Bugs and Battleships
December 19, 2011
Do you remember your first computer program? When you had finished writing it, what was the first thing you did? You did the simplest possible test: you ran it.
As programs increase in size, so do the amount of possible tests. It’s worth considering which tests we actually end up running: imagine the children’s game Battleship, where the ocean is the space of all possible program executions, the battleships are the bugs that you are looking for, and each individual missile you fire is a test you run (white if the test passes, red if the test fails.) You don’t have infinite missiles, so you have to decide where you are going to send them.
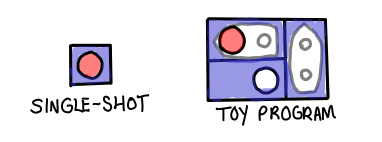
In the case of “your first computer program,” the answer seems pretty obvious: there’s only one way to run the program, only a few cases to test.
But this fantasy is quickly blown away by an encounter with real software. Even if your program has no inputs, hardware, operating system, development environment, and other environmental factors immediately increase the space of tests. Add explicit inputs and nondeterminism to the application, and you’re looking at the difference between a swimming pool and an ocean.
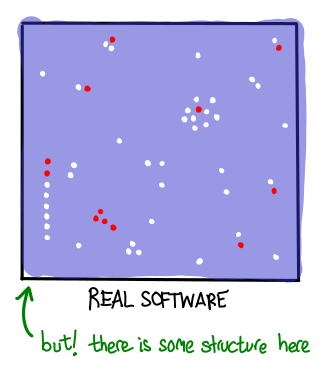
How do we decide what to test? What is our strategy—where do we send more missiles, where do we send less? Different testing strategies result in different distributions of tests on the space of all possible executions. Even though we may not be thinking about the distribution of test cases when we write up tests or run the whole system in an integration test, different test strategies result in different coverage.
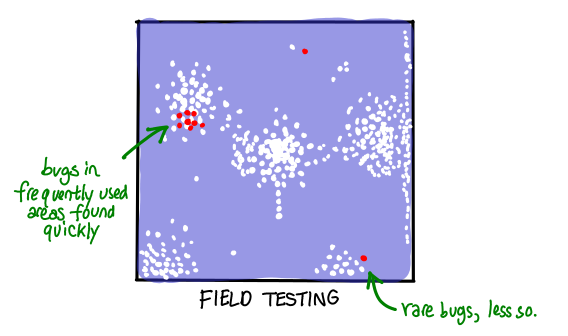
For example, you might decide not to do any tests, and rely on your users to give you bug reports. The result is that you will end up with high coverage in frequently used areas of your application, and much less coverage in the rarely used areas. In some sense, this is an optimal strategy when you have a large user base willing to tolerate failure—though anyone who has run into bugs using software in unusual circumstances might disagree!
There is a different idea behind regression testing, where you add an automatic test for any bug that occurred in the past. Instead of focusing coverage on frequently used area, a regression test suite will end up concentrated on “tricky” areas of the application, the areas where the most bugs have been found in the past. The hypothesis behind this strategy is that regions of code that historically had bugs are more likely to have bugs in the future.
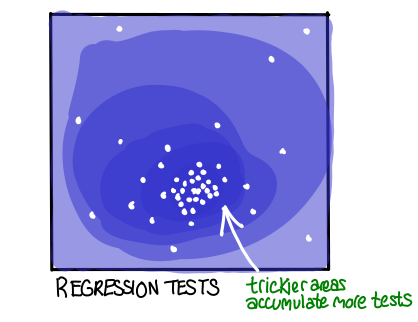
You might even have some a priori hypotheses about where bugs in applications occur; maybe you think that boundary cases in the application are most likely to have bugs. Then you might reasonable focus your testing efforts on those areas on the outset.

Other testing strategies might focus specifically on the distribution of tests. This is especially important when you are concerned about worst-case behavior (e.g. security vulnerabilities) as opposed to average-case behavior (ordinary bugs.) Fuzz testing, for example, involves randomly spattering the test space without any regard to such things as usage frequency: the result is that you get a lot more distribution on areas that are rarely used and don’t have many discovered bugs.

You might notice, however, that while fuzz testing changes the distribution of tests, it doesn’t give any guarantees. In order to guarantee that there aren’t any bugs, you’d have to test every single input, which in modern software engineering practice is impossible. Actually, there is a very neat piece of technology called the model checker, designed specifically with all manner of tricks for speed to do this kind of exhaustive testing. For limited state spaces, anyway—there are also more recent research projects (e.g. Alloy) which perform this exhaustive testing, but only up to a certain depth.

