$ comes from!)
So, when we create a range-tree, we first quicksort on the x-coordinate, and then mergesort on the y-coordinate (saving the intermediate results). This is pictured below:
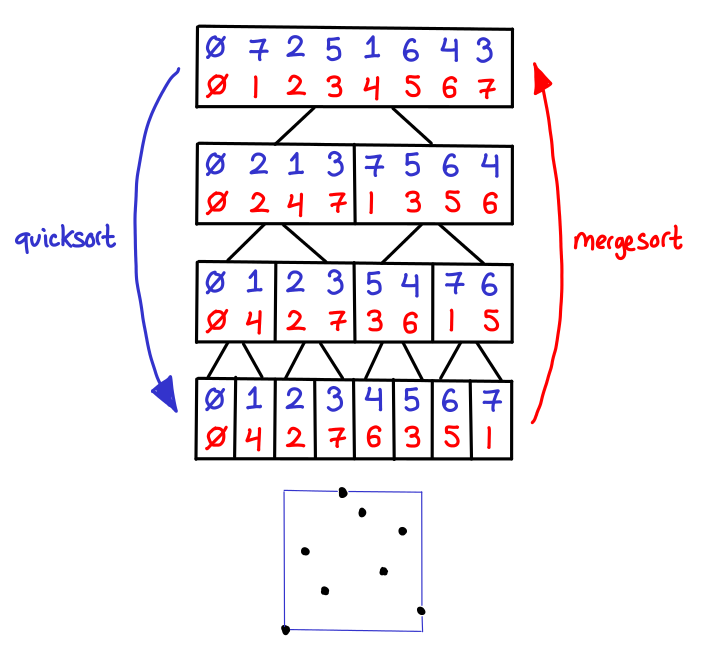
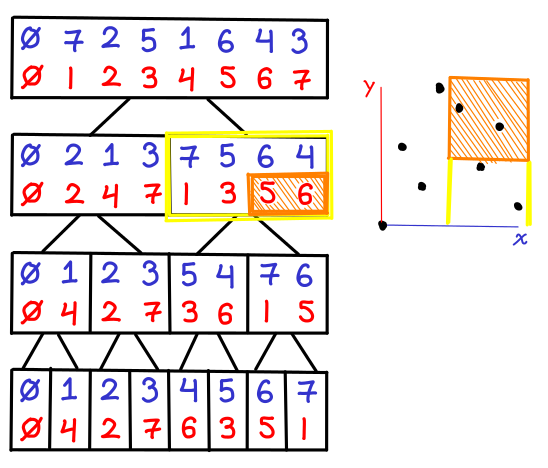
We can interpret this diagram as a range tree as follows: the top-level tree is the x-coordinate BBST, as when we get the leaves we see that all of the points are sorted by x-coordinate. However, the points that are stored inside the intermediate nodes represent the y-coordinate BBSTs; each list is sorted on the y-coordinate, and implicitly represents another BBST. I’ve also thrown in a rendering of the points being held by this range tree at the bottom.
Let’s use this as our working example. If we want to find points between the x-coordinates 1 and 4 inclusive, we search for the leaf containing 1, the leaf containing 4, and take all of the subtrees between this.

What if we want to find points between the y-coordinates 2 and 4 inclusive, with no filtering on x, we can simply look at the BBST stored in the root node and do the range query.
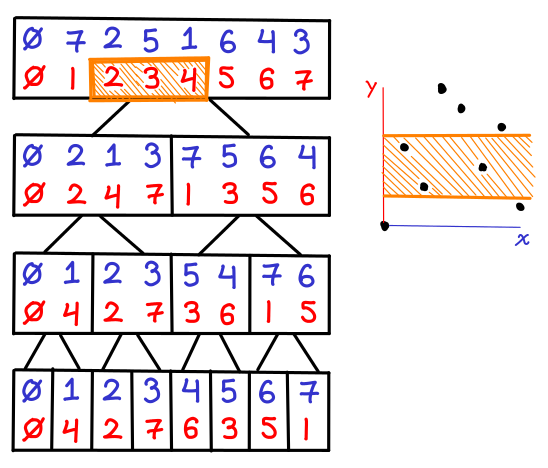
Things are a little more interesting when we actually want to do a bounding box (e.g. (1,2) x (4,4) inclusive): first, we locate all of the subtrees in the x-BBST; then, we do range queries in each of the y-BBSTs.
