Association maps in mit-scheme
April 21, 2010I recently some did some benchmarking of persistent data structures in mit-scheme for my UROP. There were a few questions we were interested in:
- For what association sizes does a fancier data structure beat out your plain old association list?
- What is the price of persistence? That is, how many times slower are persistent data structures as compared to your plain old hash table?
- What is the best persistent data structure?
These are by no means authoritative results; I still need to carefully comb through the harness and code for correctness. But they already have some interesting implications, so I thought I’d share. The implementations tested are:
- assoc, association lists
- hamt, hash array mapped tries (hand-implemented, using 26-bit fixnums)
- hash-table, hash tables
- prb-tree, persistent red-black trees (hand-implemented)
- wt-tree, weight-balanced trees
All implementations use eq? for key comparison.
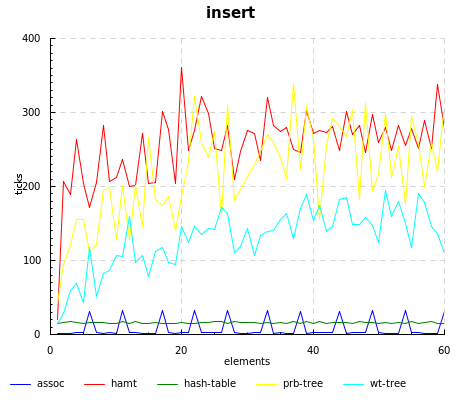
Unsurprisingly, assoc beats out everyone else, since all it has to do is a simple cons. However, there are some strange spikes at regular intervals, which I am not sure of the origin; it might be the garbage collector kicking in.
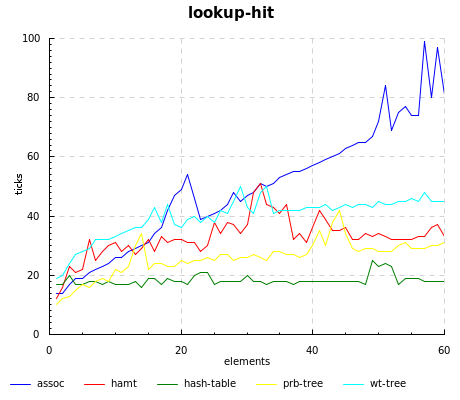
Of course, you pay back the cheap updates in assoc with a linear lookup time; the story also holds true for weight-balanced trees, which have fast inserts but the slowest lookups.
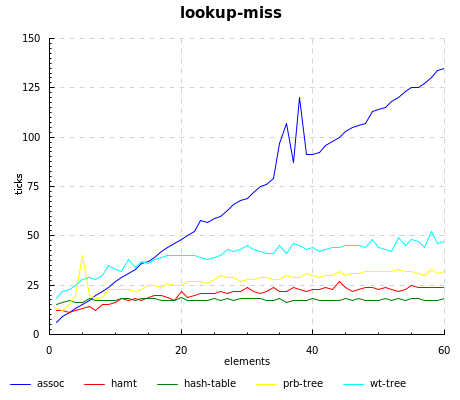
The hamt really flies when the key isn’t present, even beating out hash-tables until 15 elements or so.
Source code for running the benchmarks, our home-grown implementations, and graphing can be found at the scheme-hamt repository.
2 Comments