Model checkers are “dumb” in some sense, in that they don’t really understand what the program is trying to do. Another approach we might take is to take advantage of the fact that we know how our program works, in order to pick a few, very carefully designed test inputs, which “generalize” to cover the entire test space. (We’ll make this more precise shortly.)
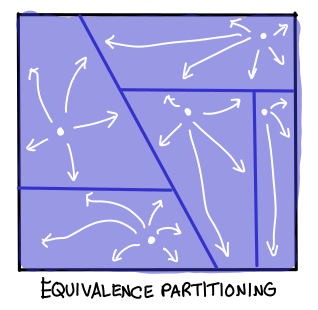
The diagram above is a bit misleading, however: test-cases rarely generalize that readily. One might even say that the ability to generalize behavior of specific tests to the behavior of the program is precisely what distinguishes a good program from a bad one. A bad program is filled with many, many different cases, all of which must be tested individually in order to achieve assurance. A good program is economical in its cases, it tries to be as complex as the problem it tries to solve, and no more.
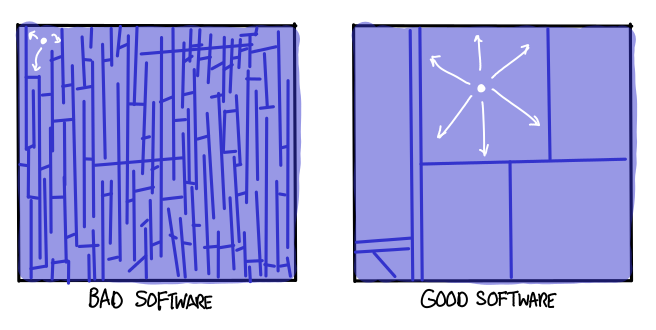
What does it mean to say that a test-case generalizes? My personal belief is that chunks of the test input space which are said to be equivalent to each other correspond to a single case, part of a larger mathematical proof, which can be argued in a self-contained fashion. When you decompose a complicated program into parts in order to explain what it does, each of those parts should correspond to an equivalence partition of the program.
The corollary of this belief is that good programs are easy to prove correct.
This is a long way from “running the program to see if it works.” But I do think this is a necessary transition for any software engineer interested in making correct and reliable software (regardless of whether or not they use any of the academic tools like model checkers and theorem provers which take advantage of this way of thinking.) At the end of the day, you will still need to write tests. But if you understand the underlying theory behind the distributions of tests you are constructing, you will be much more effective.
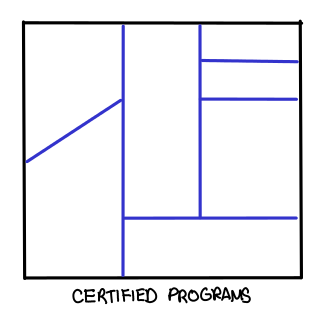
Postscript. The relationship between type checking and testing is frequently misunderstood. I think this diagram sums up the relationship well:
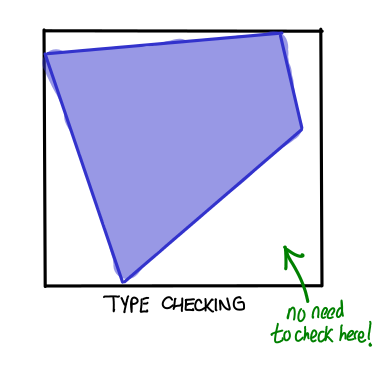
Types eliminate certain regions of bugs and fail to affect others. The idea behind dependent types is to increase these borders until they cover all of the space, but the benefits are very tangible even if you only manage to manage a subset of the test space.

This work is licensed under a Creative Commons Attribution-ShareAlike 3.0 Unported License.
At first I thought your diagrams were battleship layouts. Heheh.
Looking at your last diagram, is the conclusion of the matter to employ types and type checking to increase testing efficiency?
This was a great read.
That said, this essay said almost nothing about “feature testing”. (Feature testing is not focused on “finding bugs”, it’s about dealing with cost/benefit issues, it’s about sketching out the design, and is about tracking who to be discussing priorities with, when things need to be changing. Features are not uniformly valuable, and have costs.)