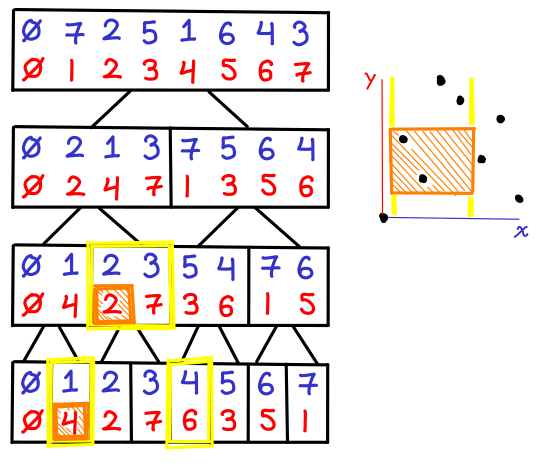
Here is another example (4,4) x (7,7) inclusive. We get lucky this time and only need to check one y-BBST, because the X range directly corresponds to one subtree. In general, however, we will only need to check $O(\lg n)$ subtrees.
It should be easy to see that query time is $O(\lg^2 n)$ (since we may need to perform a 1-D range query on $O(\lg n)$ trees, and each query takes $O(\lg n)$ time). Perhaps less obviously, this scheme only takes up $O(n\lg n)$ space. Furthermore, we can actually get the query time down to $O(\lg n)$, using a trick called fractional cascading. But that’s for another post!
Great post! Neat technique, excellent explanation.
I would love to hear about fractional cascading, too.
Hi,
“between the y-coordinates 3 and 5 inclusive” – shouldn’t it be between 2 and 4?
Just trying to checksum my understanding of this essay.
Thanks!
A few questions:
In “(This is where the -1 in n\lg^{n-1} n comes from!)” did you mean n\lg^{d-1} n ?
In “Perhaps less obviously, this scheme only takes up O(n\lg n)”, do you mean the space requirement?
SonOfLilit: Oops, off by one! It’s fixed now.
Anonymous: Hmm. I don’t know of any implementations off hand; I would have thought Hackage would have one on hand but I don’t see any.
Dhruv: (1) Yes, fixed. (2) Yep, space requirement (also, time to construct)
Edward: Thanks! Looking forward to your post on fractional cascading.
It would be super if your commenting system had a “notify by email on reply” feature and you could post a reply to this post when you do write the promised post on fractional cascading. (yeah, I know of the feed).
i wondered why the blue sequence changes from 0 4 2 7 6 3 5 1 to 0 7 2 5 1 6 4 3 from the first image with the red and blue next to each other, to the subsequent image where they are combined
also in the first image 5 1 are in a box together, was this intentional, or is there a missing box segment between them?
Hello alex,
There’s no reason. I think if I were to do it again, I probably would pick the blue x-coordinates at the top to be the same as the initial example, and the y-coordinates to be different (notice the y-coordinates at the bottom are the same!) When I wrote originally wrote this blog post, I thought setting the x-coordinates at the top to be the quicksort result would be degenerate. But it’s only degenerate in a very elegant way: for any well-formed range tree, a quicksort on X and then a mergesort on Y is the identity operation on the array at the top of the tree. (Alternately, a range tree is the fixpoint of x-quicksort/y-mergesorting.)
There is one good thing about the current presentation choice, which is that there is an initial quick sort that you can do, which just isn’t visible in the diagram. Namely, take the original quicksort order, attach the y-coordinates, and quicksort it. That gives the bottom of the tree; now you have to merge-sort it. In general, you’ll have to do two sorts in order to get a range tree, since you won’t generally get a list of points where the y-coordinates happen to already be sorted!
As for 5 1, the answer is simpler: it’s a typo.